







信用评分模型的详细分析
1. 背景
在现代金融体系中,信用评分模型是评估借款人信用风险的重要工具。金融机构在发放贷款时,必须对借款人的还款能力进行准确评估,以降低违约风险。通过建立信用评分模型,银行可以量化借款人的信用风险,从而做出更为科学的贷款决策。
2. 数据收集
特征数据
- 年龄:借款人的年龄,通常与其收入和还款能力相关。
- 收入:借款人的月收入或年收入,直接影响其还款能力。
- 职业:借款人的职业类型,某些职业可能更稳定,风险更低。
- 信用历史:借款人过去的信用记录,包括信用卡使用情况、贷款还款记录等。
- 负债情况:借款人当前的负债水平,包括其他贷款、信用卡债务等。
- 贷款用途:借款人申请贷款的目的(如购房、购车、消费等),不同用途的风险可能不同。
目标变量
- 违约情况:借款人是否违约,通常用0(未违约)和1(违约)表示。
3. 模型训练
数据预处理
- 处理缺失值:可以选择删除缺失值、用均值/中位数填充,或使用插值法等。
- 标准化特征:对数值型特征进行标准化(如Z-score标准化或Min-Max缩放),以消除不同特征之间的量纲影响。
- 编码分类变量:对分类变量(如职业、贷款用途)进行独热编码(One-Hot Encoding)或标签编码(Label Encoding)。
选择模型
- 逻辑回归:适用于二分类问题,易于解释,能够提供每个特征对结果的影响程度。
- 支持向量机(SVM):适合高维数据,能够处理非线性问题,但对参数选择和数据预处理要求较高。
- 随机森林:集成学习方法,能够处理特征之间的复杂关系,具有较强的抗过拟合能力。
训练模型
- 划分数据集:将数据集划分为训练集和测试集(通常70%训练,30%测试)。
- 训练模型:使用训练集数据来训练所选模型,调整超参数(如正则化参数、树的深度等)以提高分类准确率。
评估模型
- 混淆矩阵:用于评估模型的分类性能,包括真正例、假正例、真负例和假负例的数量。
- ROC曲线:绘制接收者操作特征曲线,计算曲线下面积(AUC),AUC值越接近1,模型性能越好。
- 准确率、召回率和F1-score:综合评估模型的分类效果,尤其在数据不平衡的情况下,F1-score更为重要。
4. 应用
经过训练和评估的信用评分模型可以在以下方面发挥作用:
- 快速评估:银行可以利用模型快速评估借款人的信用风险,减少人工审核时间。
- 风险定价:根据借款人的信用评分,银行可以制定相应的利率和贷款条件,降低风险。
- 信贷决策:模型可以帮助银行在信贷审批中做出更为科学的决策,减少违约率,提高贷款质量。
5. 挑战与未来改进方向
挑战
- 数据隐私:处理个人金融数据时需要遵循相关法律法规,确保数据隐私和安全。
- 模型透明性:金融机构需要能够解释模型的决策过程,以满足监管要求。
- 数据不平衡:在某些情况下,违约样本较少,可能导致模型偏向于预测未违约。
未来改进方向
- 可解释性模型:使用可解释性强的模型(如决策树)或后处理技术(如LIME)来提高模型透明度。
- 动态评分:根据借款人的行为变化,实时更新信用评分,以反映其最新的信用状况。
- 多源数据融合:结合社交媒体数据、消费行为数据等多种数据源,提高信用评分的准确性。
6. 具体实施案例
为了更好地理解信用评分模型的应用,以下是一个具体实施案例的详细描述。
案例:某银行信用评分模型的实施
1. 背景
某银行希望通过建立信用评分模型来优化其贷款审批流程,降低违约率。该银行的目标是通过数据驱动的方法,快速评估借款人的信用风险,并提高信贷决策的效率。
2. 数据收集
-
特征数据:
- 借款人年龄:30岁
- 收入:年收入为60,000元
- 职业:IT行业
- 信用历史:过去5年内有1次逾期记录
- 负债情况:当前负债总额为20,000元
- 贷款用途:购房
-
目标变量:在过去的贷款记录中,该借款人是否违约(0表示未违约,1表示违约)。
3. 数据预处理
- 处理缺失值:通过均值填充处理收入和负债情况中的缺失值。
- 标准化特征:对收入和负债进行Z-score标准化,以消除量纲影响。
- 编码分类变量:将职业和贷款用途进行独热编码,生成相应的特征矩阵。
4. 模型选择与训练
- 选择模型:经过初步分析,选择逻辑回归和随机森林作为主要模型。
- 划分数据集:将数据集划分为70%的训练集和30%的测试集。
- 训练模型:
- 逻辑回归:使用训练集数据训练逻辑回归模型,并通过交叉验证调整正则化参数。
- 随机森林:使用随机森林模型,调整树的数量和深度等超参数。
5. 模型评估
- 混淆矩阵:在测试集上评估模型性能,得到混淆矩阵,分析真正例、假正例、真负例和假负例的数量。
- ROC曲线:绘制ROC曲线,计算AUC值,逻辑回归模型的AUC为0.85,随机森林模型的AUC为0.90,表明随机森林模型性能更佳。
- 准确率与F1-score:随机森林模型的准确率为88%,F1-score为0.82,显示出良好的分类效果。
6. 应用
- 快速评估:银行在贷款审批中使用训练好的随机森林模型,能够在几秒钟内评估借款人的信用风险。
- 风险定价:根据借款人的信用评分,银行为不同信用评分的借款人制定不同的利率,降低高风险借款人的贷款额度。
- 信贷决策:模型的输出结果帮助信贷审批团队做出更为科学的决策,减少了人工审核的时间和成本。
7. 持续监控与模型更新
为了确保信用评分模型的长期有效性,银行需要建立持续监控机制:
- 模型监控:定期评估模型的预测性能,监测违约率的变化,确保模型在实际应用中的有效性。
- 数据更新:随着时间的推移,借款人的信用状况可能会发生变化,因此需要定期更新模型所使用的数据集。
- 模型重训练:根据新的数据和市场变化,定期对模型进行重训练,以提高其预测能力。
8. 未来展望
随着技术的进步和数据的丰富,信用评分模型的未来发展方向包括:
- 人工智能与机器学习:利用深度学习等先进技术,构建更为复杂的模型,以捕捉数据中的潜在模式。
- 多维度数据融合:结合社交媒体数据、消费行为数据等多种数据源,提升信用评分的准确性和全面性。
- 实时信用评分:开发实时信用评分系统,根据借款人的实时行为动态调整信用评分,提供更为个性化的信贷服务。
通过以上步骤和措施,金融机构能够有效地利用信用评分模型来评估借款人的信用风险,从而优化信贷决策,降低违约风险,提高整体业务效率。
案例的具体数学模型
在信用评分模型的实施中,通常会使用一些数学模型来量化借款人的信用风险。以下是一个具体的数学模型示例,主要基于逻辑回归和随机森林这两种常用的模型。
1. 逻辑回归模型
逻辑回归是一种广泛使用的分类模型,适用于二分类问题(如违约与否)。其基本形式如下:
数学表达式

模型训练
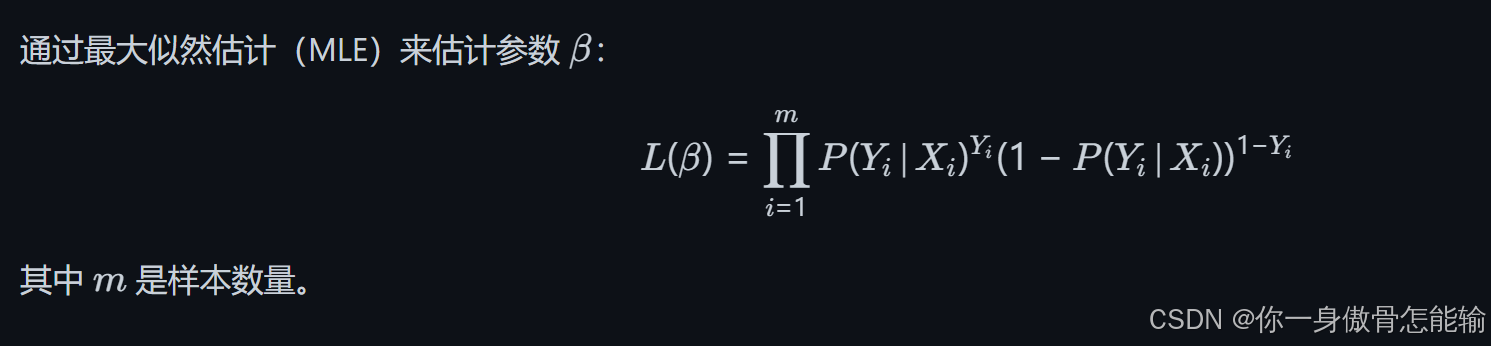
2. 随机森林模型
随机森林是一种集成学习方法,通过构建多个决策树来进行分类。其基本思想是通过投票机制来提高分类的准确性。
数学表达式

模型训练
- Bootstrap抽样:从训练数据集中随机抽取样本,构建每棵树的训练集。
- 特征选择:在每个节点分裂时,随机选择一部分特征进行分裂,增加模型的多样性。
- 决策树构建:构建多棵决策树,每棵树独立训练。
- 投票机制:对所有树的预测结果进行投票,最终输出类别。
3. 模型评估
无论是逻辑回归还是随机森林,模型评估通常使用以下指标:

- ROC曲线和AUC:通过绘制ROC曲线并计算AUC值来评估模型的分类性能。
4. 结论
通过上述数学模型,金融机构可以量化借款人的信用风险,并在信贷审批中做出更为科学的决策。逻辑回归提供了一个简单且可解释的模型,而随机森林则通过集成学习提高了模型的准确性和鲁棒性。根据具体的业务需求和数据特性,金融机构可以选择合适的模型进行信用评分。



















 3080
3080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











