






一、神经网络

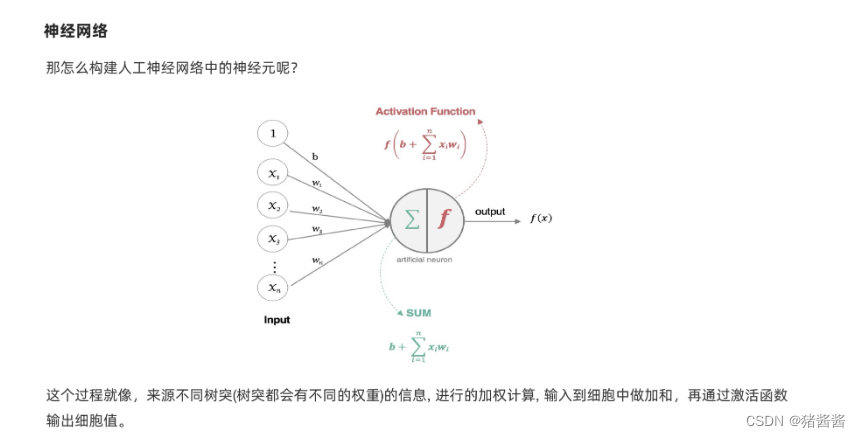
上图表示 数据传输进来 算出所有特征和权重的乘积之和 再进过激活函数进一步拟合得到output
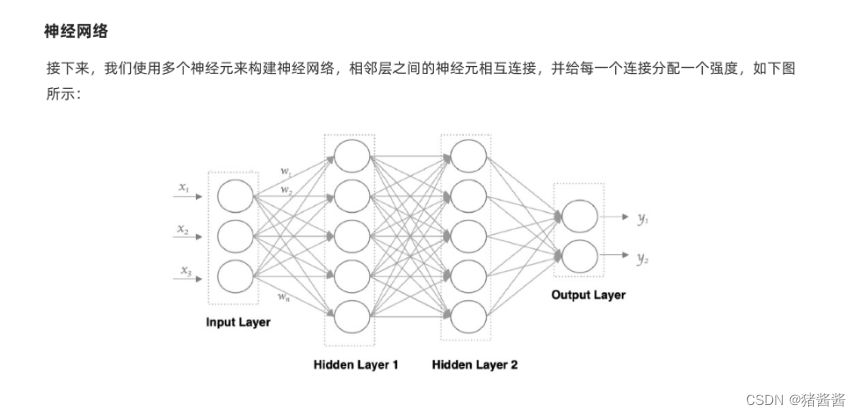
上图中 x1,x2,x3,表示的是特征,而每一个圆圈表示的是一个神经元,每一个神经元等于w1x1+w2x2+w3x3,每一条线代表一个权重值,反向传播实际上更新就是每条线的权重值

二、激活函数

常见的激活函数有 sigmoid函数、tanh函数、ReLu函数、softmax函数
以sigmoid函数为例:
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] =['SimHei'] # 用来显示正常中文标签
plt.rcParams['axes.unicode_minus'] =False # 用来正常显示符号
# 创建画布和坐标轴
_, axes = plt.subplots(1, 2) # 一行两列
# sigmoid函数图像
x = torch.linspace(-20, 20, 1000)
# 输入值x通过sigmoid函数转换成激活值y
y = torch.sigmoid(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Sigmoid 函数图像')
# sigmoid导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# print(x)
torch.sigmoid(x).sum().backward()
y=torch.sigmoid(x).sum()
print(y)
# x.detach():输入值x的数值
# x.grad:计算梯度,求导
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title('Sigmoid 导数图像')
plt.show()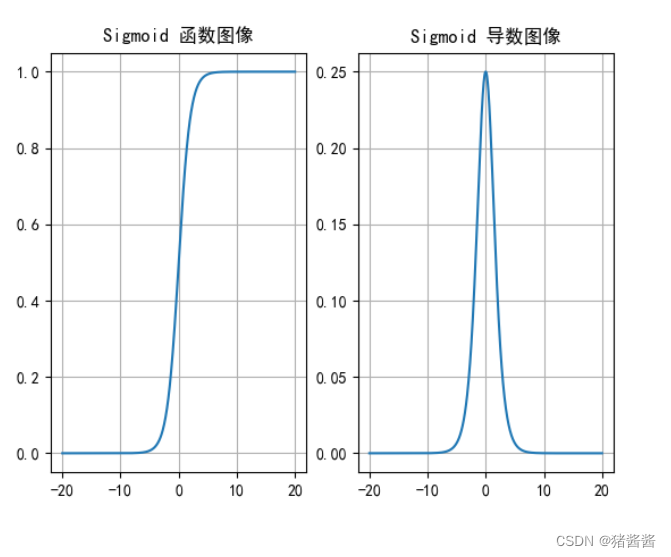
torch.sigmoid(x).sum().backward() 为什么要sun()
在PyTorch中,当你对一个张量(tensor)调用
.backward()方法时,你实际上是在尝试计算关于该张量的梯度。但是,要正确理解.sum().backward()的用途,我们需要先了解PyTorch的自动微分(autograd)系统是如何工作的。
- Scalar Outputs:在PyTorch中,为了计算梯度,你通常需要有一个scalar(标量)输出。这是因为梯度是关于某个scalar值相对于输入张量的变化的敏感度。如果你有一个多元素(non-scalar)输出,那么直接调用
.backward()可能会引发错误,因为系统不知道你想要哪个元素的梯度。.sum()的作用:当你对一个多元素张量调用.sum()时,你将得到一个scalar值(除非你在其他维度上指定了keepdim=True,但这不是通常的用法)。这个scalar值是原始张量所有元素的总和。在给出的例子中,
torch.sigmoid(x).sum()计算了x经过sigmoid激活函数后的所有元素的总和。然后,当对这个scalar值调用.backward()时,实际上是在询问:“如果我稍微改变x的值,这个总和会如何变化?” 这将为我提供关于x的每个元素的梯度,这些梯度表示了每个元素对最终scalar输出的贡献。简而言之,
.sum()的使用是为了将多元素输出转换为scalar输出,从而允许我计算梯度。如果你直接对多元素输出调用.backward()(没有使用.sum()或其他聚合操作),PyTorch将无法知道你想要哪个元素的梯度,因此会报错
backward()方法来计算梯度,自动微分。这会将x的梯度(即tanh的导数)存储在x.grad中。
三、参数初始化
常用初始化方法:
- 均匀分布初始化
权重参数初始化从区间均匀随机取值。即在(-1/√d,1/√d)均匀分布中生成当前神经元的权重,其中d为每个神经元的输入数量
- 正态分布初始化
随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化
- 全0初始化
将神经网络中的所有权重参数初始化为 0
- 全1初始化
将神经网络中的所有权重参数初始化为 1.
- 固定值初始化
将神经网络中的所有权重参数初始化为某个固定值.
- Kaiming 初始化,也叫做 HE 初始化
HE 初始化分为正态分布的 HE 初始化、均匀分布的 HE 初始化.
正态化的he初始化
- stddev = sqrt(2 / fan_in)
均匀分布的he初始化
- 它从 [-limit,limit] 中的均匀分布中抽取样本, limit是 sqrt(6 / fan_in)
fan_in 输入神经元的个数
Xavier 初始化,也叫做 Glorot初始化
该方法也有两种,一种是正态分布的 xavier 初始化、一种是均匀分布的 xavier 初始化.
正态化的Xavier初始化
- stddev = sqrt(2 / (fan_in + fan_out))
均匀分布的Xavier初始化
- [-limit,limit] 中的均匀分布中抽取样本, limit 是 sqrt(6 / (fan_in + fan_out))
fan_in 是输入神经元的个数, fan_out 是输出的神经元个数
我们一般用的是最后两个,也就是kaiming初始化和Xavier初始化 ,参数初始化的时候,会连带偏置值一起初始化,所以一般偏置值不用自己手动设置。
import torch import torch.nn.functional as F import torch.nn as nn # 1. 均匀分布随机初始化 def test01(): linear = nn.Linear(5, 3) # 从0-1均匀分布产生参数 nn.init.uniform_(linear.weight) print(linear.weight.data) # 2.固定初始化 def test02(): linear = nn.Linear(5, 3) nn.init.constant_(linear.weight, 5) print(linear.weight.data) # 3. 全0初始化 def test03(): linear = nn.Linear(5, 3) nn.init.zeros_(linear.weight) print(linear.weight.data) # 4. 全1初始化 def test04(): linear = nn.Linear(5, 3) nn.init.ones_(linear.weight) print(linear.weight.data) # 5. 正态分布随机初始化 def test05(): linear = nn.Linear(5, 3) nn.init.normal_(linear.weight, mean=0, std=1) print(linear.weight.data) # 6. kaiming 初始化 def test06(): # kaiming 正态分布初始化 linear = nn.Linear(5, 3) nn.init.kaiming_normal_(linear.weight) print(linear.weight.data) # kaiming 均匀分布初始化 linear = nn.Linear(5, 3) nn.init.kaiming_uniform_(linear.weight) print(linear.weight.data) # 7. xavier 初始化 def test07(): # xavier 正态分布初始化 linear = nn.Linear(5, 3) nn.init.xavier_normal_(linear.weight) print(linear.weight.data) # xavier 均匀分布初始化 linear = nn.Linear(5, 3) nn.init.xavier_uniform_(linear.weight) print(linear.weight.data)
四、神经网络的搭建(重点)
在pytorch中定义深度神经网络其实就是层堆叠的过程,继承自nn.Module,实现两个方法(一个继承 两个方法):
__init__方法中定义网络中的层结构,主要是全连接层,并进行初始化
forward方法,在实例化模型的时候,底层会自动调用该函数。该函数中可以定义学习率,为初始化定义的layer传入数据等。
我们来构建如下图所示的神经网络模型:
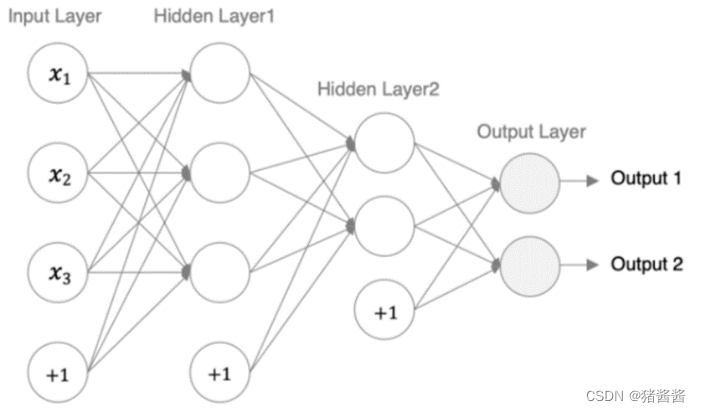
编码设计如下:
第1个隐藏层:权重初始化采用标准化的xavier初始化 激活函数使用sigmoid
第2个隐藏层:权重初始化采用标准化的He初始化 激活函数采用relu
out输出层线性层 假若二分类,采用softmax做数据归一化
import torch
import torch.nn as nn
from torchsummary import summary
# 创建神经网络模型类
class Net(nn.Module):
#初始化属性值
def __init__(self):
super(Net, self).__init__()#调用父类的初始化属性值
self.linear1 = nn.Linear(3, 3)
#初始化权重
nn.init.xavier_normal_(self.linear1.weight)#会自动初始化偏置
self.linear2 = nn.Linear(3, 2)
nn.init.kaiming_normal_(self.linear2.weight)
self.out = nn.Linear( 2, 2)
# 创建向前传播方法 自动执行forward的方法
def forward(self, x):
# 数据进入第一层
x = self.linear1(x)
# 使用sigmoid激活函数
x = torch.sigmoid(x)
# 数据进入第二层
x = self.linear2(x)
# 使用relu激活函数
x = torch.relu(x)
# 数据进入输出层
x = self.out(x)
# 使用softmax激活函数
# dim=-1: 每一维度行数据相加为1
x = torch.softmax(x,-1)
# 返回结果
return x
if __name__ == '__main__':
my_model = Net()
# 产生随机数据
my_data = torch.randn(5,3)
print('mydata-shape', my_data.shape)
# 数据经过神经网络模型训练
my_out = my_model(my_data)
print('my_out-shape', my_out.shape)
print('my_out', my_out)
# 打印神经网络模型结构
summary(my_model, input_size=(5,3))
# 打印神经网络模型参数
print(my_model.state_dict())
# 打印神经网络模型参数
print(my_model.state_dict().keys())
# 打印神经网络模型参数
print(my_model.state_dict()['linear1.weight'])
# 打印神经网络模型参数
print(my_model.state_dict()['linear1.bias'])
# 打印神经网络模型参数
print(my_model.state_dict()['linear2.weight'])
# 打印神经网络模型参数
print(my_model.state_dict()['linear2.bias'])
# 打印神经网络模型参数
print(my_model.state_dict()['out.weight'])
# 打印神经网络模型参数
print(my_model.state_dict()['out.bias'])
summary(my_model, input_size=(5,3)) 这个函数是输出模型的权重情况,input_size(5,3)表示传入五个样本,每个样本3个特征
五、损失函数
什么是损失函数
在深度学习中, 损失函数是用来衡量模型参数的质量的函数, 衡量的方式是比较网络输出和真实输出的差异:
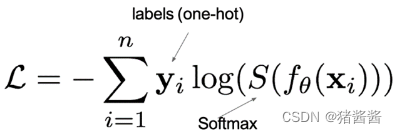
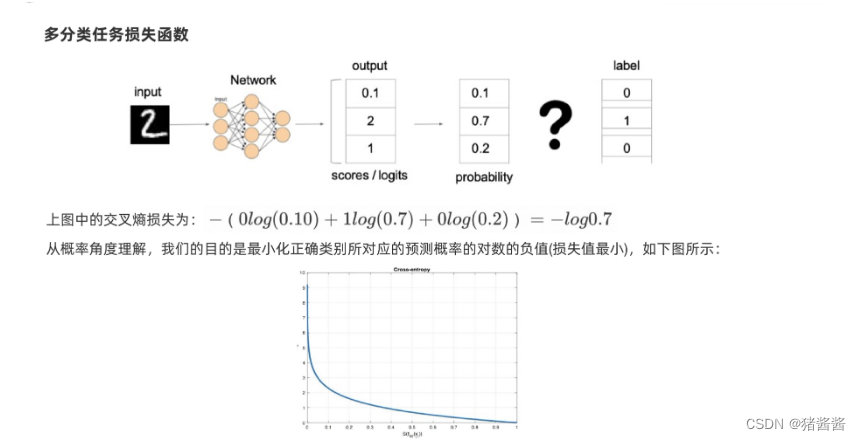
在多分类任务通常使用softmax将logits转换为概率的形式,所以多分类的交叉熵损失也叫做softmax损失,它的计算方法是:
1.多分类损失:
其中:
1.y 是样本 x 属于某一个类别的真实概率
2.而 f(x) 是样本属于某一类别的预测分数
3.S 是 softmax 激活函数,将属于某一类别的预测分数转换成概率
4.L 用来衡量真实值 y 和预测值 f(x) 之间差异性的损失结果
在pytorch中使用nn.CrossEntropyLoss()实现,如下所示:
import torch
from torch import nn
# 多分类交叉熵损失,使用nn.CrossEntropyLoss()实现。nn.CrossEntropyLoss()=softmax + 损失计算
def test1():
# 设置真实值: 可以是热编码后的结果也可以不进行热编码
# y_true = torch.tensor([[0, 1, 0], [0, 0, 1]], dtype=torch.float32)
# 注意的类型必须是64位整型数据
y_true = torch.tensor([1, 2], dtype=torch.int64)
y_pred = torch.tensor([[0.2, 0.6, 0.2], [0.1, 0.8, 0.1]], dtype=torch.float32)
# 实例化交叉熵损失
loss = nn.CrossEntropyLoss()
# 计算损失结果
my_loss = loss(y_pred, y_true).numpy()
print('loss:', my_loss)
2.二分类损失
在处理二分类任务时,我们不再使用softmax激活函数,而是使用sigmoid激活函数,那损失函数也相应的进行调整,使用二分类的交叉熵损失函数:
其中:
y 是样本x属于某一个类别的真实概率
而 y^ 是样本属于某一类别的预测概率
L 用来衡量真实值y与预测值y^之间差异性的损失结果。
在pytorch中实现时使用nn.BCELoss() ,如下所示:
import torch
from torch import nn
def test2():
# 1 设置真实值和预测值
# 预测值是sigmoid输出的结果
y_pred = torch.tensor([0.6901, 0.5459, 0.2469], requires_grad=True)
y_true = torch.tensor([0, 1, 0], dtype=torch.float32)
# 2 实例化二分类交叉熵损失
criterion = nn.BCELoss()
# 3 计算损失
my_loss = criterion(y_pred, y_true).detach().numpy()
print('loss:', my_loss)
3.回归任务损失函数-MAE损失
Mean absolute loss(MAE)也被称为L1 Loss,是以绝对误差作为距离。损失函数公式:
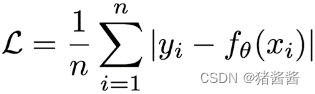
曲线如下图所示:
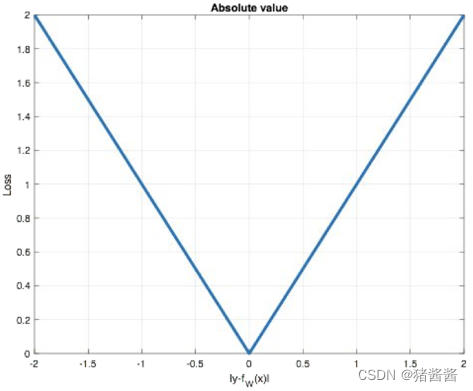
特点是:
- 由于L1 loss具有稀疏性,为了惩罚较大的值,因此常常将其作为
正则项添加到其他loss中作为约束。
- L1 loss的最大问题是梯度在零点不平滑,导致会跳过极小值。
在pytorch中使用nn.L1Loss()实现,如下所示:
import torch
from torch import nn
def test3():
# 1 设置真实值和预测值
y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float32)
# 2 实例MAE损失对象
loss = nn.L1Loss()
# 3 计算损失
my_loss = loss(y_pred, y_true).detach().numpy()
print('loss:', my_loss)
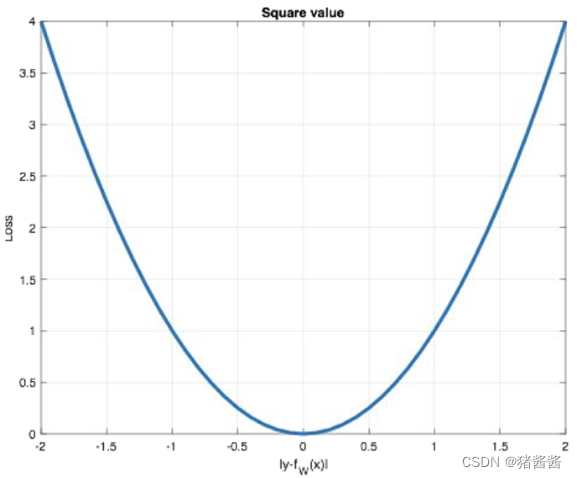
4.回归任务损失函数-MSE损失
Mean Squared Loss/ Quadratic Loss(MSE loss)也被称为L2 loss,或欧氏距离,它以误差的平方和的均值作为距离
损失函数公式:
曲线如下图所示:
特点是:
1.L2 loss也常常作为正则项。
2.当预测值与目标值相差很大时, 梯度容易爆炸。
在pytorch中使用nn.MSELoss()实现,如下所示:
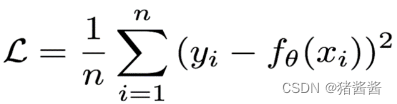
import torch
from torch import nn
def test4():
# 1 设置真实值和预测值
y_pred = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
y_true = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float32)
# 2 实例MSE损失对象
loss = nn.MSELoss()
# 3 计算损失
my_loss = loss(y_pred, y_true).detach().numpy()
print('myloss:', my_loss)
5.回归任务损失函数-Smooth L1损失
smooth L1说的是光滑之后的L1。损失函数公式:
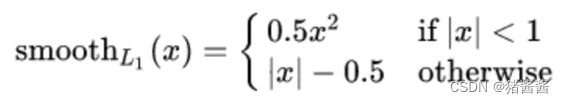
其中:𝑥 = f(x) − y 为真实值和预测值的差值。
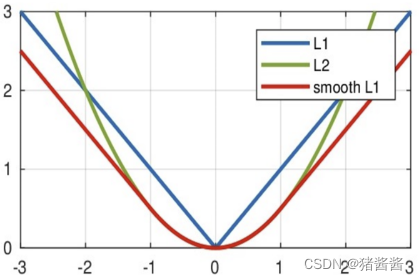
从下图中可以看出,该函数实际上就是一个分段函数
-
在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑问题
-
在[-1,1]区间外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题
在pytorch中使用nn.SmoothL1Loss()实现,如下所示:
import torch
from torch import nn
def test5():
# 1 设置真实值和预测值
y_true = torch.tensor([0, 3])
y_pred = torch.tensor([0.6, 0.4], requires_grad=True)
# 2 实例化smoothL1损失对象
loss = nn.SmoothL1Loss()
# 3 计算损失
my_loss = loss(y_pred, y_true).detach().numpy()
print('loss:', my_loss)
六、网络优化方法
1. 梯度下降算法
梯度下降法是一种寻找使损失函数最小化的方法。从数学上的角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向,所以有:
其中,η是学习率,如果学习率太小,那么每次训练之后得到的效果都太小,增大训练的时间成本。如果,学习率太大,那就有可能直接跳过最优解,进入无限的训练中。解决的方法就是,学习率也需要随着训练的进行而变化。
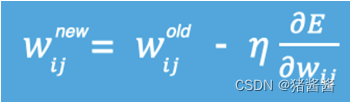
2.方向传播算法(BP算法)
前向传播:指的是数据输入的神经网络中,逐层向前传输,一直到运算到输出层为止。
反向传播(Back Propagation):利用损失函数 ERROR,从后往前,结合梯度下降算法,依次求各个参数的偏导,并进行参数更新,链式求导
import torch
from torch import nn
from torch import optim
# 创建神经网络类
class Model(nn.Module):
# 初始化参数
def __init__(self):
# 调用父类方法
super(Model, self).__init__()
# 创建网络层
self.linear1 = nn.Linear(2, 2)
self.linear2 = nn.Linear(2, 2)
# 初始化神经网络参数
self.linear1.weight.data = torch.tensor([[0.15, 0.20], [0.25, 0.30]])
self.linear2.weight.data = torch.tensor([[0.40, 0.45], [0.50, 0.55]])
self.linear1.bias.data = torch.tensor([0.35, 0.35])
self.linear2.bias.data = torch.tensor([0.60, 0.60])
# 前向传播方法
def forward(self, x):
# 数据经过第一层隐藏层
x = self.linear1(x)
# 计算第一层激活值
x = torch.sigmoid(x)
# 数据经过第二层隐藏层
x = self.linear2(x)
# 计算第二层激活值
x = torch.sigmoid(x)
return x
if __name__ == '__main__':
# 定义网络输入值和目标值
inputs = torch.tensor([[0.05, 0.10]])
target = torch.tensor([[0.01, 0.99]])
# 实例化神经网络对象
model = Model()
output = model(inputs)
print("output-->", output)
loss = torch.sum((output - target) ** 2) / 2 # 计算误差
print("loss-->", loss)
# 优化方法和反向传播算法
optimizer = optim.SGD(model.parameters(), lr=0.5)
optimizer.zero_grad()
loss.backward()
print("w1,w2,w3,w4-->", model.linear1.weight.grad.data)
print("w5,w6,w7,w8-->", model.linear2.weight.grad.data)
optimizer.step()
# 打印神经网络参数
print(model.state_dict())3.梯度下降优化方法
动量算法
通过对梯度指数加权平均 让每一个梯度点的计算参考最近的梯度值,让梯度下降曲线更加平滑,有利于梯度下降的效率。
梯度计算公式:Dt = β * St-1 + (1- β) * Wt
St-1 表示历史梯度移动加权平均值
Wt 表示当前时刻的梯度值
Dt 为当前时刻的指数加权平均梯度值
β 为权重系数
假设:权重 β 为 0.9,例如:
第一次梯度值:s1 = d1 = w1
第二次梯度值:d2=s2 = 0.9 * s1 + w2 * 0.1
第三次梯度值:d3=s3 = 0.9 * s2 + w3 * 0.1
第四次梯度值:d4=s4 = 0.9 * s3 + w4 * 0.1
adagrad
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小。
其计算步骤如下:
1.初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
2.初始化梯度累积变量 s = 0
3.从训练集中采样 m 个样本的小批量,计算梯度 g
4.累积平方梯度 s = s + g ⊙ g,⊙ 表示各个分量相乘
学习率 α 的计算公式如下:
参数更新公式如下:
重复 2-4 步骤,即可完成网络训练。
AdaGrad 缺点是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
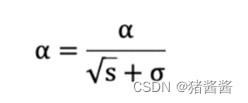
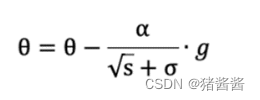
RMSProp
RMSProp 优化算法是对 AdaGrad 的优化. 最主要的不同是,其使用指数移动加权平均梯度替换历史梯度的平方和。其计算过程如下:
初始化学习率 α、初始化参数 θ、小常数 σ = 1e-6
初始化参数 θ
初始化梯度累计变量 s
从训练集中采样 m 个样本的小批量,计算梯度 g
使用指数移动平均累积历史梯度,公式如下:
学习率 α 的计算公式如下:
参数更新公式如下:
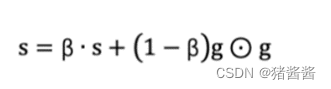
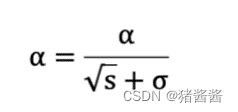
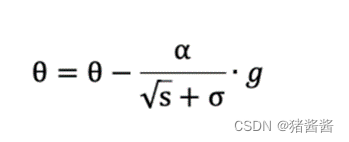
Adam
Momentum 使用指数加权平均计算当前的梯度值
AdaGrad、RMSProp 使用自适应的学习率
Adam优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起。
修正梯度: 使⽤梯度的指数加权平均
修正学习率: 使⽤梯度平⽅的指数加权平均。
import torch
import matplotlib.pyplot as plt
def test06():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True)
y = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:Adam算法,其中betas是指数加权的系数
optimizer = torch.optim.Adam([w], lr=0.01, betas=[0.9, 0.99])
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
y = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
y.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
七、正则化方法
1. Dropout正则化
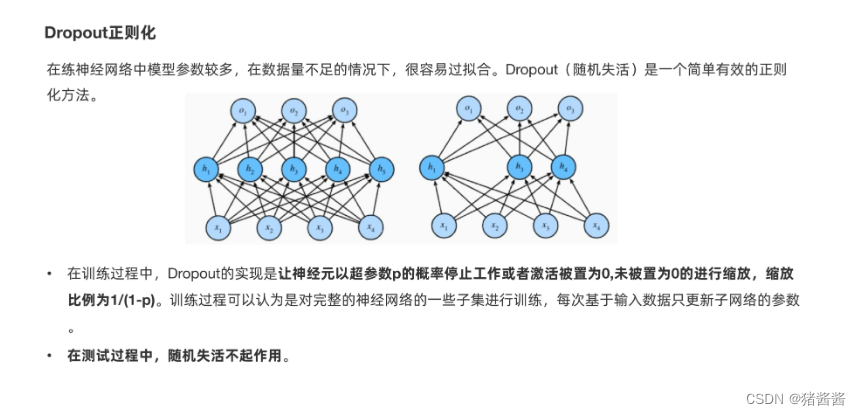
import torch
import torch.nn as nn
def test():
# 初始化随机失活层
dropout = nn.Dropout(p=0.4)
# 初始化输入数据:表示某一层的weight信息
inputs = torch.randint(0, 10, size=[1, 4]).float()
layer = nn.Linear(4,5)
y = layer(inputs)
print("未失活FC层的输出结果:\n", y)
y = dropout(y)
print("失活后FC层的输出结果:\n", y)
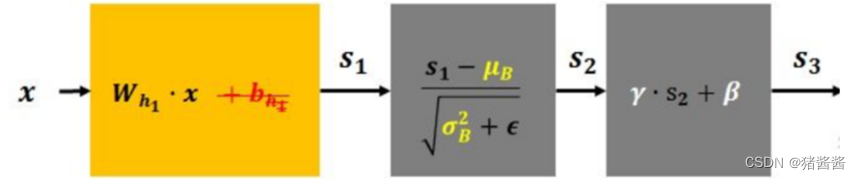
2.批量归一化
先对数据标准化,再对数据重构(缩放+平移),如下所示:
1.λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为系数,β 为偏置;
2.eps 通常指为 1e-5,避免分母为 0;
3.E(x) 表示变量的均值;
4.Var(x) 表示变量的方差
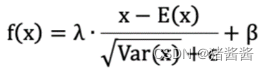















 23万+
23万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









