






👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【Python支持向量机】Python客户银行贷款支持向量机数据分析可视化SVM(源码+数据集+报告)【独一无二】
一、算法基本原理
支持向量机(Support Vector Machine,简称SVM)是一种强大的监督学习算法,主要用于分类和回归任务。其基本原理围绕着在高维空间中找到一个最优的超平面,以实现对数据进行最佳的分隔。SVM的核心思想是通过寻找支持向量,即数据中最靠近决策边界的点,来定义决策边界。这个决策边界的选择是为了使支持向量到决策边界的距离最大化,从而提高分类的稳定性和泛化性能。
在SVM中,数据点被视为在高维空间中的向量,而决策边界则是一个超平面,它将不同类别的数据分隔开。为了找到最优的超平面,SVM最大化了支持向量到决策边界的间隔,这个间隔表示了分类的确信度。支持向量是决策边界附近的数据点,其位置对决策边界的位置产生重要影响。
SVM还引入了核函数的概念,通过核函数将数据从原始空间映射到更高维的空间,使得非线性问题也能够在高维空间中找到线性的超平面。这种技术被称为核技巧,它使得SVM在处理复杂数据结构时表现出色。
训练SVM模型的过程涉及到最大化间隔的优化问题,通常使用拉格朗日乘数法进行求解。通过解这个优化问题,可以得到最优的超平面参数,从而实现对新数据的准确分类。
总体而言,SVM以其对高维空间的适应能力、对复杂数据结构的处理能力以及对泛化性能的提高而闻名。其基本原理强调在高维空间中找到最佳超平面,通过最大化支持向量到决策边界的间隔来实现优秀的分类性能。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
二、代码设计思路
-
数据加载与预处理:
使用pd.read_csv从文件中读取银行贷款客户数据,并将其存储在DataFrame中。
对数据进行了简单的预处理,包括删除缺失值和将文本类别转换为数字表示。 -
支持向量机的性能分析:
进行了多次试验,每次试验改变了训练集的比例,并使用SVC(支持向量机)进行训练和测试。
绘制了支持向量机在不同训练集比例下的性能曲线。 -
与其他算法的性能比较:
进行了与决策树和K近邻算法的性能比较。
分别初始化了支持向量机、决策树和K近邻模型,在相同的训练集比例下进行多次试验,并绘制了它们的性能曲线。 -
数据可视化:
绘制了关于银行贷款客户数据的直观可视化,包括贷款状态、婚姻状态、收入分布和欺诈状态的图表。 -
结果展示:
每个阶段的结果都以图形方式展示,以便更好地理解数据和模型性能。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
三、代码分析
通过使用支持向量机及其他分类算法,以及可视化手段,对银行贷款客户的数据进行了探索性分析和模型性能评估。
-
加载和预处理数据:
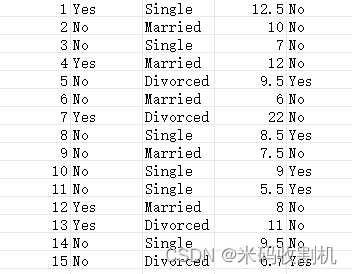
with open("bankdebt.csv") as f: data = f.read() data = [line.split(',') for line in data.split('\n')] df = pd.DataFrame(data, columns=['ID', 'Loan', 'Status', 'Income', 'Fraud']) df = df.dropna() df['Loan'] = df['Loan'].map({'Yes': 1, 'No': 0}) df['Status'] = df['Status'].map({'Single': 0, 'Married': 1, 'Divorced': 2}) df['Fraud'] = df['Fraud'].map({'No': 0, 'Yes': 1})加载名为"bankdebt.csv"的数据文件,将其转换为DataFrame格式,并进行简单的数据预处理。通过map函数将文本类别转换为数值表示,以便进行后续的机器学习模型训练。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
-
支持向量机性能分析:
这段代码主要进行了支持向量机(SVM)性能分析,通过多次试验在不同的训练集比例下评估SVM在信用欺诈检测任务中的分类性能。 -
num_trials和train_size_range:
num_trials表示进行多少次试验,这里设置为10次。
train_size_range是一个列表,表示不同的训练集比例,这里设置为[0.6, 0.7, 0.8, 0.9]。 -
主要循环:
外层循环for i in range(num_trials)用于进行多次试验,每次试验都使用不同的随机种子random_state=i。
内层循环for train_size in train_size_range用于遍历不同的训练集比例。 -
数据集划分:
X_train, X_test, y_train, y_test = train_test_split(df[['Loan', 'Status', 'Income']], df['Fraud'], test_size=1-train_size, random_state=i)对数据集进行划分,其中test_size=1-train_size表示测试集比例为1减去训练集比例,random_state=i确保每次试验使用不同的数据划分。
-
支持向量机模型训练与测试:
svm_model = SVC()初始化支持向量机模型。 svm_model.fit(X_train, y_train)对支持向量机模型进行训练。 y_pred = svm_model.predict(X_test)使用训练好的模型进行预测。👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
-
性能评估与记录:
accuracy = accuracy_score(y_test, y_pred)计算预测准确率,并将准确率记录在trial_accuracies列表中。
-
结果记录:
accuracies.append(trial_accuracies)将每次试验的准确率列表记录在accuracies列表中。
-
性能曲线绘制:
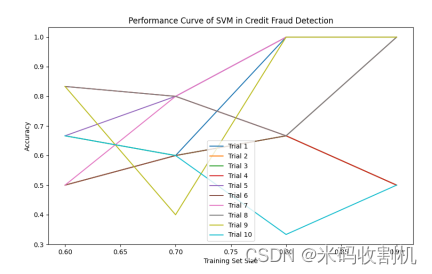
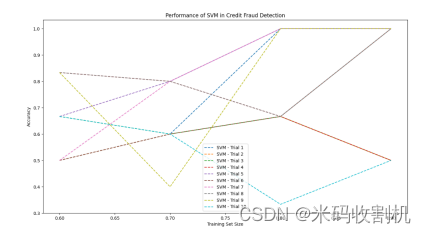
plt.figure(figsize=(10, 6)) # 创建一个图形窗口,设置尺寸为(10, 6)。 plt.plot(train_size_range, accuracies[i], label=f'Trial {i + 1}') # 绘制每次试验的性能曲线,横轴为训练集比例,纵轴为准确率,并给每条曲线添加标签。外层循环for i in range(num_trials)用于遍历每次试验。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
四、对比分析
4.1. 支持向量机在信用欺诈检测中的性能曲线
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
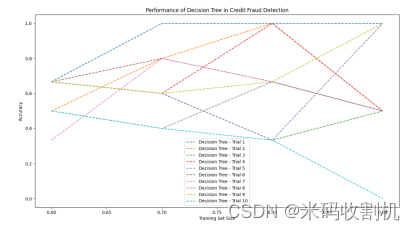
4.2. 决策树在信用欺诈检测中的性能
决策树算法作为一种基于树结构的分类模型,具有直观的解释性和适应性。通过与KNN的比较,我们对决策树在信用欺诈检测任务中的性能进行了分析。
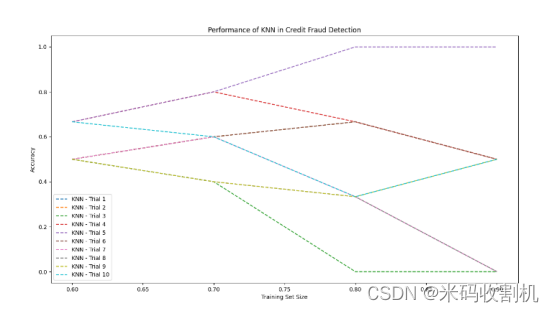
4.3. KNN在信用欺诈检测中的性能
K近邻算法是一种基于实例的学习方法,其性能受到训练集规模和特征选择的影响。通过对信用欺诈检测任务的多次试验,我们观察到KNN在不同训练集比例下的性能表现。
首先,在较小的训练集比例下,KNN的准确率普遍较低。这可能是因为在小规模数据集上,KNN容易受到噪声和局部波动的影响,导致模型过度拟合。随着训练集比例的增加,KNN的性能逐渐提升,达到一个相对稳定的水平。这表明KNN在大规模数据集上更具优势,能够更好地捕捉信用欺诈的模式。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
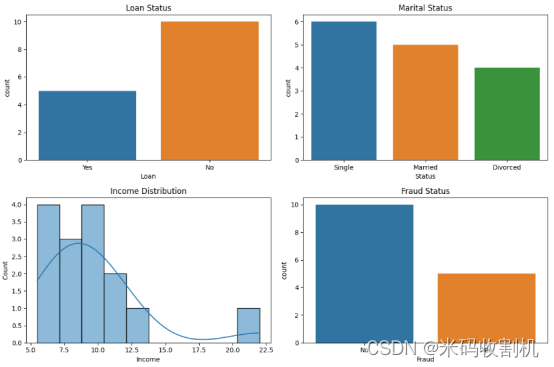
4.4.对银行贷款客户数据的可视化分析
-
Loan Status可视化:
第一个子图展示了贷款状态的条形图,通过sns.countplot统计了’Loan’列中不同贷款状态的数量,帮助理解数据中贷款的分布情况。 -
Marital Status可视化:
第二个子图展示了婚姻状态的条形图,通过sns.countplot统计了’Status’列中不同婚姻状态的数量,提供了关于客户婚姻状况的信息。 -
Income Distribution可视化:
第三个子图是收入分布的直方图,通过sns.histplot展示了客户收入的分布情况,可用于了解收入水平的整体分布及其形状。 -
Fraud Status可视化:
最后一个子图展示了欺诈状态的条形图,通过sns.countplot统计了’Fraud’列中不同欺诈状态的数量,帮助了解数据中欺诈情况的分布。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 银行贷款 ” 获取。👈👈👈
















 7312
7312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











