






训练集假设只有4张图片

因为我们需要分类的数据训练集非常少,所以不能用传统的神经网络训练方式来训练,因为训练不起来,所以引入few-shot Learning 的概念
few-shot learning 的目的并不是训练一个网络泛化到测试集,而是让网络自己学会学习,分辨事物的异同
Few-Shot learning
- 术语一:
support set带标签的图片,与训练集的区别: 训练集的图片很多,而support set 每一类只包含一两张带标签的图片,只能在做预测的时候提供一些额外信息
如:

-
术语二:Query
需要判别的图片,该图片可能不在神经网络训练的时候出现,,即神经网络不认识Query中的图片,但是
神经网络假设已经训练出了识别事物的异同,给出Support Set,就能判 别Query中的事物处于哪个类
-
与
Meta Learninig的联系与区别,Few-shot learning 是Meta Learning的一种
-
k-way n-shot Support Set : K-way 代表有k个类别,n-shot 代表每个类别的图片个数

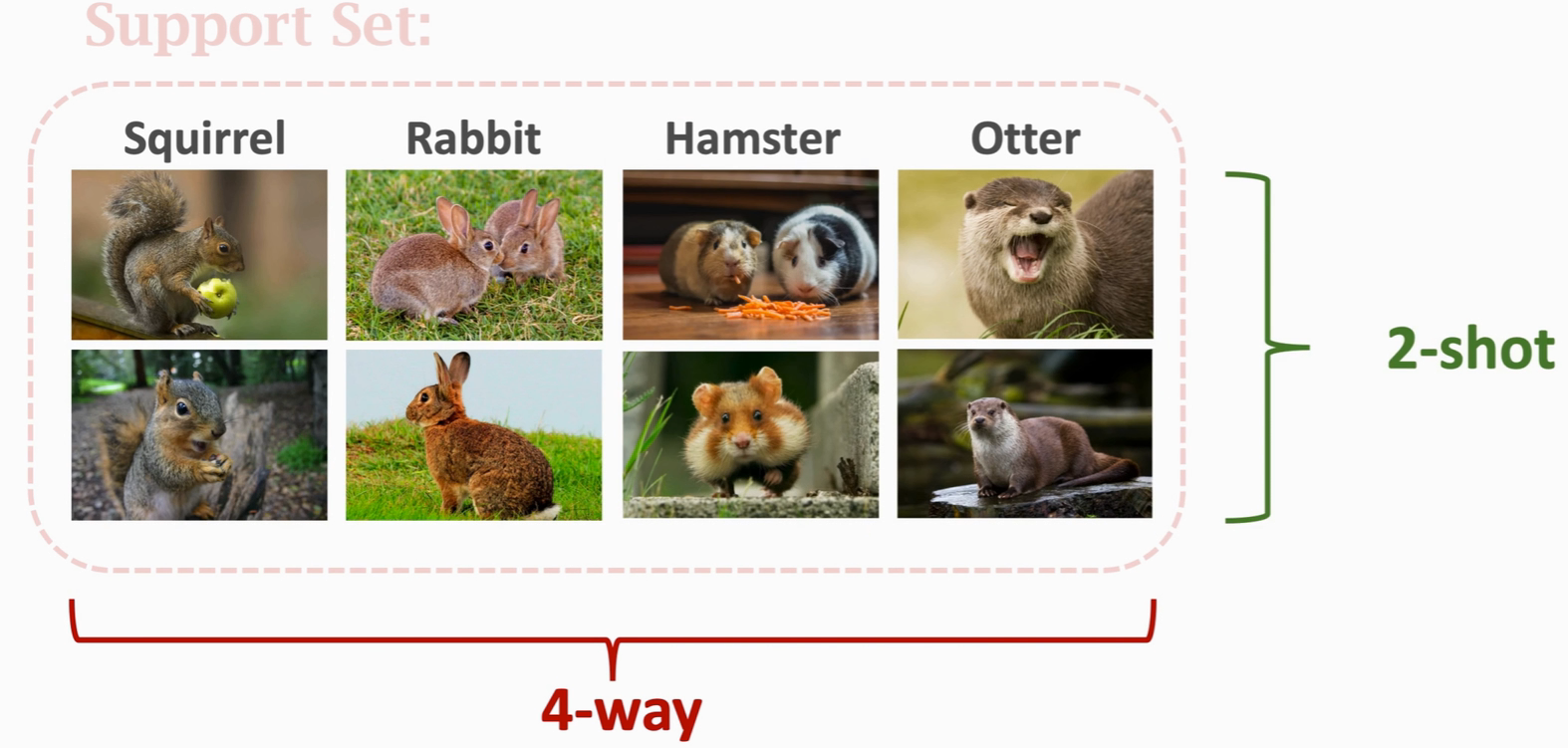
规律:
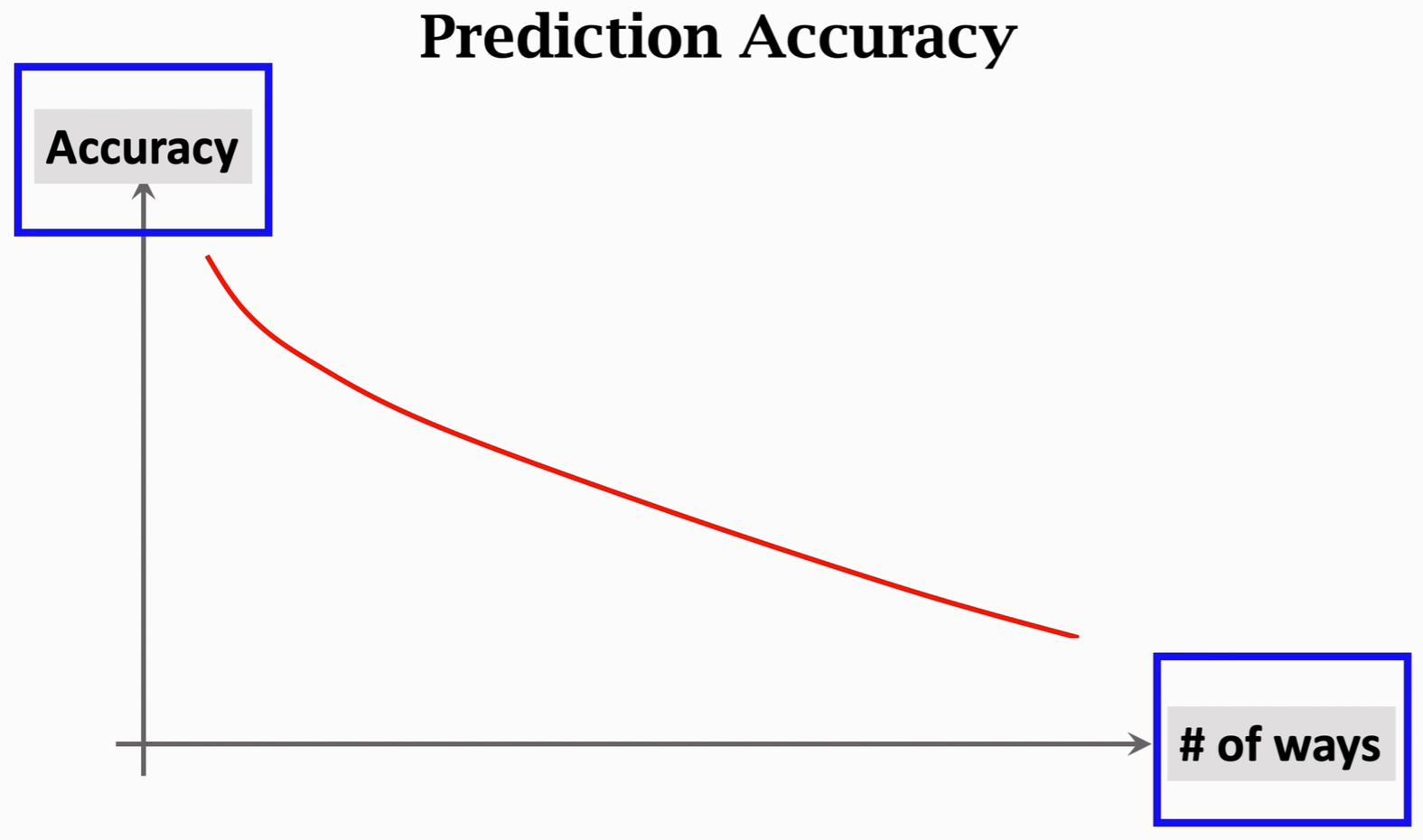
随着种类的增多,准确率呈现下降趋势
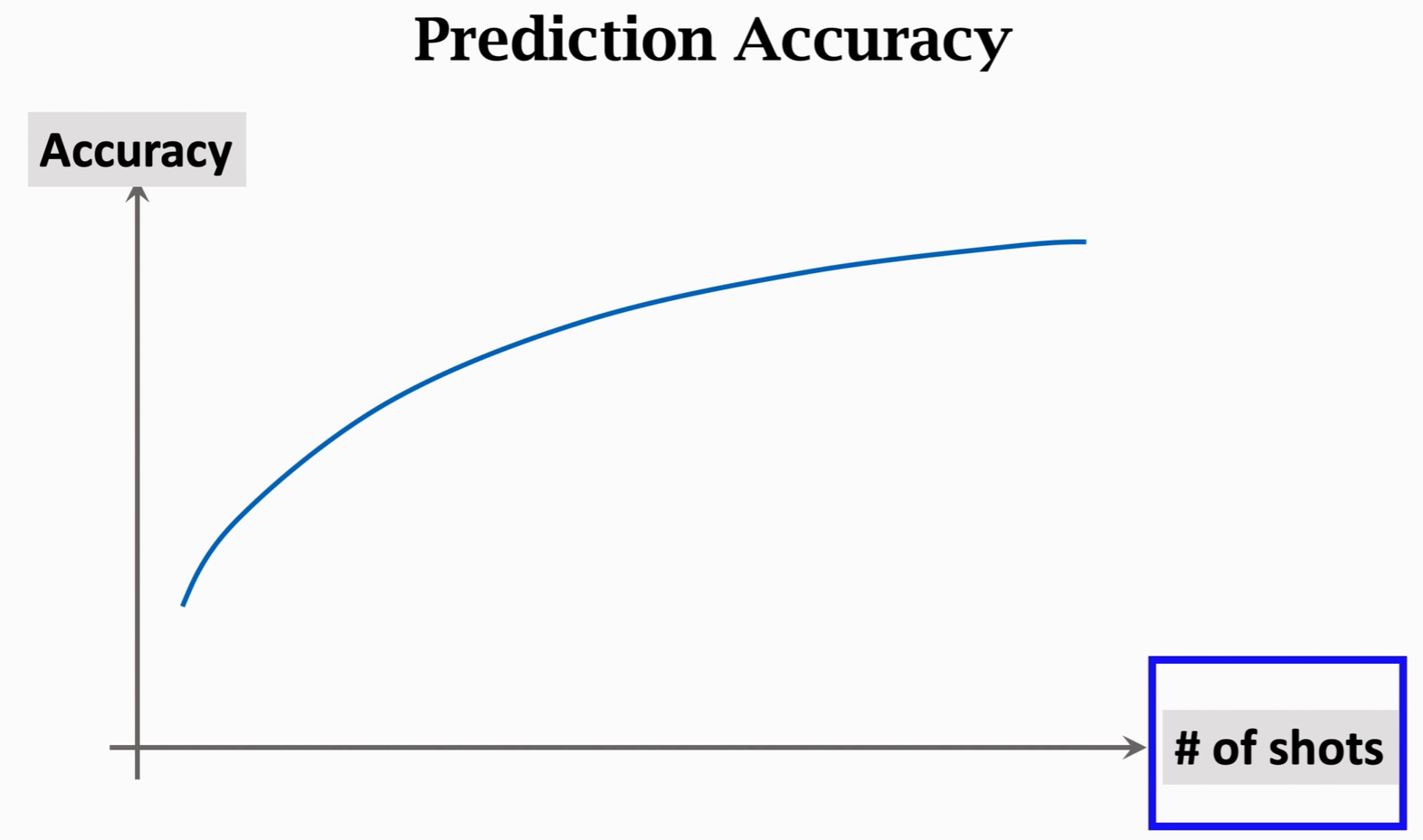
随着每类图片数量的增多,准确率呈现上升趋势
学习Meta Learning的基本思想

假设函数为 sim() , 输入为 x1,x2,x3,那么sim(x1,x2) = 1 ,表示x1和x2两张图片相似,否则不相似。
步骤:
-
从一个很大的数据集里面学习一个相似度函数

-
学到的函数用来做预测,给一个Query图片,用来和Support set 中的图片逐一对比计算相似度

介绍两个公有数据集
-
Omniglot ,类似MNIST , 1600个类,每个类20张图片

-
Mini-ImageNet (84*84 像素)

-















 2567
2567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









