







AI Box | 大语言模型
大语言模型LLMBook.pdf
第一部分 背景与基础知识
第一章 引言
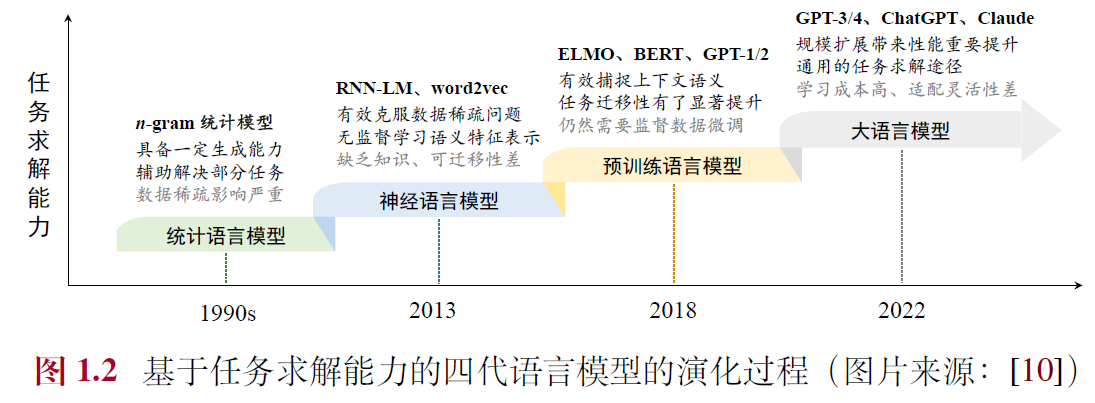
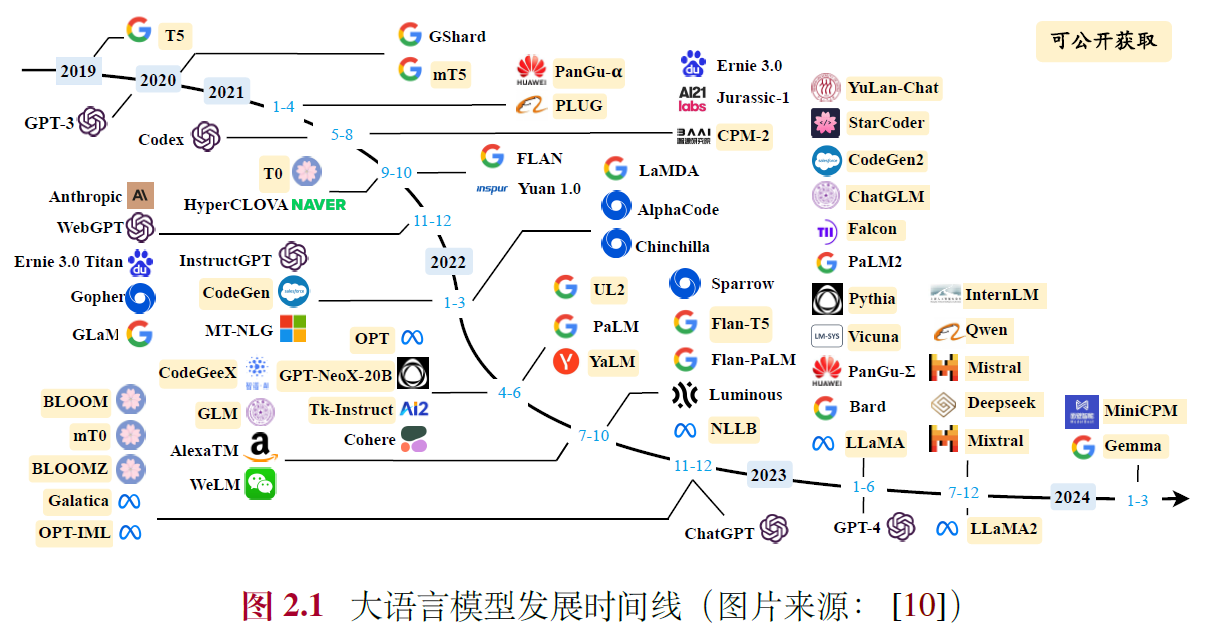
1.1 语言模型的发展历程
- 统计语言模型(Statistical Language Model, SLM):基于马尔可夫假设的具有固定上下文长度𝑛的统计语言模型,被称为𝑛 元(𝑛-gram)语言模型
- 神经语言模型(Neural Language Model, NLM):循环神经网络(Recurrent Neural Networks, RNN),隐特征使用词嵌入模型(Word Embedding),如word2vec
- 预训练语言模型(Pre-trained Language Model, PLM):ELMo双向LSTM,基于自注意力机制(Self-Attention)的Transformer 模型,BERT,GPT-1等
- 大语言模型(Large Language Model, LLM):“扩展法则”(Scaling Law),GPT-3,PaLM,“涌现能力”(Emergent Abilities)
1.2 大语言模型的能力特点
- 具有较为丰富的世界知识:数据量
- 具有较强的通用任务解决能力:多任务学习
- 具有较好的复杂任务推理能力:记忆与推理
- 具有较强的人类指令遵循能力:提示学习
- 具有较好的人类对齐能力:安全性
- 具有可拓展的工具使用能力:搜索引擎与计算器
1.3 大语言模型关键技术概览
- 规模扩展:参数、数据、算力
- 数据工程:采集、清洗、配比
- 高效预训练:3D 并行(数据并行、流水线并行、张量并行)、ZeRO(内存冗
余消除技术),代表框架为DeepSpeed和Megatron-LM
- 能力激发:指令微调和提示策略(上下文学习、思维链提示)
- 人类对齐:“3H对齐标准”,Helpfulness(有用性)、Honesty(诚实性)和Harmlessness(无害性),代表方法为RLHF、DPO
- 工具使用:插件、计算器、搜索引擎
1.4 大语言模型对科技发展的影响
- 自然语言处理:从“解决特定任务”迁移到“如何进一步提升大语言模型的综合能力”
- 信息检索:检索增强的大语言模型以及大语言模型增强的搜索系统
- 计算机视觉:类ChatGPT 的视觉-语言联合对话模型,解决跨模态或多模态任务
- 人工智能赋能的科学研究(AI4Science):数学、化学、物理、生物等多个领域
第二章 基础介绍
2.1 大语言模型的构建过程
2.1.1 大规模预训练
- 预训练:指使用与下游任务无关的大规模数据进行模型参数的初始训练,为模型参数找到一个较好的“初值点”,本质上是在做一个世界知识的压缩,从而能够学习到一个编码世界知识的参数模型,这个模型能够通过解压缩所需要的知识来解决真实世界的任务
- 流程:**准备数据 -> 清洗 -> 词元化(Tokenization) -> 切分成批次(Batch)训练
- 开源模型普遍采用2∼3T规模的词元进行预训练,训练百亿模型至少需要百卡规模的算力集群(如A100 80G)联合训练数月时间;
- 难点:数据如何进行配比、如何进行学习率的调整、如何早期发现模型的异常行为
2.1.2 指令微调与人类对齐
- “指令微调”(也叫做有监督微调,Supervised Fine-tuning, SFT),通过使用任务输入与输出的配对数据进行模型训练,使得语言模型较好地掌握通过问答形式进行任务求解的能力,属于“模仿学习”
- 一般来说,指令微调很难进行知识注入,主要起到激发作用,数据规模仅需数千数万条即可,算力要求也小
- 基于人类反馈的强化学习对齐方法RLHF(Reinforcement Learning from Human Feedback),使用偏好排序数据训练一个符合人类价值观的奖励模型(Reward Model),进行强化学习
2.2 扩展法则
2.2.1 KM扩展法则
- 模型规模(𝑁)、数据规模(𝐷)和计算算力(𝐶)之间的幂律关系(Power-Law Relationship)
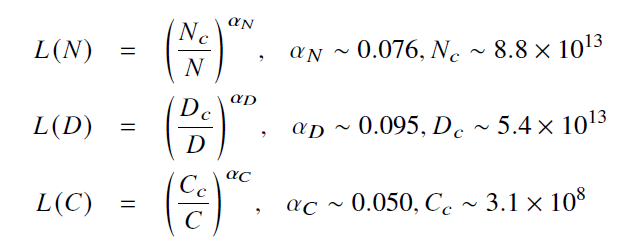
- 𝐿(·) 表示用以nat(以e 为底信息量的自然对数)为单位的交叉熵损失。其中,𝑁𝑐、𝐷𝑐 和𝐶𝑐 分别表示非嵌入参数数量、训练数据数量和实际的算力开销。包括不可约损失(真实数据分布的熵)和可约损失(真实分布和模型分布之间KL 散度的估计),训练只能减少可约损失
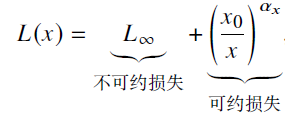
- 说明:模型性能与这三个因素之间存在着较强的依赖关系,可以近似刻画为指数关系。
2.2.2 Chinchilla 扩展法则
- 模型性能的幂律关系
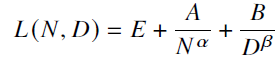
- 𝐸 = 1.69,𝐴 = 406.4,𝐵 = 410.7,𝛼 = 0.34 和𝛽 = 0.28
- 算力资源固定情况下模型规模与数据规模的最优分配方案
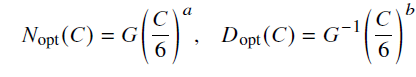
- 其中
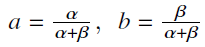 ,𝐺 是由𝐴、𝐵、𝛼 和𝛽 计算得出的扩展系数
,𝐺 是由𝐴、𝐵、𝛼 和𝛽 计算得出的扩展系数 - 经验:数据规模大概是模型参数规模的五倍(现在的工作已经远高于该比例)
2.2.3 关于扩展法则的讨论
- 可预测的扩展(Predictable Scaling):通过较小算力资源可靠地估计较大算力资源投入后的模型性能,如小模型性能或训练方法去预估大模型(配比等),大模型的早期训练性能去预估训练完成的训练性能
- 任务层面的可预测性:扩展法则可预测某些任务的能力(如coding),但是有些会逆向变差或者模型大小超过规模才会出现,如以下的涌现能力,当模型扩展到一定规模时,模型的特定任务性能突然出现显著跃升的趋势,远超过随机水平
2.3 涌现能力
2.3.1 代表性的涌现能力
- 上下文学习(In-context Learning, ICL):在提示中为语言模型提供自然语言指令和多个任务示例(Demonstration),无需显式的训练或梯度更新,仅输入文本就能为测试样本生成预期的输出
- 指令遵循(Instruction Following):大语言模型能够按照自然语言指令来执行对应的任务,可通过指令微调(Instruction Tuning)或监督微调(Supervised Fine-tuning)
- 逐步推理(Step-by-step Reasoning):大语言模型可以利用思维链(Chain-of-Thought, CoT)提示策略来加强推理性能,在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更为可靠的答案
2.3.2 涌现能力与扩展法则的关系
- 扩展法则使用语言建模损失来衡量语言模型的整体性能,整体上展现出了较为平滑的性能提升趋势,具有较好的可预测性,但是指数形式暗示着可能存在的边际效益递减现象
- 涌现能力通常使用任务性能来衡量模型性能,整体上展现出随规模扩展的骤然跃升趋势,不具有可预测性,但是一旦出现涌现能力则意味着模型性能将会产生大幅跃升
2.4 GPT 系列模型的技术演变
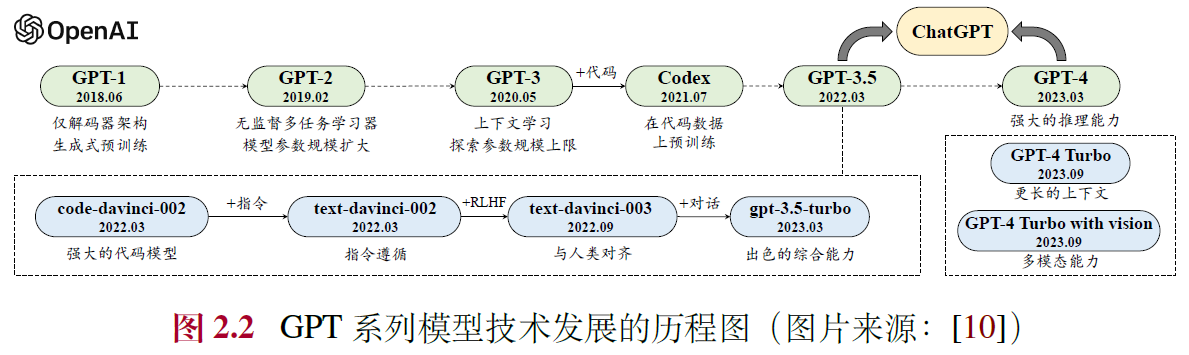
2.4.1 早期探索
- GPT-1:生成式预训练(Generative Pre-Training),同时期的BERT,只保留了Transformer 中的编码器,主要面向自然语言理解任务(Natural Language Understanding, NLU)
- GPT-2:参数规模扩大1.5B,网络数据集WebText,无监督多任务学习范式
2.4.2 规模扩展
- GPT-3:参数规模扩大175B,上下文学习few shot,建立提示学习范式
2.4.3 能力增强
- 代码数据训练:Codex,用GitHub代码训练
- 人类对齐:PPO 算法、InstructGPT的RLHF 算法
2.4.4 性能跃升
- ChatGPT:对话形式训练,插件功能
- GPT-4:扩展到了图文双模态,红队攻击机制
- GPT-4V、GPT-4 Turbo 以及多模态支持模型:更广泛来源、更长上下文、函数调用等
第三章 大语言模型资源
3.1 公开可用的模型检查点或API
3.1.1 公开可用的通用大语言模型检查点
- LLaMA、ChatGLM、Falcon、Baichuan、InternLM、Qwen、Mistral、DeepSeek LLM、Mixtral、Gemma、MiniCPM、YuLan-Chat
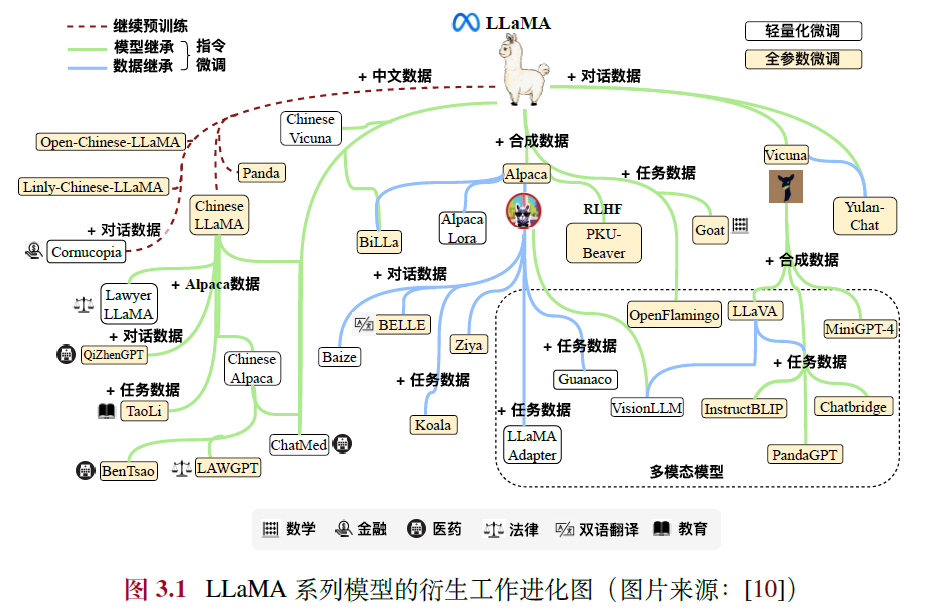
3.1.2 LLaMA 变体系列
- 基础指令:Stanford Alpaca、Vicuna
- 中文指令:Chinese LLaMA、Panda、Open-Chinese-LLaMA、Chinese Alpaca、YuLan-Chat
- 垂域指令:BenTsao(医学)、LAWGPT(法律)、TaoLi(教育)、Goat(数学)、Comucopia(金融)等
- 多模态指令:LLaVA 、MiniGPT4 、InstructBLIP 和PandaGPT
3.1.3 大语言模型的公共API
- 语言模型API:GPT-3.5 Turbo、GPT-4和GPT-4 Turbo
- 文本表征API:embedding 可用于聚类、稠密信息检索等多种下游任务,可以为知识检索以及检索增强生成提供支持
3.2 常用的预训练数据集
3.2.1 网页
- 通用网页数据:Common Crawl、C4(Colossal Clean Crawled Corpus)、CC-Stories、CC-News、REALNEWs、RedPajama-Data、RefinedWeb、WanJuan-CC、WebText、OpenWebText.
- 中文网页数据:ChineseWebText、WanJuan 1.0 Text、WuDaoCorpora Text、SkyPile-150B
3.2.2 书籍
- BookCorpus、Project Gutenberg、arXiv Dataset、S2ORC
3.2.3 维基百科
- Wikipedia
3.2.4 代码
- BigQuery、The Stack、StarCoder
3.2.5 混合型数据集
- The Pile、ROOTS、Dolma
3.3 常用微调数据集
3.3.1 指令微调数据集
- 自然语言处理任务数据集:P3(Public Pool of Prompts)、FLAN
- 日常对话数据集:ShareGPT、OpenAssistant、Dolly
- 合成数据集:Self-Instruct-52K、Alpaca-52K
3.3.2 人类对齐数据集
- HH-RLHF、SHP、PKU-SafeRLHF、Stack Exchange Preferences、Sandbox Alignment Data、CValues
3.4 代码库资源
3.4.1 Hugging Face 开源社区
- Transformers、Datasets、Accelerate
3.4.2 DeepSpeed
- DeepSpeed-MII、DeepSpeed-Chat.















 3854
3854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









