







第一 介绍
(1)数据选取:银行客户信贷业务交易数据。数据分为训练数据集(train.csv)和测试数据集(test.csv)
(2)数据来源:某股份制商业银行。
(3)数据背景介绍:信用风险是金融监管机构重点关注的风险,关乎金融系统运行的稳定,银行会根据客户的资质来评定,比如征信,贷款额度,贷款的用途,贷款的时间,还款的能力,收入的稳定性等多方面去分析。在实际业务开展和模型构建过程中,面临着高维稀疏特征以及样本不平衡等各种问题,应用机器学习等数据挖掘方法提高信用风险的评估和预测能力,是各家金融机构积极探索的方向。
(4)分析工具:本次课程在对数据进行处理、探索、建模和决策分析的过程中,使用Python程序语言和机器学习系统XGBoost。
第二 数据说明
银行客户信贷业务交易数据,按数据变量含义共分为三大类。如表所示,数据分为用户基本信息、借贷相关信息和用户特征相关信息。
数据变量说明表:
| 序号 | 变量 | 变量含义 | |
| 1. 用户基本属性信息 | |||
| 1 | id | 用户唯一标识 | |
| 2 | certId | 证件号 | |
| 3 | gender | 性别 | |
| 4 | age | 年龄 | |
| 5 | dist | 所在地区 | |
| 6 | edu | 学历 | |
| 7 | job | 工作单位类型 | |
| 8 | ethnic | 民族 | |
| 9 | highestEdu | 最高学历 | |
| 10 | certValidBegin | 证件号起始日 | |
| 11 | certValidStop | 证件号失效日 | |
| 2. 借贷相关信息 | |||
| 12 | loanProduct | 借贷产品类型 | |
| 13 | lmt | 预授信金额 | |
| 14 | basicLevel | 基础评级 | |
| 15 | bankCard | 放款卡号 | |
| 16 | residentAddr | 居住地 | |
| 17 | linkRela | 联系人关系 | |
| 18 | setupHour | 申请时段 | |
| 19 | weekday | 申请日 | |
| 3. 用户征信相关信息 | |||
| 20 | ncloseCreditCard | 失效信用卡数 | |
| 21 | unpayIndvLoan | 未支付个人贷款金额 | |
| 22 | unpayOtherLoan | 未支付其他贷款金额 | |
| 23 | unpayNormalLoan | 未支付贷款平均金额 | |
| 24 | 5yearBadloan | 五年内未支付贷款金额 | |
| 25 | x_0至x_78 | 该部分数据涉及较为第三方敏感信用数据,匿名化处理,不影响建模和数据分析 | |
第三 数据探索
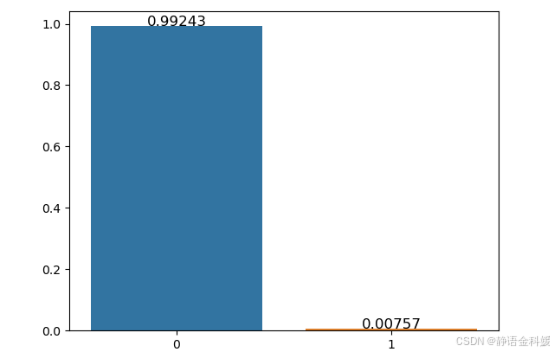
- 违约用户数量分布
违约用户数量分布,可以看出违约的用户较少,只占0.7%,获取的数据存在样本不均衡情况。这也说明了在真实情况下银行违约的客户数量还是占比很少的。
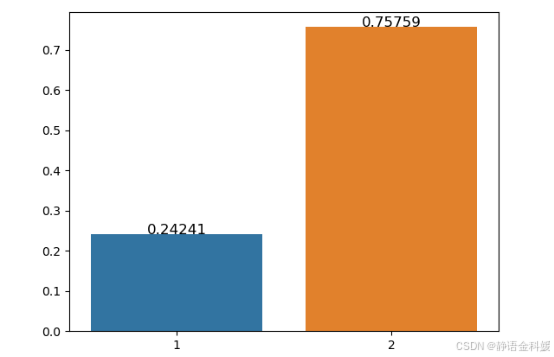
- 违约用户性别分布
违约用户性别分布图可以看出,违约用户的年龄差别较大,大部分为男性(gender=1)。在违约用户中,男性占比为75.76%,女性占比为24.24%。从逾期占比情况来看,男性逾期占比高于女性近51%。解释这一现象可以考虑从家庭及社会分工考虑,男性是主要的借贷群里,群体基数大,因此违约占比概率高。
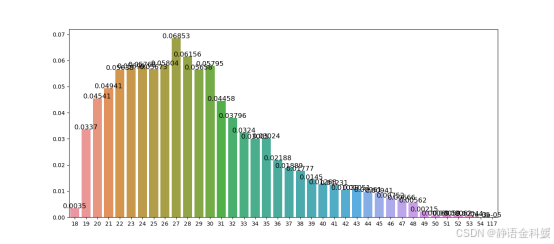
- 违约用户年龄分布
违约用户年龄分布图可以看出,违约用户年龄集中在 19-35 岁之间。该区间年龄段用户承担的角色主要是学生和家庭的顶梁柱,同时也是借贷用户的主要群体。
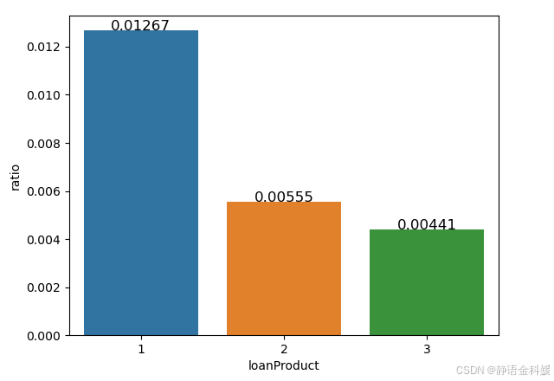
- 不同信贷产品类型的违约分布
将数据集按照信贷产品类型进行分组统计,分别计算不同组违约的比例。其中信贷产品1的违约比例最高。这说明借贷产品在产品设计方面需要优化改进,避免高违约率情况发生。通过进一步挖掘和分析不同信贷产品在违约率差异上存在的原因,帮助商业银行在产品设计方面提供的决策支持。
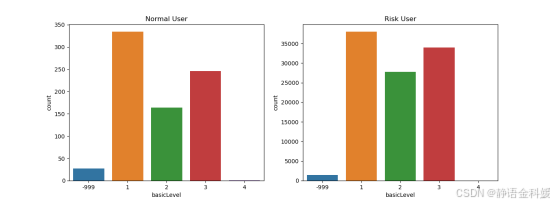
- 信用评级分布
客户信用评级是指商业银行为有效控制客户信用风险,实现信贷资金的安全性、流动性和收益性,从客户经营能力、盈利能力、偿债能力、发展能力,以及客户素质和信用状况等方面,对客户进行综合评价和信用等级的确定。图中看出银行进行客户筛选时是会重点考虑客户信用评级,对于信用评级差的客户会拒绝审批信贷业务;但是对于潜在风险客户,各类信用评级的分布都是存在的,进一步说明信用风险是难以预测的。
第四 数据建模
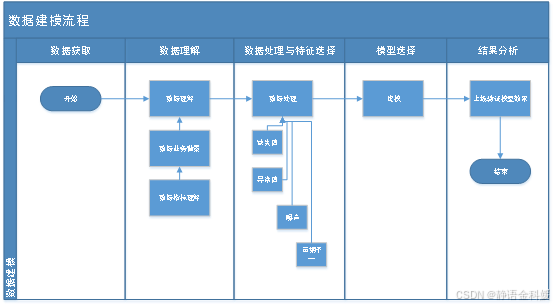
- 建模流程
信用风险是金融监管机构重点关注的风险。在实际业务开展和模型构建过程中,商业银行运用数据挖掘、数据建模等方法进行决策,提高信用风险的评估和预测能力。本课程项目使用XGBoost进行机器学习实现决策树模型构建用户风控预警。
数据建模的流程可以归纳五个步骤,分别是数据获取、数据理解、数据处理与特征选择、模型选择和结果分析。
- 模型评估
在本课题研究中,选择Pthon语言和XGBoost进行决策树模型建模。XGBoost是一套提升树可扩展的机器学习系统。目标是设计和构建高度可扩展的端到端提升树系统。使用机器学习建模的一般流程分为两大部分:数据处理和模型学习。第一部分需要大量的知识对原始数据进行清理及特征提取;第二部分模型学习,涉及长时间的模型参数调整,调整方向和策略需要根据经验来灵活调整。
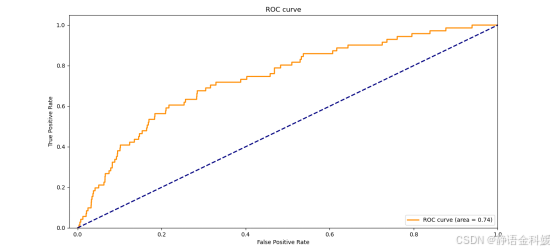
根据提供的训练数据集(train.csv)和测试数据集(test.csv)进行模型训练和测试验证,用ACU值进行模型评分(AUC是衡量学习器优劣的一种性能指标。AUC可通过对ROC曲线下各部分的面积求和而得)。
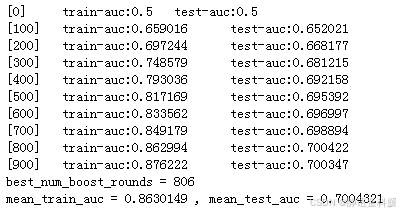
通过交叉训练最佳迭代次数进行参数调优,并利用最佳迭代次数和全量数据再次训练模型。最后得到平均训练集ACU=0.863和平均测试集AUC=0.7。
根据模型分析各个特征重要程度,可以看出lmt(预授信金额)、residentAddr(居住地)等特征是非常重要的模型评估指标。
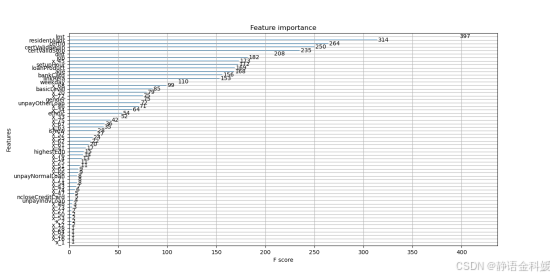
- 结果分析
根据用户基本信息、借款信息、信用卡消费记录等数据构建模型去判断这个用户是否会发生逾期的风险。
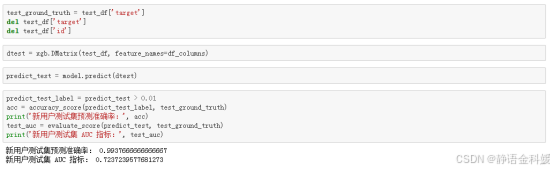
结果表示新用户测试集预测准确率99.37%,新用户测试集 AUC 指标72.37%。


















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











