







一、dataframe读取数据文件
导包:import pandas as pd
格式:pd对象.read_数据格式(路径)
# 例如:
pd.read_csv('data/movie.csv')
import pandas as pd
data=pd.read_csv('data/test.tsv',sep='\t')
data_fm=data.head()数据格式一般有以下几种
#cvs:文本数据文件
#html:html数据文件
#pickle:Python特有文件
#json:json数据文件
#excel:excel类型的数据文件
csv_data=pd.read_csv('output/test.tsv',sep='\t')
html_data=pd.read_html('output/test.html')
pick_data=pd.read_pickle('output/test.pickle')
json_data=pd.read_json('output/test.json')
excel_data=pd.read_excel('output/test.xlsx')
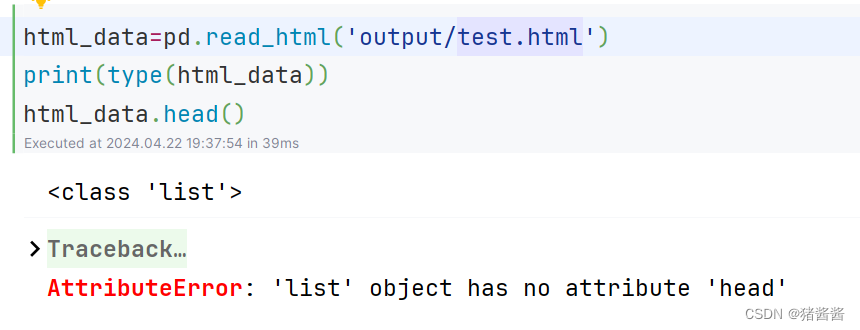
其它四个读取的数据文件对象都是dataframe类型,可以直接使用dataframe的属性和方法,而需要注意的是读取html格式的数据文件类型是列表(list),所以它不能直接使用dataframe的属性和方法。如下:
二、dataframe对象保存数据到文件
import pandas as pd
data=pd.read_csv('data/test.tsv',sep='\t')#读取数据文件
data_fm=data.head()#获取数据文件的前五行
data_fm.to_pickle('output/test.pickle')#将data_fm对象保存为pickle类型的文件
data_fm.to_excel('output/test.xlsx')#将data_fm对象保存为excel类型的文件
data_fm.to_csv('output/test.tsv',index=False,sep='\t')#将data_fm对象保存为csv类型的文件
data_fm.to_json('output/test.json')#将data_fm对象保存为json类型的文件
data_fm.to_html('output/test.html')#将data_fm对象保存为html类型的文件其中设置index=False可以取消索引保存,即保存的文件不包含索引,值得注意的是,如果是自己设置了索引名,请重置索引再保存(reset_index()),而sep参数在保存.tsv文件是常用,可以让保存的数据不以逗号隔开,而是以空格隔开
加了sep='\t':
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









