






通过容损传输协议提升分布式机器学习训练水平
摘要
分布式机器学习(DML)系统可用于提高数据中心(DC)和边缘节点的模型训练速度。参数服务器(PS)通信架构被普遍采用,但它面临着多对一 “不同步 ”流量模式造成的严重长尾延迟,对训练吞吐量产生了负面影响。为了应对这一挑战,我们设计了容损传输协议(LTP),它允许在同步期间丢失部分梯度,以避免不必要的重传,并有助于加快每次迭代的同步速度。LTP 通过失序传输和失序确认 (ACK) 实现容损传输。LTP 采用 “早期关闭”(Early Close)技术,可根据网络条件调整容损阈值,并采用 “气泡填充”(bubble-filling)技术进行数据校正,以保持训练的准确性。LTP 由 C++ 实现,并集成到 PyTorch 中。在由 8 个工作节点和 1 个 PS 节点组成的测试平台上进行的评估表明,与传统的 TCP 拥塞控制相比,LTP 可显著提高 DML 训练任务吞吐量达 30 倍,而且不会牺牲最终准确性。
1 介绍
随着机器学习(ML)应用中数据集和模型规模的激增,分布式机器学习(DML)已被广泛采用,以在大规模训练中充分利用多个工作节点的力量。为了实现分布式工作节点之间的同步,人们提出了多种 DML 通信架构,如参数服务器架构(PS)[1] 和 Ring-AllReduce [2],从而提高了分布式训练系统的效率。
PS 架构因其简单高效,已成为 DML 中普遍使用的通信架构。在 PS 架构中,所有计算节点(也称为工作节点)都由一个或多个 PS 管理。工作节点学习部分训练数据集,并与相关 PS 通信,以便与其他工作节点同步训练结果(如图 1 所示)。在每次迭代中,每个工作节点都会使用部分数据集训练模型,并将计算出的梯度发送给 PS,PS 会汇总所有工作节点的梯度并更新全局模型。最后,PS 将最新模型发送给每个工作节点,为下一次迭代做好准备。多个工作节点的并行计算大大提高了模型训练过程的效率。
随着 DML 系统规模的扩大,连接工作节点和 PS 的网络正成为系统的主要限制因素。这主要有两个原因。首先,现有的大多数 DML 训练任务都使用批量同步并行(BSP)同步模型[3],其中所有节点都必须在每个训练批次结束时与 PS 完全同步梯度。这种多对一同播流量模式导致了长尾延迟问题[4],大大缩短了通信时间。其次,最近提出了几种基于 DML 的新方案,如跨数据中心的 ML[5]、边缘计算[6]、[7]和联合学习(FL)[8]。这些场景通常涉及在广域网(WAN)或无线网络上传输梯度,这就带来了链路不稳定的新挑战。因此,非拥塞数据包丢失在这些场景中很常见。例如,数据中心网络中的微突发流量[9]-[11]、物理链路故障(如光纤)[12]、[13]、边缘节点的无线链路[14]、[15]以及广域网中的重路由[16]都会导致非拥塞数据包丢失,并降低 PS 与工作节点之间的通信效率。Incast引起的长尾延迟和非拥塞数据包丢失严重降低了 DML 训练的效率。
目前解决由 incast 引起的长尾延迟问题的方案,如 pHost [17] 和 Homa [18],并不能满足 DML 训练的特殊要求,也不能有效处理非拥塞丢包问题。此外,DML 的数值分析过程允许一定程度的数据丢失。为了改进 DML 通信,人们提出了一些方法,如参数量化[19]、参数剪枝[20]、梯度压缩[21]和梯度量化[22]。这些方法旨在通过在应用层面优化通信过程,减少每次迭代传输的数据量。然而,这些解决方案仍有局限性,因为它们只能减少通信量,却不能从根本上解决同步过程中的长尾延迟问题。
本文提出了一种名为 “容损传输协议”(Losstolerant Transm ission Protocol,LTP)的新型解决方案,旨在提高 DML 训练任务的同步效率。该协议允许部分数据丢失(容损传输),同时同步系统中的梯度,这有助于缓解 DML 系统中常见的长尾延迟问题。LTP 通过使用失序传输和失序 ACK 实现了容损传输。为此,LTP 采用了一种早期关闭机制来确定容损传输的阈值,并使用气泡填充机制来防止数据错误。总而言之,我们的贡献是
- 我们提出了一种传输协议 LTP,它允许部分数据丢失,从而提高了 DML 训练的同步效率。我们设计了两种关键机制:提前关闭和气泡填充。提前关闭机制可以根据数据百分比和传输时间的预定阈值提前完成传输(我们称之为容损传输),而气泡填充机制则可以保持机器学习任务的正确性和准确性。基于带宽延迟积(BDP)的拥塞控制算法确保了各种网络条件下的高带宽利用率。
- 我们在 Linux 上用 C++ 实现了 LTP,并将其集成到广泛使用的 ML 框架 PyTorch 中。LTP 对 ML 框架是透明的,因此 DML 程序员无需更改他们的 ML 代码。要使用 LTP 作为通信协议,程序员只需简单修改套接字的接口即可
- 我们在由 8 个工作节点和 1 个 PS 节点组成的真实测试平台上评估了 LTP 在各种网络条件下的性能。我们使用流行的 ML 模型(如 ResNet50 和 VGG16)和 CIFAR10 数据集进行评估。评估结果表明,与传统的拥塞控制算法相比,LTP 的训练速度提高了 30 倍,而且没有精度损失。
2 背景和动机
2.1 网络成为 DML 扩展的限制因素
虽然近年来网络带宽增长迅速,但它仍然是 DML 训练的一个重要瓶颈。我们分别在 1 台、2 台、4 台和 8 台采用 PS 通信架构的机器上对 ResNet50 [23] 模型进行了 DML 训练评估。图 2 显示,随着计算节点的增加,DML 的训练效率确实有所提高(每个 epoch 的时间在减少),但额外的通信开销也在逐渐增加(通信时间与计算时间的比值在增加)。节点数量与它给整个训练时间带来的优化不成比例。
我们推测这是 PS 架构的内播流量造成的,即多个工作节点只与少数 PS 并行突发通信。虽然大多数节点几乎可以同时完成传输,但有些节点由于长期处于竞争关系,可能会受到拥塞窗口(cwnd)增长速度缓慢的影响。这些滞后流将减慢整体训练同步的速度,这在 DCN 和广域网中很常见。
我们做了另一个实验来说明长尾延迟的危害。在默认的 TCP 协议参数下,我们使用 8 个工作节点和 1 个 PS,以固定的报文大小建立多对一通信,并计算每个工作节点的流量完成时间。图 3 显示了 FCT(流量完成时间)的概率密度分布。我们可以看到,大多数流量的 FCT 分布相对相似,但仍有一些 “饥饿 ”流量的 FCT 相对较长。由于现有流行的 DML 训练任务仍然使用 BSP 同步模型,因此在所有工作节点完成同步之前,系统都会阻塞,从而减慢整个训练吞吐量。
2.2 TCP 在有损网络中表现不佳
经过几十年的发展,常用的 TCP 拥塞控制算法具有很强的鲁棒性。然而,这些拥塞控制算法在存在非拥塞丢包的网络环境中存在缺陷。我们利用现有流行的 TCP 拥塞控制算法,在不稳定的网络环境中测试点对点纯流量性能,并进行了多组实验来评估 TCP 在不稳定网络中的问题。我们分别在 DCN 和 WAN 中进行了这些实验。
图 4 是不同 TCP 拥塞控制算法在不同网络中的带宽利用率降低情况,从图中可以看出,传统的 TCP 拥塞控制算法在有数据包丢失的网络中表现较差,尤其是在带宽较高、延迟较低的网络中。虽然 BBR [24] 在丢包环境中表现较好,但与非拥塞丢包率相比,降低幅度更大。由于传统的 TCP 拥塞控制是有序保护的,并使用 3 个重复 ACK 作为瓶颈链路队列已满的信号来避免拥塞。LTP 不按顺序发送数据包,并使用与 BBR 类似的基于 BDP 的拥塞控制算法来维持链路利用率,其性能优于一般使用的拥塞控制方法。
2.3 可接受随机数据丢失造成的精度下降
DML 是一个由成百上千次迭代组成的数值分析过程,因此每次迭代过程中一定阈值的数据丢失不会影响模型的性能。基于这种损失容限特性,人们提出了许多方法来加快 DML 训练的效率。这些方法分为两大类,包括梯度量化和稀疏化 [25]。梯度量化方法使用低位浮点数来存储传输的数据,例如,一个 32 位浮动数可以用一个 8 位浮动数来近似,这样可以将通信成本降低四分之一。梯度稀疏化是从梯度向量中选择部分数据进行传输。Top-k [21] 算法只传输梯度向量中前 k 个大的绝对值。Random-k [26] 算法从梯度向量中随机传输一部分数据,与 Top-k 算法相比,减少了排序开销。这两种方法可以结合使用。例如,DGC [25] 将梯度稀疏化与热身训练 [27] 和动量校正等其他训练技巧结合起来。
虽然这些努力可以减少通信大小,但挑战依然存在:需要考虑的梯度阈值很复杂。例如,保持较小的通信量(丢弃尽可能多的梯度)可以减少每轮同步的完成时间,尤其是在网络性能较差的情况下。但缺点是可能会带来额外的计算开销,这甚至可能超过减少通信量带来的时间优化效果。
在上述方法中,Random-K 丢包法和 Top-K 丢包法是最常用的两种方法,它们各有优缺点。我们使用 ResNet18 模型和 CIFAR10 数据集[29]来探讨这个问题。我们保证 k% 的梯度是同步的,并比较了在 8 个工作节点和 1 个 PS 中随机丢弃 1-k% 梯度(Randomk)和保留前 k% 梯度(Top-k)在 top-1 精度和吞吐量上的差异。我们使用了 CUDA 内置的 topk 函数 [30],以确保 Top-k 算法足够高效。k 值范围为 5 至 40。结果(图 5)显示,Random-k 算法由于其简单性,可以达到相对较高的精度,并且具有更高的训练吞吐量。当 k≤ 70 时,Top-k 和 Random-k 的 top-1 准确率仅相差约 0.3%,但吞吐量却提高了约 25%。这为容错传输协议的设计提供了指导。
其他研究也提出了类似的结果[31]。LTP 的行为近似于阈值控制的 Random-k,这意味着 DML 训练的最终结果不会因为有限的随机数据丢弃而产生巨大影响。
3 LTP的设计
LTP 是一种用于各种网络环境下 DML 训练的容损传输协议。我们在设计 LTP 时遵循以下几个基本原则:
1)确保 LTP 的引入对现有 DML 训练同步的影响最小。
2) 减少因流量模式和非拥塞丢包造成的长尾延迟的危害。
3) 减少数据包丢失对传输窗口的影响,避免非拥塞原因造成的虚假链路拥塞信号。
设计概述:
1、如何支持丢失容忍的传输? Per-packet ACK、三次乱序 ACK 或 RTO 作为丢包信号、使用基于 BDP 的拥塞控制
2、如何降低拖尾者的影响? Early Close机制
3、如何在有限时间内尽可能传输重要的数据包? 三级 SP 队列调度控制报文优先,数据报文尽力而为
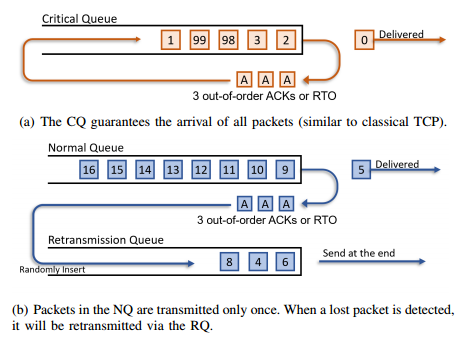
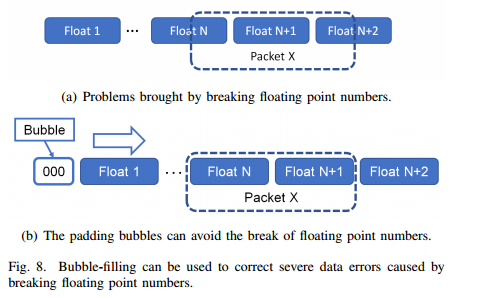
4、如何降低报文丢失对数据恢复的影响? Bubble-filling填充丢失报文、增加 Padding 避免浮点数错误
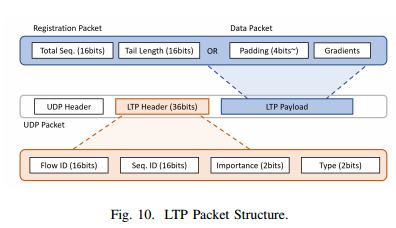
实际上,在 PS 架构中,DML 训练有两个过程,即收集(工作节点将其训练梯度发送给 PSes)和广播(PSes 聚合梯度,然后将其发送回工作节点)。这两个过程对数据丢失的容忍度不同。显而易见的是,收集过程允许数据丢失,而广播过程则不需要,原因分别是:1)DML 本身的特性;2)PS 架构导致的非同步流量模型。
从 DML 训练的特点来看,DML 训练带来的加速是将数据集由多个计算节点拆分,然后同时并行计算。因此,我们认为不同机器之间的 ML 模型应该是一致的,以避免全局模型混乱。例如,使用异步并行同步模型(ASP)[32] 的 DML 任务,由于无法保证工作节点间训练模型的同步性,因此存在最终训练精度低甚至无法收敛的问题。因此,容错传输只在收集过程中起作用,但能确保所有数据都在广播中传输。
从流量模式的角度看,广播阶段的流量不是资源竞争激烈的单播模式,而是一对多模式。这种流量模式不会造成长尾延迟,因此不需要提前关闭机制。
DML 中的许多梯度压缩方法都讨论了如何对不同数据进行排序的重要性。在 LTP 中,数据的重要性同样值得讨论。LTP 将不同的数据包分为两种优先级,以传输具有不同可靠性的数据包: 1) 关键数据包和 2) 正常数据包。LTP 决定接收器在传输过程中 100% 接收所有关键数据包,而正常数据包则可以部分丢弃。LTP 允许用户自定义选择关键数据包,同时只将最低数量的信息标记为关键信息。

















 4201
4201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









