







- 论文:https://arxiv.org/pdf/2404.05961
- 代码:https://github.com/McGill-NLP/llm2vec
- 机构:McGill University, Mila ServiceNow Research ,Facebook CIFAR AI Chair
- 领域:embedding model
- 发表:COLM 2024
研究背景
- 研究问题:这篇文章要解决的问题是如何将解码器仅的语言模型(LLMs)有效地转换为强大的文本编码器。尽管LLMs在大多数自然语言处理(NLP)任务中表现出色,但社区对其在文本嵌入任务中的应用进展缓慢。
- 研究难点:该问题的研究难点包括:解码器仅的LLMs的因果注意力机制限制了它们生成丰富上下文表示的能力;需要在不依赖昂贵适应或合成数据的情况下实现参数高效的转换。
- 相关工作:该问题的研究相关工作有:传统的预训练双向编码器或编码器-解码器模型(如BERT和T5),这些模型通常通过多步骤训练管道进行适应;最近的研究开始探索解码器仅的LLMs在文本嵌入任务中的应用
研究方法
这篇论文提出了LLM2Vec,一种简单的无监督方法,可以将任何解码器仅的LLM转换为通用文本编码器。具体来说,LLM2Vec包括三个简单步骤:
- 启用双向注意力:通过替换解码器仅的LLM的因果注意力掩码为一个全1矩阵,使每个令牌能够访问序列中的每个其他令牌,从而将其转换为双向LLM。
- 掩码下一个令牌预测(MNTP):使用MNTP训练目标,结合下一个令牌预测和掩码语言建模。给定一个输入序列,随机掩盖一部分输入令牌,然后训练模型根据过去和未来的上下文预测被掩盖的令牌。重要的是,在预测位置i的掩码令牌时,基于前一个位置的令牌表示计算损失。
- 无监督对比学习:通过SimCSE应用无监督对比学习,生成同一句子的两种不同表示,并训练模型最大化这两种表示之间的相似性,同时最小化与其他句子表示的相似性。

实验设计
- 模型选择:实验使用了三种不同的解码器仅的LLMs,参数从1.3B到8B不等:S-LLaMA-1.3B、LLaMA-2-7B和Mistral-7B。
- 训练数据:使用英文维基百科数据进行MNTP和无监督SimCSE步骤的训练。具体来说,使用Wikitext-103数据集进行MNTP步骤,使用Gao等人发布的维基百科句子子集进行无监督SimCSE步骤。
- 训练过程:
- MNTP训练:随机掩盖输入序列的一部分令牌,使用LoRA进行微调,掩码概率分别为20%(S-LLaMA-1.3B、LLaMA-2-7B和Meta-LLaMA-3-8B)和80%(Mistral-7B)。
- 无监督SimCSE训练:对同一输入序列应用两次模型,使用独立采样的dropout掩码,训练模型最大化两次表示之间的相似性。
监督训练流程:
监督训练是通过以下步骤完成的:
数据准备:
- 使用E5数据集的公共部分进行训练。E5数据集包含约150万个样本,涵盖多种NLP任务。
模型初始化:
- 使用LoRA进行微调,初始权重从SimCSE权重中继承。
- MNTP LoRA权重合并到基础模型中,可训练LoRA权重使用SimCSE权重初始化。
训练过程:
- 训练模型1000步,批量大小为512。
- 使用Adam优化器,学习率为2e-4,前300步采用线性学习率预热。
- 训练过程中使用bfloat16量化、Flash Attention 2和梯度检查点等技术优化GPU内存消耗。
评估:
- 在MTEB基准上进行评估,比较不同模型在公开数据集上的表现。
- 结果表明,LLM2Vec模型在仅使用公开数据训练的模型中达到了最新的最佳性能。
结果与分析
-
词级任务评估:在词级任务(如分块、命名实体识别和词性标注)上,LLM2Vec转换的模型显著优于仅编码器模型。例如,在分块任务中,S-LLaMA-1.3B模型的改进幅度为5%。
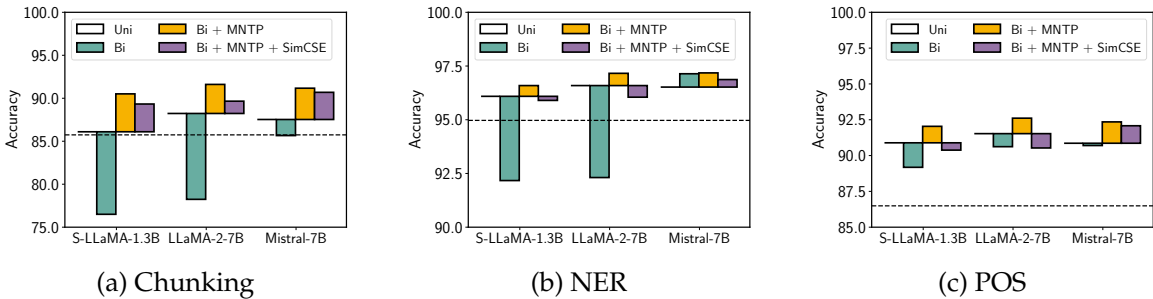
-
序列级任务评估:在Massive Text Embeddings Benchmark(MTEB)上,LLM2Vec转换的模型在无监督模型中达到了新的最佳性能,最佳模型的得分为56.8。结合监督对比学习后,Meta-LLaMA-3-8B模型在仅使用公开数据训练的模型中达到了最新的最佳性能。


3. 通过分析模型在不同层级的表示变化,发现Mistral-7B模型在无需任何训练的情况下就可以很好地处理双向注意力
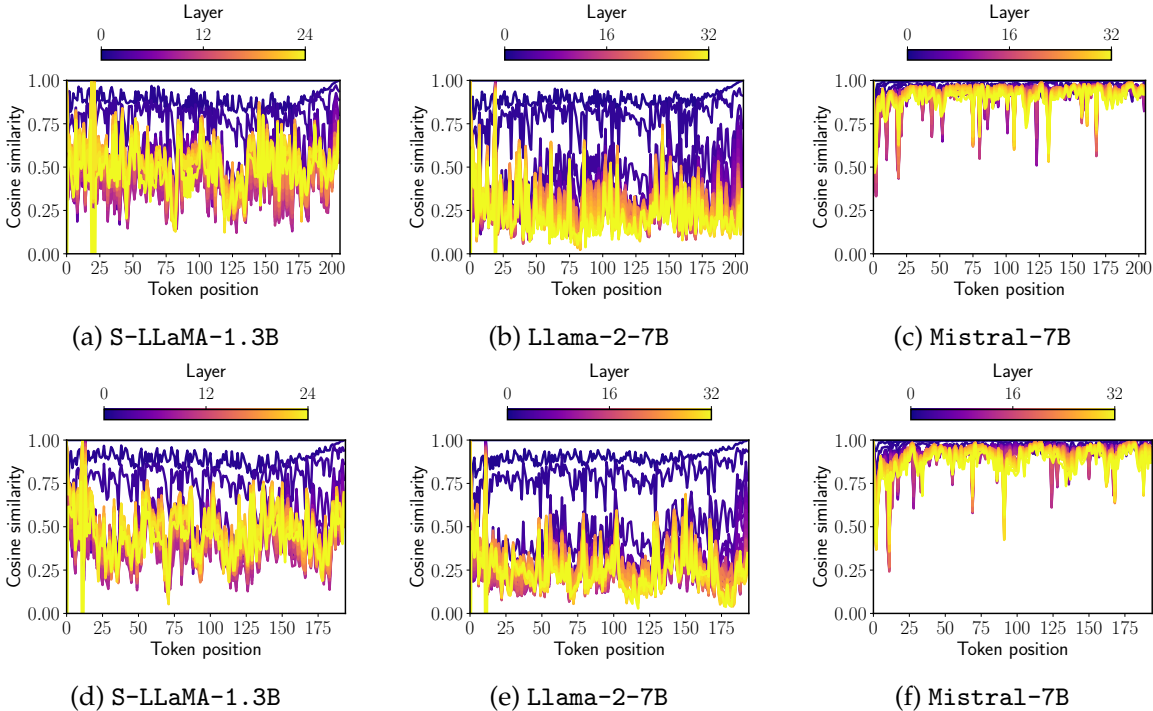
优点与创新
- 提出了LLM2Vec方法:LLM2Vec提供了一种简单且无监督的方法,可以将任何解码器仅语言模型(Decoder-only LLM)转换为强大的文本编码器。
- 有效提升模型性能:通过在多个流行的解码器仅LLM上应用LLM2Vec,研究者在词级任务和序列级任务上均取得了显著的性能提升。
- 无需标签数据:LLM2Vec不需要任何标注数据,具有高度的数据和参数效率。
- 新的无监督状态:在MTEB基准测试中,LLM2Vec转换的模型在无监督模型中达到了新的最佳水平。
- 结合监督对比学习:当将LLM2Vec与监督对比学习结合时,研究者在仅使用公开可用数据进行训练的模型中达到了最新的最佳性能。
- 广泛的分析:提供了对LLM2Vec如何影响底层模型的深入分析,并揭示了Mistral-7B的一个有趣特性,即该模型可以在不进行任何微调的情况下处理双向注意力。
不足与反思
- 大尺寸解码器仅LLM的挑战:近年来,训练非常大的解码器仅LLM的趋势日益明显,这些模型的参数规模和输出嵌入维度都较大,导致训练和推理延迟增加,内存和计算需求更高。
- 预训练数据的污染:尽管研究中使用的是公开可用的数据集,但仍有可能存在来自LLaMA-2-7B和Mistral-7B模型预训练数据的污染风险。
- 扩展到其他语言:目前的研究仅使用了英语文本语料库和基准测试,未来工作需要将LLM2Vec方法扩展到其他语言。
















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











