







目录
2022.4.30
我们需要通过一些新的实验数据来 评估(evaluation)模型的 泛化性能(generalization performance),如果新的实验数据应用到到这个模型中损失值越小,那么这个模型的泛化性能就越好,反之就越差。下面的demo中我们也会看到怎么评估模型。
使用LinearRegressor
前面我们构建了一个线性模型,通过训练得到一个线性回归方程。tf.estimator中也提供了线性回归的训练模型tf.estimator.LinearRegressor,下面的代码就是使用LinearRegressor训练并评估模型的方法:
# 我们会用到NumPy来处理各种训练数据
import numpy as np
import tensorflow as tf
# 创建一个特征向量列表,该特征列表里只有一个特征向量,
# 该特征向量为实数向量,只有一个元素的数组,且该元素名称为 x,
# 我们还可以创建其他更加复杂的特征列表
feature_columns = [tf.feature_column.numeric_column("x", shape=[1])]
# 创建一个LinearRegressor训练器,并传入特征向量列表
estimator = tf.estimator.LinearRegressor(feature_columns=feature_columns)
# 保存训练用的数据
x_train = np.array([1., 2., 3., 6., 8.])
y_train = np.array([4.8, 8.5, 10.4, 21.0, 25.3])
# 保存评估用的数据
x_eavl = np.array([2., 5., 7., 9.])
y_eavl = np.array([7.6, 17.2, 23.6, 28.8])
# 用训练数据创建一个输入模型,用来进行后面的模型训练
# 第一个参数用来作为线性回归模型的输入数据
# 第二个参数用来作为线性回归模型损失模型的输入
# 第三个参数batch_size表示每批训练数据的个数
# 第四个参数num_epochs为epoch的次数,将训练集的所有数据都训练一遍为1次epoch
# 低五个参数shuffle为取训练数据是顺序取还是随机取
train_input_fn = tf.estimator.inputs.numpy_input_fn(
{
"x": x_train}, y_train, batch_size=2, num_epochs=None, shuffle=True)
# 再用训练数据创建一个输入模型,用来进行后面的模型评估
train_input_fn_2 = tf.estimator.inputs.numpy_input_fn(
{
"x": x_train}, y_train, batch_size=2, num_epochs=1000, shuffle=False)
# 用评估数据创建一个输入模型,用来进行后面的模型评估
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
{
"x": x_eavl}, y_eavl, batch_size=2, num_epochs=1000, shuffle=False)
# 使用训练数据训练1000次
estimator.train(input_fn=train_input_fn, steps=1000)
# 使用原来训练数据评估一下模型,目的是查看训练的结果
train_metrics = estimator.evaluate(input_fn=train_input_fn_2)
print("train metrics: %r" % train_metrics)
# 使用评估数据评估一下模型,目的是验证模型的泛化性能
eval_metrics = estimator.evaluate(input_fn=eval_input_fn)
print("eval metrics: %s" % eval_metrics)
运行上面的代码输出为:
train metrics: {
'loss': 1.0493528, 'average_loss': 0.52467638, 'global_step': 1000}
eval metrics: {
'loss': 0.72186172, 'average_loss': 0.36093086, 'global_step': 1000}
评估数据的loss比训练数据还要小,说明我们的模型泛化性能很好。
2022.5.2
数据流图(Dataflow Graph)
数据流是一种常用的并行计算编程模型,数据流图是由节点(nodes)和线(edges)构成的有向图:
- 节点(nodes) 表示计算单元,也可以是输入的起点或者输出的终点
- 线(edges) 表示节点之间的输入/输出关系
在 TensorFlow 中,每个节点都是用 tf.Tensor的实例来表示的,即每个节点的输入、输出都是Tensor,如下图中 Tensor 在 Graph 中的流动,形象的展示 TensorFlow 名字的由来
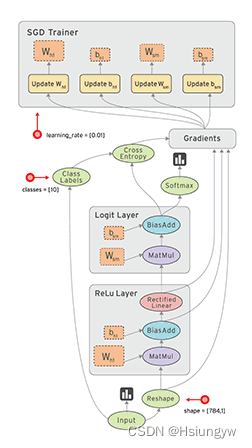
TensorFlow 中的数据流图有以下几个优点:
- 可并行 计算节点之间有明确的线进行连接,系统可以很容易的判断出哪些计算操作可以并行执行
- 可分发 图中的各个节点可以分布在不同的计算单元(CPU、 GPU、 TPU等)或者不同的机器中,每个节点产生的数据可以通过明确的线发送的下一个节点中
- 可优化 TensorFlow 中的 XLA 编译器可以根据数据流图进行代码优化,加快运行速度
可移植 数据流图的信息可以不依赖代码进行保存,如使用Python创建的图,经过保存后可以在C++或Java中使用
Sesssion
我们在Python中需要做一些计算操作时一般会使用NumPy,NumPy在做矩阵操作等复杂的计算的时候会使用其他语言(C/C++)来实现这些计算逻辑,来保证计算的高效性。但是频繁的在多个编程语言间切换也会有一定的耗时,如果只是单机操作这些耗时可能会忽略不计,但是如果在分布式并行计算中,计算操作可能分布在不同的CPU、GPU甚至不同的机器中,这些耗时可能会比较严重。
TensorFlow 底层是使用C++实现,这样可以保证计算效率,并使用 tf.Session类来连接客户端程序与C++运行时。上层的Python、Java等代码用来设计、定义模型,构建的Graph,最后通过tf.Session.run()方法传递给底层执行。
构建计算图
上面介绍的是 TensorFlow 和 Graph 的概念,下面介绍怎么用 Tensor 构建 Graph。
Tensor 即可以表示输入、输出的端点,还可以表示计算单元,如下的代码创建了对两个 Tensor 执行 + 操作的 Tensor:
import tensorflow as tf
# 创建两个常量节点
node1 = tf.constant(3.2)
node2 = tf.constant(4.8)
# 创建一个 adder 节点,对上面两个节点执行 + 操作
adder = node1 + node2
# 打印一下 adder 节点
print(adder)
# 打印 adder 运行后的结果
sess = tf.Session()
print(sess.run(adder))
上面print的输出为:
Tensor("add:0", shape=(), dtype=float32)
8.0
上面使用tf.constant()创建的 Tensor 都是常量,一旦创建后其中的值就不能改变了。有时我们还会需要从外部输入数据,这时可以用tf.placeholder 创建占位 Tensor,占位 Tensor 的值可以在运行的时候输入。如下就是创建占位 Tensor 的例子:
import tensorflow as tf
# 创建两个占位 Tensor 节点
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
# 创建一个 adder 节点,对上面两个节点执行 + 操作
adder_node = a + b
# 打印三个节点
print(a)
print(b)
print(adder)
# 运行一下,后面的 dict 参数是为占位 Tensor 提供输入数据
sess = tf.Session()
print(sess.run(adder, {
a: 3, b: 4.5}))
print(sess.run(adder, {
a: [1, 3], b: [2, 4]}))
上面代码的输出为:
Tensor("Placeholder:0", dtype=float32)
Tensor("Placeholder_1:0", dtype=float32)
Tensor("add:0", dtype=float32)
7.5
[ 3. 7.]
我们还可以添加其他操作构建复杂的 Graph
# 添加×操作
add_and_triple = adder * 3.
print(sess.run(add_and_triple, {
a: 3, b: 4.5}))
上面的输出为
22.5
TensorFlow 高级训练模型
tf.estimator是TensorFlow提供的高级库,提供了很多常用的训练模型,可以简化机器学习中的很多训练过程,如:
运行训练循环
运行评估循环
管理训练数据集
评估模型
前面的demo中我们构建了一个线性模型,通过使用一组实验数据训练我们的线性模型,我们得到了一个自认为损失最小的最优模型,根据训练结果我们的最优模型可以表示为下面的方程:
y=2.98x+2.07
y=2.98x+2.07
2022.5.3
Deep Label Distribution Learning with Label Ambiguity 论文阅读
摘要:CNN在多种视觉识别任务上取得了很好的识别性能,大量的带标记的训练集是CNN成功的重要因素。然而,在一些领域(如年龄估计,头部姿态估计,多标签分类和语义分割等)很难获得有准确标记的足够的训练图像;幸运的是,标签之间有模糊信息(ambiguous information)。
提出的DLDL(Deep Label Distribution Learning) 方法有效的在特征学习和分类中利用了标签模糊(label ambiguity),它有助于防止训练集较小时的网络过拟合。
LDL过程分两步:
1.从图像中提取特征(learning the visual representations/feature learning)
2.利用特征和对应的标记分布LD,学习特征和LD之间的映射关系(classifier learning)
现有的传统LDL方法的问题:
these methods are suboptimal because they only utilize the correlation of neighboring labels in classifier learning, but not in learning the visual representations
Deep ConvNets
优:have natural advantages in feature learning
缺:requires a lot of images
缺:cannot utilize the label ambiguity information
论文关注点:how to exploit the label ambiguity in deep ConvNet
DLDL Apporoach
idea: we expect high correlation among input images with similar output.
DLDL quantizes the range of possible y values into several labels.
如何利用label ambiguity?
By estimating an entire label distribution, the deep learning machine is forced to take care of the ambiguity among labels.
网络的输出(目标函数)为标记分布(LD,label distiribution),为了使预测的输出和真实的标记分布接近,网络会不断对自身weights,bias等参数进行调整,以达到预测和真值相近。在网络训练过程中,网络的最终目的真实LD,以此为目标,自然考虑了标记间的模糊性。
具体做法:
给定一个输入X,和其label distribution y y y, 我们假设 x x x 是 the activation of the last fully connected layer 的输出, 首先使用softmax 得到预测的概率分布 y ’ y’ y’:
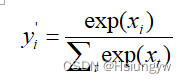
给定一个训练序列 D D D,DLDL的目标是使得神经网络的预测 y ’ y’ y’ 与 y y y 相似,那么衡量这个相似性的标准这里采用了 KL散度,则我们的训练目标是:
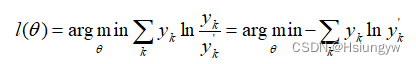
2022.5.4
TensorFlow 高级训练模型
tf.estimator是TensorFlow提供的高级库,提供了很多常用的训练模型,可以简化机器学习中的很多训练过程,如:
- 运行训练循环
- 运行评估循环
- 管理训练数据集
评估模型
前面的demo中我们构建了一个线性模型,通过使用一组实验数据训练我们的线性模型,我们得到了一个自认为损失最小的最优模型,根据训练结果我们的最优模型可以表示为下面的方程:
y=2.98x+2.07
y=2.98x+2.07
但是这个我们自认为的最优模型是否会一直是最优的?我们需要通过一些新的实验数据来 评估(evaluation)模型的 泛化性能(generalization performance),如果新的实验数据应用到到这个模型中损失值越小,那么这个模型的泛化性能就越好,反之就越差。下面的demo中我们也会看到怎么评估模型。
使用LinearRegressor
前面我们构建了一个线性模型,通过训练得到一个线性回归方程。tf.estimator中也提供了线性回归的训练模型tf.estimator.LinearRegressor,下面的代码就是使用LinearRegressor训练并评估模型的方法:
# 我们会用到NumPy来处理各种训练数据
import numpy as np
import tensorflow as tf
# 创建一个特征向量列表,该特征列表里只有一个特征向量,
# 该特征向量为实数向量,只有一个元素的数组,且该元素名称为 x,
# 我们还可以创建其他更加复杂的特征列表
feature_columns = [tf.feature_column.numeric_column("x", shape=[1])]
# 创建一个LinearRegressor训练器,并传入特征向量列表
estimator = tf.estimator.LinearRegressor(feature_columns=feature_columns)
# 保存训练用的数据
x_train = np.array([1., 2., 3., 6., 8.])
y_train = np.array([4.8, 8.5, 10.4, 21.0, 25.3])
# 保存评估用的数据
x_eavl = np.array([2., 5., 7., 9.])
y_eavl = np.array([7.6, 17.2, 23.6, 28.8])
# 用训练数据创建一个输入模型,用来进行后面的模型训练
# 第一个参数用来作为线性回归模型的输入数据
# 第二个参数用来作为线性回归模型损失模型的输入
# 第三个参数batch_size表示每批训练数据的个数
# 第四个参数num_epochs为epoch的次数,将训练集的所有数据都训练一遍为1次epoch
# 低五个参数shuffle为取训练数据是顺序取还是随机取
train_input_fn = tf.estimator.inputs.numpy_input_fn(
{
"x": x_train}, y_train, batch_size=2, num_epochs=None, shuffle=True)
# 再用训练数据创建一个输入模型,用来进行后面的模型评估
train_input_fn_2 = tf.estimator.inputs.numpy_input_fn(
{
"x": x_train}, y_train, batch_size=2, num_epochs=1000, shuffle=False)
# 用评估数据创建一个输入模型,用来进行后面的模型评估
eval_input_fn = tf.estimator.inputs.numpy_input_fn(
{
"x": x_eavl}, y_eavl, batch_size=2, num_epochs=1000, shuffle=False)
# 使用训练数据训练1000次
estimator.train(input_fn=train_input_fn, steps=1000)
# 使用原来训练数据评估一下模型,目的是查看训练的结果
train_metrics = estimator.evaluate(input_fn=train_input_fn_2)
print("train metrics: %r" % train_metrics)
# 使用评估数据评估一下模型,目的是验证模型的泛化性能
eval_metrics = estimator.evaluate(input_fn=eval_input_fn)
print("eval metrics: %s" % eval_metrics)
运行上面的代码输出为:
train metrics: {
'loss': 1.0493528, 'average_loss': 0.52467638, 'global_step': 1000}
eval metrics: {
'loss': 0.72186172, 'average_loss': 0.36093086, 'global_step': 1000}
评估数据的loss比训练数据还要小,说明我们的模型泛化性能很好。
2022.5.4-5.6、5.10-5.11
Label Distribution Learning with Label Correlations on Local Samples 论文阅读
主要想法
论文利用局部样本上的标签相关性,提出了两种新的标签分布学习算法,分别称为GD-LDL-SCL和Adam-LDL-SCL。为了利用局部样本上的标签相关性,对局部样本的影响进行编码,并基于不同的聚类局部样本,设计一个局部相关向量作为每个实例的附加特征。然后,可以通过同时利用原始特征和附加特征来预测一个不可见实例的标签分布。
框架
c i c_i ci:局部相关向量(每个局部样本对目标样本的影响)
利用最大熵模型提出的预测模型:
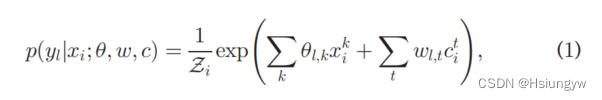
其中 Z i = ∑ l e x p ( ∑ k θ l , k x i k + ∑ t w l , t c i t ) \mathcal{Z}_i = \sum_l exp (\sum_k \theta_{l, k}x_i^k+\sum_tw_{l,t}c_i^t) Zi=∑lexp(∑kθl,kxik+∑twl,tcit), θ \theta θ 表示原始特征的系数矩阵, w w w 表示附加特征的系数矩阵, c i t c_i^t cit 表示第t个集群对 x i x_i xi 的影响。
为了将局部相关影响与全局判别拟合结合成一个统一的框架,优化以下目标函数:
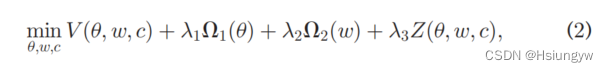
其中 V V V 是损失函数,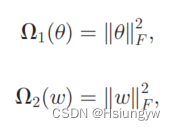 ,采用范数为正则化器。
,采用范数为正则化器。
论文采用KL散度作为基本损失函数:
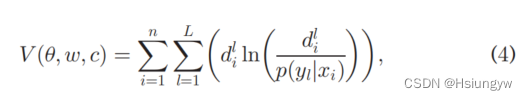
n为训练集个数,L为标签个数。
具体步骤
首先使用k-means进行聚类。论文使用聚类中心来表示聚类,即局部样本。计算相应集群中心的标签分布:
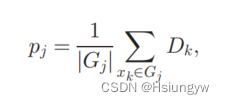
∣ G j ∣ |G_j| ∣Gj∣ 表示其中的实例数。例如 x i x_i xi,定义 c j i c_{ji} cji 来衡量 G j G_j Gj 对 x i x_i xi 的局部影响。很容易观察到, D i D_i Di 和 p j p_j pj 越相似, x i x_i xi 与 G j G_j Gj 实例的相关性可能性越大,说明 c j i c_{ji} cji 的值越大。
采用欧氏距离来度量聚类中心与实例之间的相关性,惩罚项定义如下:
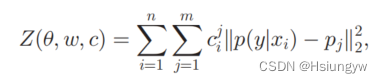
最终的到的优化问题为:
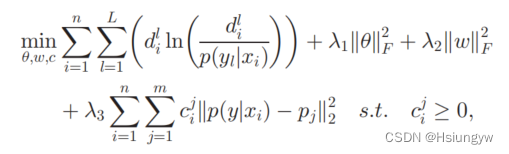
上述公式具有不等式约束,因此使用内点方法将其转换为无约束问题:
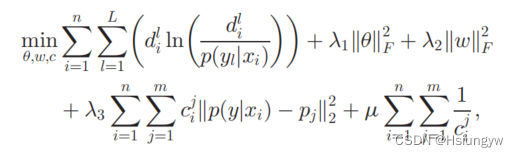
μ \mu μ 表示惩罚因子, ∑ i = 1 n ∑ j = 1 m 1 c i j \sum_{i=1}^n\sum_{j=1}^m\frac{1}{c_i^j} ∑i=1n∑j=1mci
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









