







论文:
代码:https://github.com/mingdali6717/Ensemble-of-Retrievers
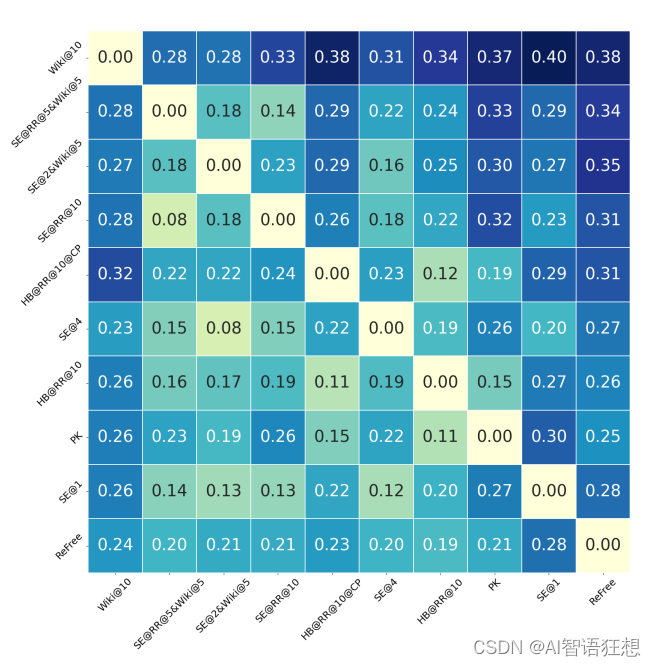 《Unraveling and Mitigating Retriever Inconsistencies in Retrieval-Augmented Large Language Models》详细探讨了检索增强型大型语言模型(RALMs)中的检索器(Retriever)不一致性问题,并提出了一种解决方案
《Unraveling and Mitigating Retriever Inconsistencies in Retrieval-Augmented Large Language Models》详细探讨了检索增强型大型语言模型(RALMs)中的检索器(Retriever)不一致性问题,并提出了一种解决方案
1. 研究背景与问题识别
- 背景:大型语言模型(LLMs)在许多自然语言处理(NLP)任务中表现出色,但在处理事实性错误和过时知识方面存在挑战。
- 问题:尽管RALMs通过检索外部知识源来缓解这些问题,但它们在示例级别的性能上并不总是优于原始的检索无关的语言模型(LMs),有时甚至会影响性能。
2. 检索器不一致性的观察
- 现象:作者观察到检索器之间的性能存在显著的不一致性,即使在检索增强和检索无关的LMs之间,以及不同检索器之间。
- 实验:通过构建15个不同的检索器,作者发现平均超过16%的问题可以由一个检索器纠正另一个检索器的错误。
3. 理论分析与错误分解
- 错误分解:作者将RALMs的退化行为分解为四类:检索器错误、提取错误、幻觉错误和幸运猜测。
- 原因分析:进一步分析发现,知识源的固有差异和读者模型的不可预测退化是检索器不一致性的主要原因。
4. 检索器集成框架(EoR)
- 提出:为了解决检索器不一致性问题,作者提出了一种名为“检索器集成”(EoR)的可训练框架。
- 工作原理:EoR通过从不同的知识源动态检索信息,并基于答案之间的相似性进行投票,以减少读者模型的错误。
5. 实验验证
- 实验设置:作者在三个英文开放域问答(ODQA)数据集上进行了实验,使用了不同的基础LMs。
- 结果:EoR显著提高了性能一致性,并在ODQA任务上比单一检索器RALM有更好的整体性能。
6. 框架优势与兼容性
- 优势:EoR框架与任何LLM兼容,无需对它们进行额外训练,通过引入控制参数,可以自动寻找最优的检索器组合。
- 优化问题:通过启发式搜索算法解决优化问题,以提高性能。
7. 相关工作
- 退化分析:论文回顾了关于RALMs性能退化的相关研究,并讨论了不同的失败原因。
- 缓解策略:探讨了提高检索召回率、增强读者模型的上下文利用能力或提高检索器精度等策略。
8. 结论与未来工作
- 结论:论文聚焦于RALMs的检索器不一致性问题,并通过EoR框架有效提升了性能。
- 未来工作:作者提出,尽管研究基于简单的单跳短形式问答设置,但结论和方法可以推广到更复杂的情况。
9. 限制与考量
- 限制:论文的理论推导和实证分析基于单跳短形式问答设置,对于多跳推理和长答案问题可能需要进一步的人类评估。
- 计算成本:EoR框架可能增加计算成本,但通过LLMs的批量推理和多检索器的并行化可以缓解这一问题。
















 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











