







硕士在读,做的车辆异常检测相关方向,包括不限于轨迹异常检测,车联网,汽车CAN总线网络攻击异常检测等,偏好联邦学习来做。分享关于此方向的一些见解和分享。有人看的话可以更新此系列
前言
题目:AI-Empowered Trajectory Anomaly Detection for Intelligent Transportation Systems: A Hierarchical Federated Learning Approach
这篇文章是一篇2023年发表在T-ITS上面的论文,提出了一个基于分层联邦学习的轨迹异常检测架构,结合了人工智能与区块链技术,兼顾隐私保护与模型泛化能力。
提示:以下是本篇文章正文内容,下面案例可供参考
一、研究背景和motivation
轨迹异常检测在智能交通系统(ITS)中起着至关重要的作用。例如,实时发现交通事故、违法行为、拥堵路段等都依赖对轨迹的快速分析。但存在两个核心挑战:
轨迹异常检测在智能交通系统(ITS)中起着至关重要的作用。例如,实时发现交通事故、违法行为、拥堵路段等都依赖对轨迹的快速分析。但存在两个核心挑战:
-
数据隐私问题:轨迹数据可能包含敏感信息,不能直接集中收集;
-
模型泛化能力差:局部模型只适用于特定区域,难以推广到其他城市或场景。
为此,本文提出了一种分层联邦学习(Hierarchical Federated Learning, HFL)+区块链架构,在提升模型泛化能力的同时,保护了数据隐私。
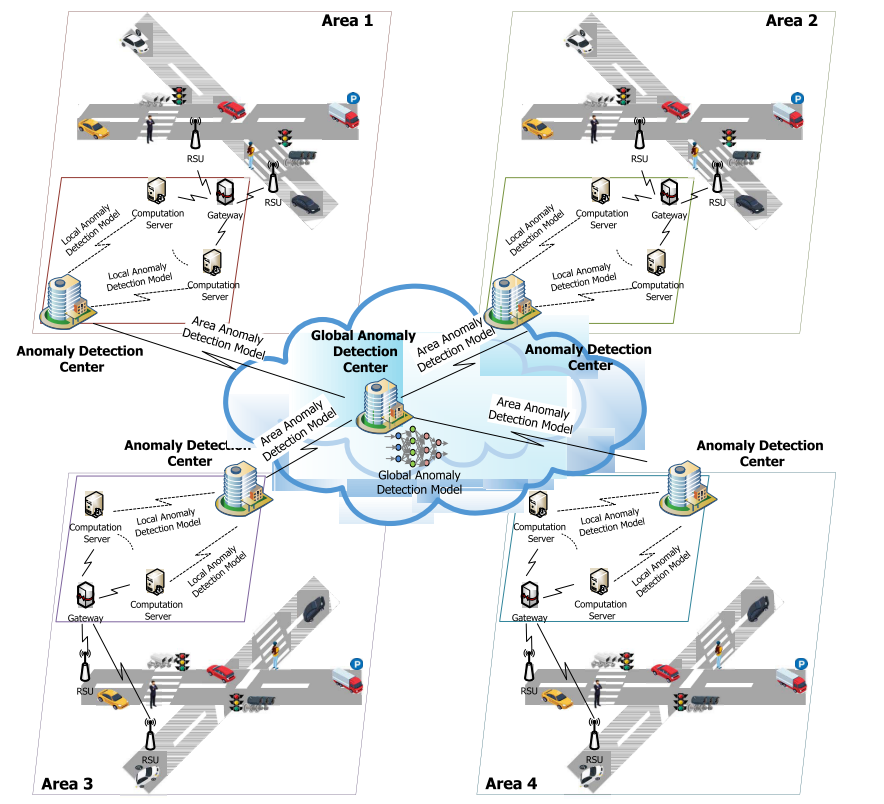
二、系统模型
整套系统采用了三级结构:(分层的结构)
-
参与节点(Clients):位于不同区域,采集本地轨迹数据,训练本地模型;
-
区域聚合服务器(Area Server):对本区域的本地模型进行联邦聚合,生成区域模型;
-
全局聚合服务器(Global Server):将多个区域模型再进行一次联邦聚合,得到全局轨迹异常检测模型。
关键亮点在于:两级聚合策略 + 区块链+IPFS存证机制,让整个模型训练过程可追溯、防篡改、可信赖。(下面的两个图本人觉得画的着实不错)
三、所提框架方法
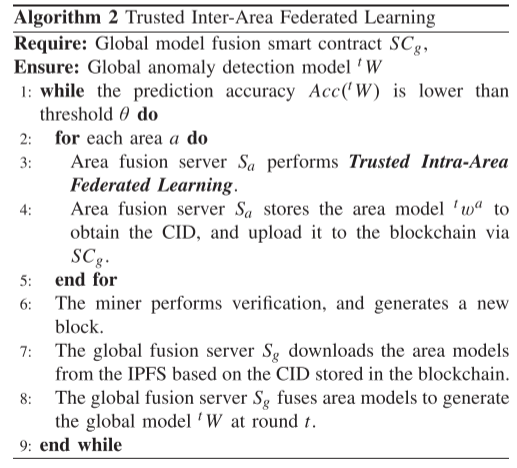
分层联邦学习机制
-
区域内聚合(Intra-Area FL):每个区域内部通过 FedAvg 聚合本地模型,生成区域模型;
-
区域间聚合(Inter-Area FL):将多个区域模型加权融合,构建全局模型;
为了提升泛化能力,作者设计了一个加权融合策略:
融合时,区域模型的权重由与目标区域模型的欧氏距离决定,差异越小,权重越大,从而提升目标区域检测效果。
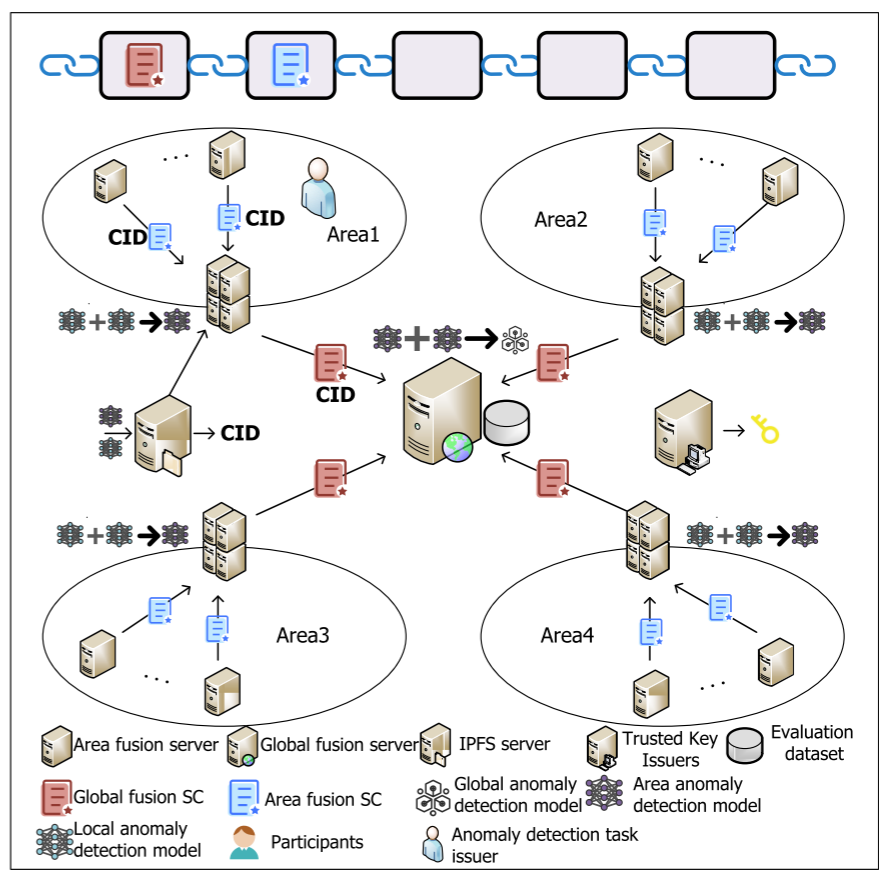
区块链保障可信训练
系统使用两类智能合约:
-
区域模型上传合约(SCa)
-
全局模型上传合约(SCg)
所有模型存入 IPFS(内容寻址分布式文件系统),其哈希值(CID)记录在区块链中,确保模型内容不可篡改、可溯源。

在FL的创新上其实不多,主要是一个分层+聚合的权重策略上。
四、实验设计
论文采用 NGSIM 真实交通数据集 + 合成6类异常轨迹(如急加速、长时间停滞、左右摆动等),在模拟的两区域场景中进行了验证。NGSIM是一个比较经典的数据集了,具体他这个异常轨迹是合成的还是说按照阈值分出来的我还没看懂。但是实验设计比较贴合真实场景。
模型结构:
-
LSTM 层:64单元
-
Dense 层:7个神经元输出(对应不同异常类型)
主要是一个监督学习的LSTM的分类问题,不过论文创新在于FL+区块链的框架,模型关系不大。
实验结果总结:
-
准确率(Accuracy) 提升至 85.7%,优于 CNN-GPSTasST 和 CNN-VAE;
-
泛化能力更强:在混合区域数据上全局模型表现优于任一区域模型;
-
资源消耗可控:在四节点区块链部署中,CPU 和内存占用在可接受范围内。
这里的对比算法是两个比较代表性的工作也是针对于车辆轨迹异常检测的,但是并没有采用FL的方法。
参考文献:
Wang et al., "AI-Empowered Trajectory Anomaly Detection for Intelligent Transportation Systems: A Hierarchical Federated Learning Approach", IEEE T-ITS, 2023.
总结
在FL+车辆轨迹异常检测里面是一个比较新颖的工作,对我来说是比较有启发性的,也是本人在这个方向follow的第一篇论文。


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









