







Improving Transferable Targeted Adversarial Attacks with Model Self-Enhancement
本文 “Improving Transferable Targeted Adversarial Attacks with Model Self-Enhancement” 提出一种结合锐度感知自蒸馏(SASD)和权重缩放(WS)的模型自增强方法,以提升深度神经网络在目标对抗攻击中的迁移性,增强攻击成功率,同时通过实验验证了方法的有效性和优越性。
摘要-Abstract
Various transfer attack methods have been proposed to evaluate the robustness of deep neural networks (DNNs). Although manifesting remarkable performance in generating untargeted adversarial perturbations, existing proposals still fail to achieve high targeted transferability. In this work, we discover that the adversarial perturbations’ overfitting towards source models of mediocre generalization capability can hurt their targeted transferability. To address this issue, we focus on enhancing the source model’s generalization capability to improve its ability to conduct transferable targeted adversarial attacks. In pursuit of this goal, we propose a novel model self-enhancement method that incorporates two major components: Sharpness-Aware SelfDistillation (SASD) and Weight Scaling (WS). Specifically, SASD distills a fine-tuned auxiliary model, which mirrors the source model’s structure, into the source model while flattening the source model’s loss landscape. WS obtains an approximate ensemble of numerous pruned models to perform model augmentation, which can be conveniently synergized with SASD to elevate the source model’s generalization capability and thus improve the resultant targeted perturbations’ transferability. Extensive experiments corroborate the effectiveness of the proposed method. Notably, under the black-box setting, our approach can outperform the state-of-the-art baselines by a significant margin of 12.2% on average in terms of the obtained targeted transferability.
人们提出了各种迁移攻击方法来评估深度神经网络(DNN)的鲁棒性。尽管现有方法在生成无目标对抗扰动方面表现出色,但仍无法实现高目标迁移性。在这项工作中,我们发现对抗扰动对泛化能力一般的源模型的过拟合会损害其目标迁移性。为了解决这个问题,我们专注于增强源模型的泛化能力,以提高其进行可迁移目标对抗攻击的能力。为了实现这一目标,我们提出了一种新颖的模型自增强方法,该方法包含两个主要部分:锐度感知自蒸馏(SASD)和权重缩放(WS)。具体而言,SASD将经过微调且结构与源模型相同的辅助模型的知识蒸馏到源模型中,同时使源模型的损失曲面更加平坦。WS通过获取大量剪枝模型的近似集合来进行模型增强,它可以方便地与SASD协同工作,提升源模型的泛化能力,从而提高生成的目标扰动的迁移性。大量实验证实了所提方法的有效性。值得注意的是,在黑盒设置下,就获得的目标迁移性而言,我们的方法平均比最先进的基线方法高出12.2%.
引言-Introduction
这部分内容主要介绍了研究背景、提出的方法及主要贡献,具体如下:
- 研究背景:深度神经网络(DNNs)在现实场景应用广泛,但面对对抗扰动时存在脆弱性。近年来虽有许多迁移攻击方法评估其鲁棒性,在无目标迁移攻击方面表现优异,但实现目标迁移攻击仍颇具挑战。因为对抗扰动易对泛化能力一般的源模型过拟合,依赖模型特定特征生成的对抗样本难以在不同模型间有效迁移。
- 提出方法:为解决上述问题,文章提出增强源模型泛化能力来实现更具迁移性的目标对抗攻击。具体是提出一种新的模型自增强方法SASD-WS,融合Sharpness-Aware Self-Distillation(SASD)和Weight Scaling(WS)。SASD通过将微调后的辅助模型蒸馏到源模型中,使源模型损失景观更平坦;WS通过近似大量剪枝模型的集成进行模型增强,二者协同提升源模型泛化能力,进而增强目标扰动的迁移性。
- 主要贡献:一是提出了包含SASD和WS的模型自增强方法,促进源模型泛化能力提升,实现更具迁移性的目标对抗攻击;二是通过大量实验验证了该方法的优越性,在黑盒设置下,相比基准方法,目标攻击成功率平均显著提高12.2%;三是证实攻击在现实应用中迁移性良好,平均超越基准方法8.4%,还从增强模型损失景观等角度验证了方法有效性及对防御方法的对抗效果 。
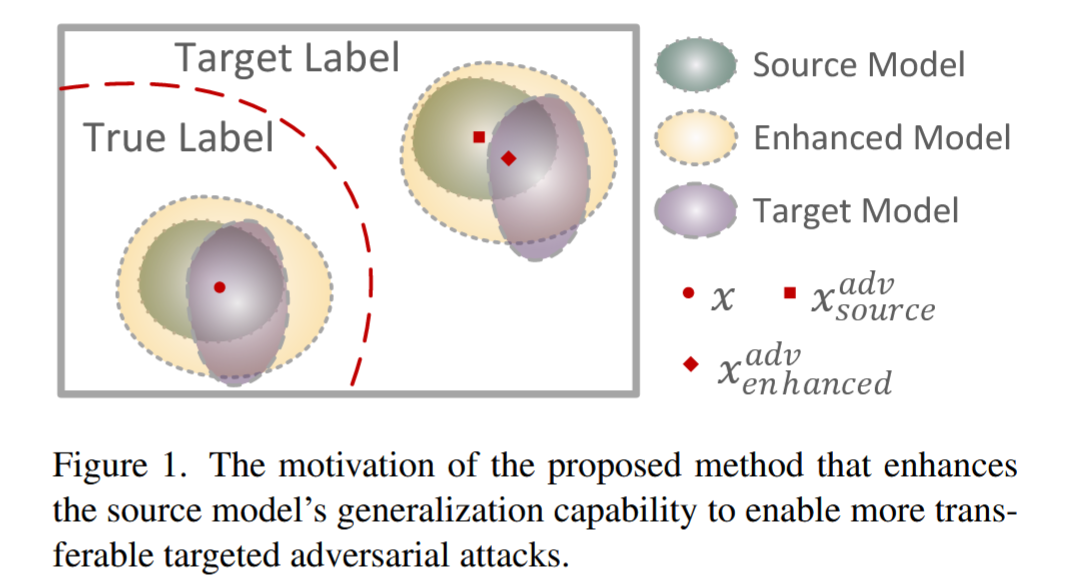
图1. 所提方法的动机,即增强源模型的泛化能力,以实现更具迁移性的目标对抗攻击。
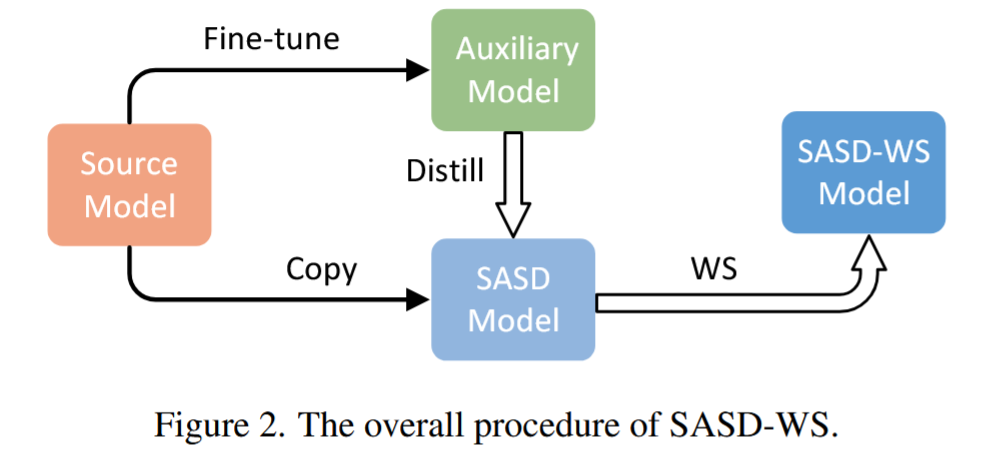
图2. SASD-WS的整体流程。
相关工作-Related Work
这部分主要回顾了可迁移对抗攻击和提高DNNs泛化能力两方面的相关工作,并指出本文方法与已有工作的联系和区别,具体内容如下:
- 可迁移对抗攻击:当前提升扰动迁移性的方法主要有三类。
- 增强源模型:部分模型增强方法旨在提升源模型进行目标迁移攻击的能力,如用随机失活得到的集成模型替代单一源模型、增加训练轮次,以及利用对抗微调增强源模型合成可迁移对抗样本的能力。本文同样通过增强源模型来提高对抗迁移性,但不同之处在于使源模型损失景观变平坦以提升其泛化能力,进而实现更有效的目标攻击。
- 扩充输入数据:一些迁移攻击方法通过输入扩充手段,像图像平移、随机缩放与填充、mixup等提升对抗迁移性。近期的频谱模拟攻击(SSA)则提出对输入进行频谱变换。
- 改进优化过程:相较于沿交叉熵损失梯度贪婪扰动干净图像,部分研究尝试改进优化过程以生成更具迁移性的对抗样本,如采用动量、Nesterov加速梯度,以及在攻击目标中加入中间特征损失来正则化对抗样本搜索。当前该类最先进的方法是反向对抗扰动(RAP),旨在寻找损失值均匀较低区域的对抗样本。本文攻击方法可与基于输入扩充和优化过程改进的方法相结合,进一步提升对抗攻击的迁移性。
- 提高DNNs泛化能力:Foret等人提出锐度感知最小化(SAM),通过同时最小化损失值和损失锐度来提升模型泛化能力。Hinton等人引入知识蒸馏,将教师模型的知识迁移到学生模型,Stanton等人发现知识蒸馏可增强学生模型的泛化能力。本文基于SAM和知识蒸馏方法,提出锐度感知自蒸馏(SASD),将两者相结合,进一步提高源模型的泛化能力,使生成的对抗样本更具目标迁移性。
方法-Methodology
问题阐述-Problem Formulation
这部分主要对目标迁移攻击进行了数学形式化定义,具体内容为:
- 攻击定义:在给定带标签图像数据集 D D D 和目标分类器 f t a r g e t f_{target} ftarget 的情况下,针对数据集中的图像 - 标签对 ( x , y ) (x, y) (x,y),目标迁移攻击的核心是生成对抗样本 x a d v = x + δ x_{adv}=x+\delta xadv=x+δ,以此误导目标分类器 f t a r g e t f_{target} ftarget 将其预测为特定的目标标签 y t a r g e t y_{target} ytarget,且 y t a r g e t ≠ y y_{target}≠y ytarget=y。
- 实现方式:因为目标分类器是黑盒模型,所以借助白盒源模型 f f f 来生成对抗样本。实现过程是通过优化 x a d v x_{adv} xadv,使得源模型在目标标签上的交叉熵损失 L C E L_{CE} LCE 达到最小,同时还要满足约束条件 ∥ δ ∥ ∞ ≤ ϵ \|\delta\|_{\infty} \leq \epsilon ∥δ∥∞≤ϵ 。这里, ∥ δ ∥ ∞ \|\delta\|_{\infty} ∥δ∥∞ 代表扰动 δ \delta δ 的 L ∞ L_{\infty} L∞ 范数,而 ϵ \epsilon ϵ 是预先设定的扰动预算,用来保证扰动 δ \delta δ 难以被察觉。
- 攻击目的:使用源模型生成的对抗样本 x a d v x_{adv} xadv 去攻击目标分类器,期望目标分类器的输出 f t a r g e t ( x a d v ) = y t a r g e t f_{target}(x_{adv}) = y_{target} ftarget(xadv)=ytarget,即成功让目标分类器将对抗样本误分类为目标标签。后续文章围绕增强源模型泛化能力,以提升生成的目标扰动的攻击成功率(迁移性)展开研究。
锐度感知自蒸馏-Sharpness-Aware Self-Distillation
这部分详细介绍了锐度感知自蒸馏(SASD)的实现过程,包括微调辅助模型和蒸馏辅助模型两个关键步骤,具体内容如下:
- 微调辅助模型:基于预训练的源模型,在其原始训练数据集上进行微调以得到辅助模型。微调过程遵循锐度感知最小化(SAM)方法,同时最小化损失值和损失锐度。在每次迭代中,首先根据辅助模型输出与真实标签之间的交叉熵损失进行反向传播;接着,通过添加能最大化交叉熵损失的扰动 ϵ m \epsilon_{m} ϵm 来修改辅助模型的权重 ω \omega ω,公式为 ϵ m = a r g m a x ϵ m L C E ( f ( ω + ϵ m , x ) , y ) \epsilon_{m}=\underset{\epsilon_{m}}{arg max } L_{CE}\left(f\left(\omega+\epsilon_{m}, x\right), y\right) ϵm=ϵmargmaxLCE(f(ω+ϵm,x),y);最后,基于扰动后的权重再次进行反向传播,以最小化辅助模型的损失锐度。
- 蒸馏辅助模型:获得微调后的辅助模型后,将其蒸馏到源模型中以增强源模型的泛化能力。
使源模型的概率输出接近辅助模型的概率输出,分别用 q 1 = ϕ 1 ( l a u x ) q_{1}=\phi_{1}(l_{aux }) q1=ϕ1(laux) 和 q 2 = ϕ 2 ( l s o u r c e ) q_{2}=\phi_{2}(l_{source }) q2=ϕ2(lsource) 表示辅助模型和源模型的概率输出,其中 ϕ 1 ( l a u x ) = S o f t m a x ( l a u x / τ ) \phi_{1}(l_{aux })=Softmax(l_{aux } / \tau) ϕ1(laux)=Softmax(laux/τ), ϕ 2 ( l s o u r c e ) = S o f t m a x ( l s o u r c e / τ ) \phi_{2}(l_{source })=\mathrm {Softmax}(l_{\mathrm {source}} / \tau ) ϕ2(lsource)=Softmax(lsource/τ), τ \tau τ 为蒸馏温度,温度越高,概率分布越平滑。
通过使用Kullback-Leibler散度 D K L D_{KL} DKL 衡量 q 1 q_{1} q1 和 q 2 q_{2} q2 之间的差异,将其作为蒸馏损失 L d i s t i l l a t i o n ( ω s ) = E ( x , y ) ∈ D [ D K L ( q 1 ( x , y ) , q 2 ( x , y ) ) ] L_{distillation }\left(\omega_{s}\right)=\mathbb{E}_{(x, y) \in D}\left[D_{KL}\left(q_{1}(x, y), q_{2}(x, y)\right)\right] Ldistillation(ωs)=E(x,y)∈D[DKL(q1(x,y),q2(x,y))]。然后同时最小化蒸馏损失及其锐度,即 m i n ω s E ( x , y ) ∈ D [ L ( ω s ) ] min _{\omega_{s}} \mathbb{E}_{(x, y) \in D}\left[L\left(\omega_{s}\right)\right] minωsE(x,y)∈D[L(ωs)] ,其中 L ( ω s ) = m a x ∥ ϵ ∥ 2 ≤ ρ L d i s t i l l a t i o n ( ω s + ϵ ) ≈ m a x ∥ ϵ ∥ 2 ≤ ρ [ L d i s t i l l a t i o n ( ω s ) + ϵ T ∇ ω s L d i s t i l l a t i o n ( ω s ) ] L\left(\omega_{s}\right)=max _{\| \epsilon\| _{2} \leq \rho} L_{distillation }\left(\omega_{s}+\epsilon\right) \approx max _{\| \epsilon\| _{2} \leq \rho}\left[L_{distillation }\left(\omega_{s}\right)+\epsilon^{T} \nabla_{\omega_{s}} L_{distillation }\left(\omega_{s}\right)\right] L(ωs)=max∥ϵ∥2≤ρLdistillation(ωs+ϵ)≈max∥ϵ∥2≤ρ[Ldistillation(ωs)+ϵT∇ωsLdistillation(ωs)]。算法1总结了SASD的整个过程,通过这一系列操作,SASD能有效使源模型的损失景观更平坦,提升生成的目标扰动的迁移性。

权重缩放-Weight Scaling
这部分主要介绍了权重缩放(WS)方法,通过网络剪枝和近似计算来提升模型泛化能力,进而增强对抗样本的目标迁移性,具体内容如下:
- 生成剪枝模型:为进一步提升SASD模型的泛化能力,采用网络剪枝方法生成剪枝后的SASD模型集合。具体操作是对得到的SASD模型的卷积层以 1 − p 1-p 1−p 的概率进行随机剪枝,剪枝后的模型权重 ω p r u n e d \omega_{pruned } ωpruned 通过公式 ω p r u n e d = ω ⊙ ( 1 − ξ ( ω , 1 − p ) ) \omega_{pruned }=\omega \odot(1-\xi(\omega, 1-p)) ωpruned=ω⊙(1−ξ(ω,1−p)) 计算,其中 ⊙ \odot ⊙ 表示Hadamard乘积(逐元素相乘), ξ ( ω , 1 − p ) \xi(\omega, 1-p) ξ(ω,1−p) 表示在卷积层中随机选择要剪枝的权重,通过该操作可使卷积层中的部分权重置零,得到剪枝模型。
- 近似集成模型:受相关研究启发,利用权重缩放的单个模型来近似剪枝模型的集成。对于多个结构相同但权重不同的模型 f ( ω i ) f(\omega_{i}) f(ωi),其集成模型 f ˉ = 1 n ∑ i = 1 n f ( ω i ) \bar{f}=\frac{1}{n} \sum_{i=1}^{n} f(\omega_{i}) fˉ=n1∑i=1nf(ωi),平均权重为 ω ˉ = 1 n ∑ i = 1 n ω i \bar{\omega}=\frac{1}{n} \sum_{i=1}^{n} \omega_{i} ωˉ=n1∑i=1nωi,权重差异 η i = ω i − ω ˉ \eta_{i}=\omega_{i}-\bar{\omega} ηi=ωi−ωˉ。当剪枝概率 1 − p 1-p 1−p 较小时,无限个剪枝后的SASD模型的集成可以用一个权重按比例 p p p 缩放的SASD模型(即SASD-WS模型)来近似,公式为 f ‾ ≈ f ( ω ‾ , x ) = f ( p ⋅ ω S A S D , x ) = f S A S D − W S \overline{f} \approx f(\overline{\omega}, x)=f\left(p \cdot \omega^{SASD}, x\right)=f_{SASD-WS} f≈f(ω,x)=f(p⋅ωSASD,x)=fSASD−WS。这表明在一定条件下,权重缩放的模型能有效替代剪枝模型的集成,方便后续计算且提升了模型的泛化能力,从而增强了合成的对抗样本的目标迁移性。
攻击算法-Attacking Algorithm
这部分主要介绍了基于SASD-WS模型生成目标对抗样本的攻击算法,具体内容如下:
在获得SASD-WS模型后,使用TI-DI-MI方法来生成有针对性的对抗样本。给定输入数据
x
x
x、源模型
f
f
f 和目标类别
y
t
a
r
g
e
t
y_{target}
ytarget,通过以下公式迭代更新扰动
δ
i
+
1
\delta_{i+1}
δi+1:
δ
i
+
1
=
C
l
i
p
δ
i
ϵ
p
{
δ
i
+
α
⋅
s
i
g
n
(
g
i
+
1
)
}
\delta_{i+1}=Clip_{\delta_{i}}^{\epsilon_{p}}\left\{\delta_{i}+\alpha \cdot sign\left(g_{i+1}\right)\right\}
δi+1=Clipδiϵp{δi+α⋅sign(gi+1)}
g
i
+
1
=
g
i
+
W
⋅
∇
δ
L
(
D
I
(
x
+
δ
i
)
,
y
t
a
r
g
e
t
;
f
)
∥
L
(
D
I
(
x
i
+
δ
i
)
,
y
t
a
r
g
e
t
;
f
)
∥
1
g_{i+1}=g_{i}+W \cdot \nabla_{\delta} \frac{\mathcal{L}\left(DI\left(x+\delta_{i}\right), y_{target } ; f\right)}{\left\| \mathcal{L}\left(DI\left(x_{i}+\delta_{i}\right), y_{target } ; f\right)\right\| _{1}}
gi+1=gi+W⋅∇δ∥L(DI(xi+δi),ytarget;f)∥1L(DI(x+δi),ytarget;f)
其中,
α
\alpha
α 是攻击步长,
W
W
W 是用于图像平移的高斯核,
L
\mathcal{L}
L 是攻击目标函数,
D
I
DI
DI 表示随机缩放和填充的输入变换。生成的对抗扰动受最大扰动预算
ϵ
p
\epsilon_{p}
ϵp 的限制,在
l
∞
l_{\infty}
l∞ 范数下有界 。通过这种迭代更新的方式,利用SASD-WS模型生成能够误导目标模型输出目标标签的对抗样本,实现目标对抗攻击。
实验-Experiments
这部分主要通过一系列实验,对提出的SASD-WS方法进行了全面评估,涵盖实验设置、攻击性能、消融研究和进一步分析等方面,具体内容如下:
-
实验设置:以在ImageNet数据集上训练的图像分类器为攻击对象,对8种预训练模型应用SASD-WS方法。设置SASD的蒸馏温度 τ = 1 \tau = 1 τ=1、学习率 l r = 0.05 lr = 0.05 lr=0.05,WS的缩放比例 p = 0.93 p = 0.93 p=0.93。将该方法与GhostNet、LGV、RAP等先进方法对比,按原文默认设置实现基线方法。设置攻击步长 α = 2 / 255 \alpha = 2 / 255 α=2/255、最大扰动预算 ϵ p = 16 / 255 \epsilon_{p}=16 / 255 ϵp=16/255、最大迭代次数 t m a x = 100 t_{max } = 100 tmax=100,在NIPS17目标对抗攻击竞赛数据集上进行实验,使用PyTorch 2.0.1和NVIDIA GeForce RTX 4090 GPU。
-
攻击性能
-
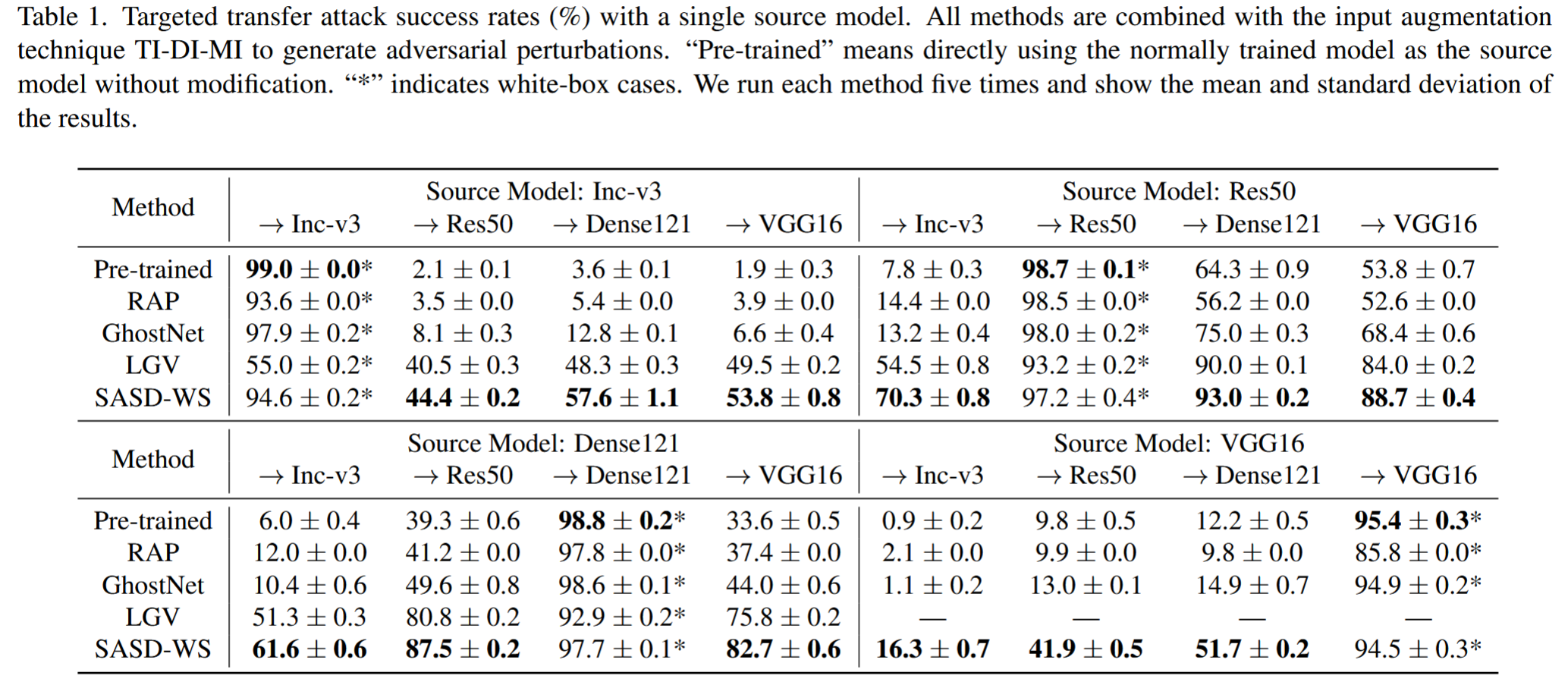
单源模型攻击:使用logit损失作为攻击目标函数,结果显示SASD-WS方法在黑盒设置下平均比基线方法的攻击成功率高12.2%,且能保持较高的白盒攻击性能。
表1. 单源模型的目标迁移攻击成功率(%)。所有方法均与TI - DI - MI输入增强技术相结合来生成对抗扰动。“预训练”是指直接将正常训练的模型用作源模型,不做任何修改。“*”表示白盒情况。我们对每种方法运行五次,并展示结果的平均值和标准差。
-
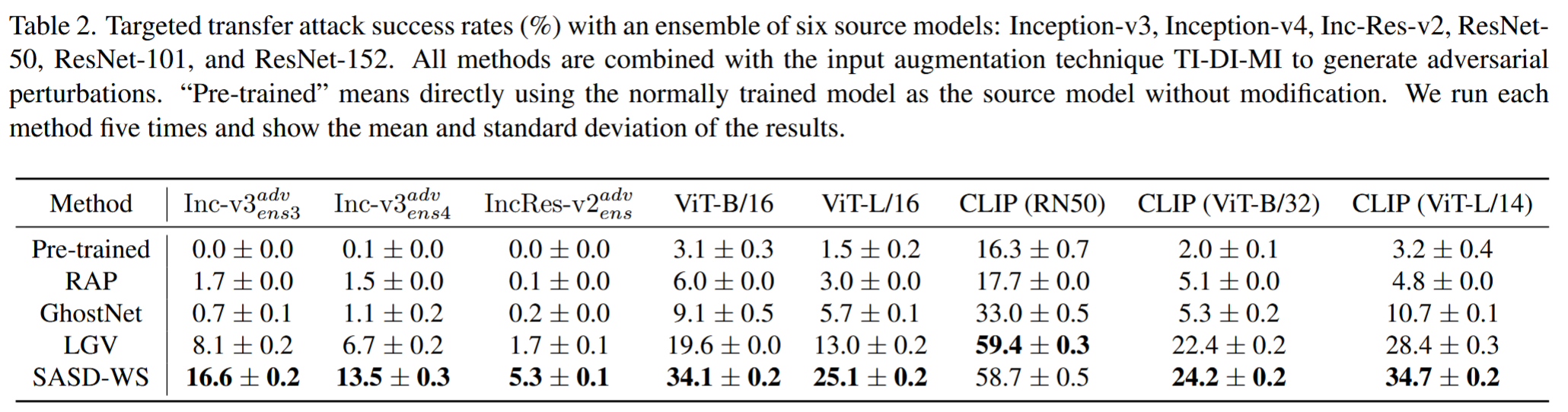
多源模型攻击:以Inception-v3等6种模型为源模型,对不同类型目标模型(包括对抗训练模型、Vision Transformers和CLIP模型)进行攻击,使用交叉熵损失作为攻击目标函数。结果表明,SASD-WS生成的对抗扰动迁移性更强,平均攻击成功率比其他基线方法提高6.6%,而RAP在多源模型设置下表现较差。
表2. 使用六个源模型(Inception-v3、Inception-v4、Inception-ResNet-v2、ResNet 50、ResNet-101和ResNet-152)的集成进行目标迁移攻击的成功率(%)。所有方法都与输入增强技术TI-DI-MI相结合以生成对抗扰动。“预训练”是指直接使用正常训练的模型作为源模型,不做任何修改。我们对每种方法运行五次,并展示结果的平均值和标准差。
-
-
消融研究
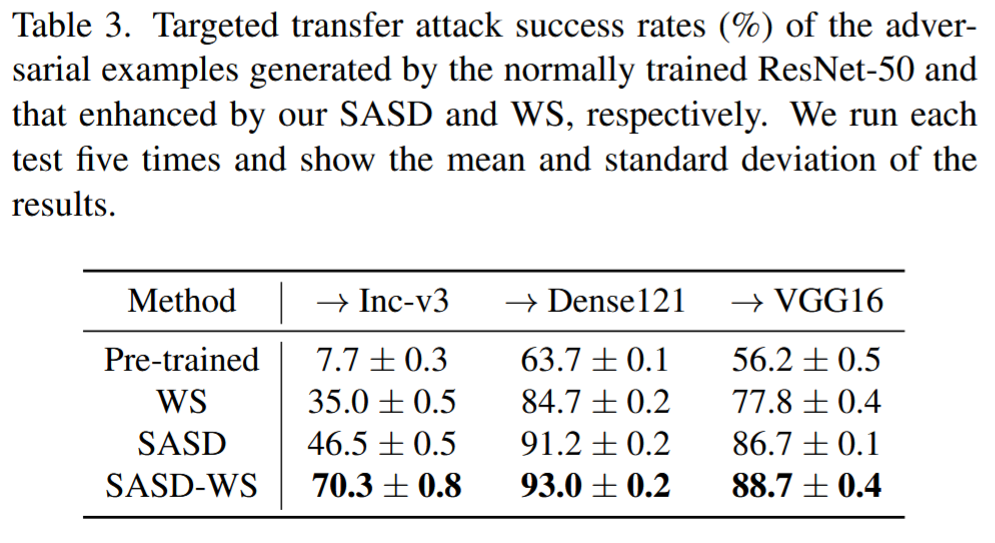
- 验证SASD和WS的贡献:对比正常训练的ResNet-50模型和经SASD、WS增强后模型生成的对抗样本的目标攻击成功率,发现SASD和WS都能提升源模型发起目标迁移攻击的能力,二者结合效果更佳。
表3. 分别由正常训练的ResNet-50以及经我们的SASD和WS增强后的ResNet-50生成的对抗样本的目标迁移攻击成功率(%)。我们对每次测试进行了五次运行,并展示了结果的平均值和标准差。
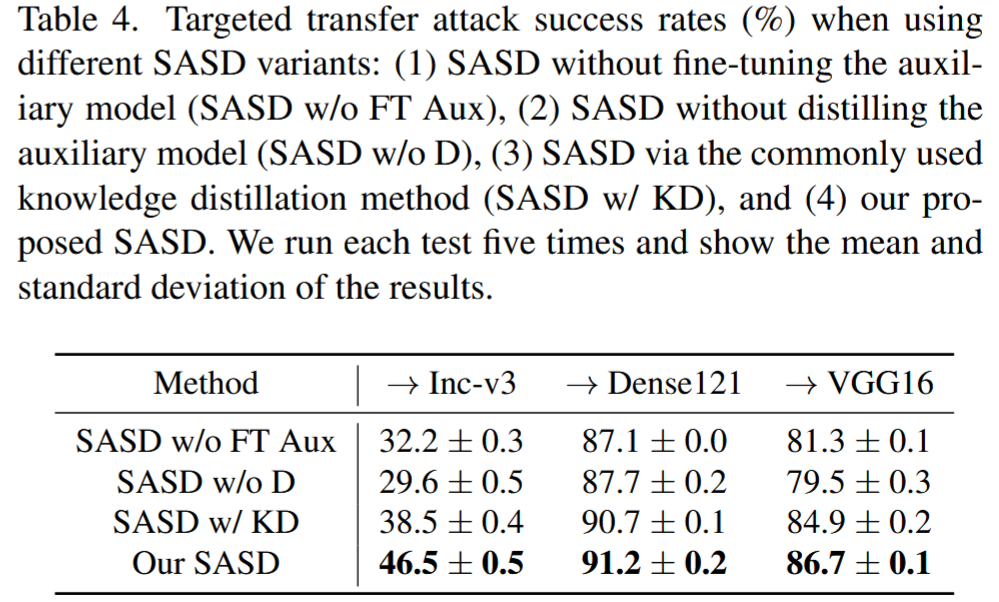
- 验证SASD的设计:通过研究SASD的两个关键步骤(微调辅助模型和蒸馏辅助模型),对比不同SASD变体生成的对抗扰动性能。结果表明,使用微调辅助模型和蒸馏辅助模型能提升SASD模型性能,且本文的SASD方法优于常用的知识蒸馏方法。
表4. 使用不同SASD变体时的目标迁移攻击成功率(%):(1)未对辅助模型进行微调的SASD(SASD w/o FT Aux),(2)未对辅助模型进行蒸馏的SASD(SASD w/o D),(3)采用常用知识蒸馏方法的SASD(SASD w/ KD),以及(4)我们提出的SASD。我们对每个测试进行了五次运行,并展示了结果的平均值和标准差。
- 验证SASD和WS的贡献:对比正常训练的ResNet-50模型和经SASD、WS增强后模型生成的对抗样本的目标攻击成功率,发现SASD和WS都能提升源模型发起目标迁移攻击的能力,二者结合效果更佳。
-
进一步分析
-
对抗防御方法的攻击:评估SASD-WS对JPEG、HGD、NRP、NoisyMix和AugMix等防御方法的攻击性能。结果显示,该方法能有效生成针对这些防御方法的有效扰动,在攻击JPEG时接近100%成功,在攻击NoisyMix和AugMix时也比其他基线方法表现更好。
表5. 针对不同防御方法的目标迁移攻击成功率(%)。所有方法均结合TI-DI-MI技术生成对抗扰动。我们对每个测试运行5次,并展示结果的平均值和标准差。

-
攻击真实应用:对Google Cloud Vision发起目标迁移攻击,以验证方法的实际适用性。实验结果表明,SASD-WS的攻击成功率达40.2%,远超基线方法。

图3. 在谷歌云视觉服务上成功的目标对抗样本示例。目标类别是老虎。 -
验证WS:计算剪枝模型集成与WS模型的logit输出差异的 l 2 l_{2} l2 范数,以及剪枝模型logit输出的标准差,结果表明WS模型输出接近剪枝模型集成输出,能合理近似集成模型。对比单权重缩放的SASD模型和剪枝SASD模型集成的目标攻击性能,进一步验证了WS方法的有效性。
表6. 对100张图像的平均 l 2 l_{2} l2 范数进行比较:(1)剪枝模型集合与相应WS模型的对数几率(logit)输出差异;(2)剪枝模型集合中各模型对数几率输出之间的标准差。报告了由20个/50个/100个剪枝模型组成集合的结果。
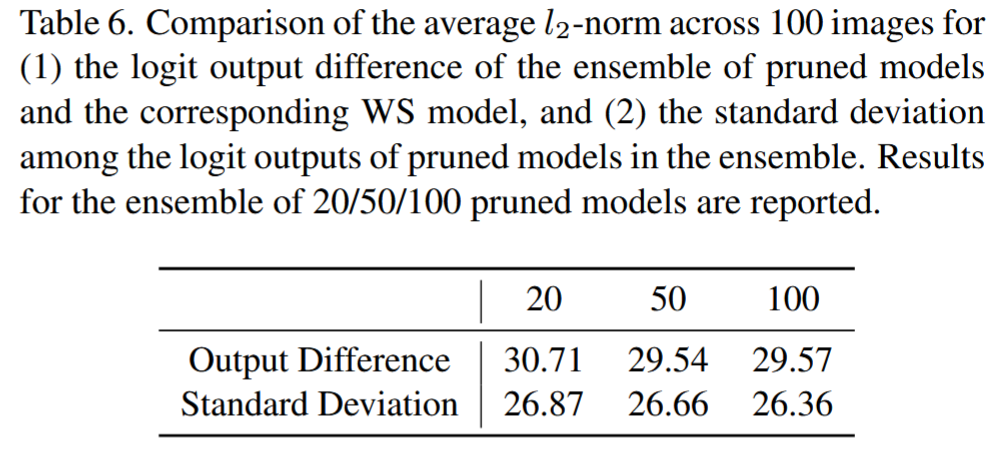
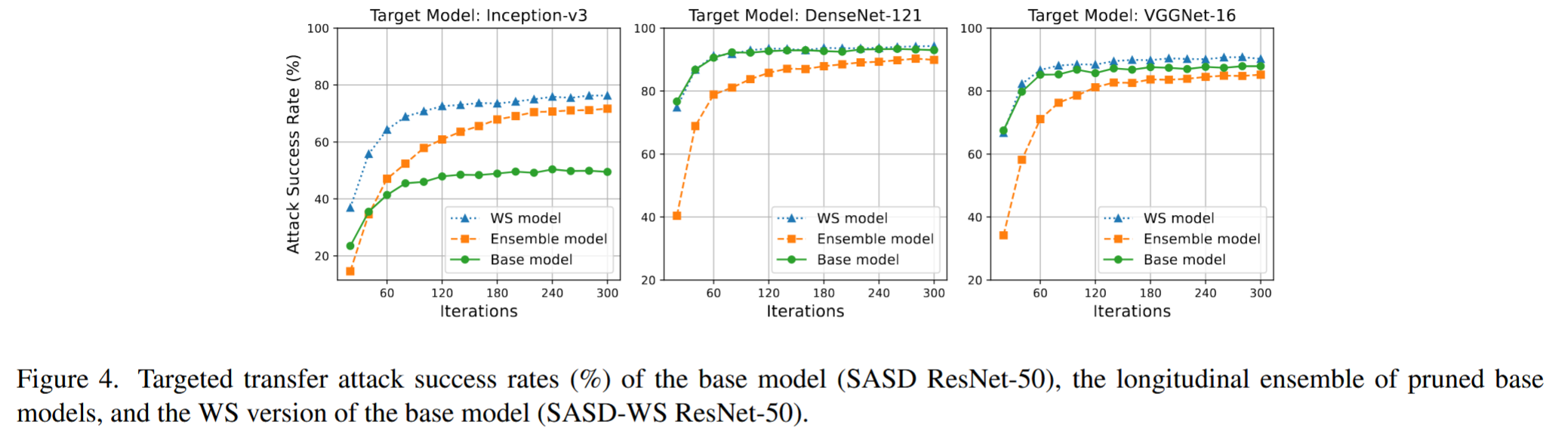
图4. 基础模型(SASD ResNet-50)、剪枝基础模型的纵向集成模型,以及基础模型的WS版本(SASD-WS ResNet-50)的目标迁移攻击成功率(%)。 -
可视化SASD-WS的有效性:绘制应用方法前后模型损失景观的变化,发现应用SASD-WS后,增强模型的损失景观更平坦,有助于捕捉不同模型学习的通用特征,促进更具迁移性的目标对抗攻击。
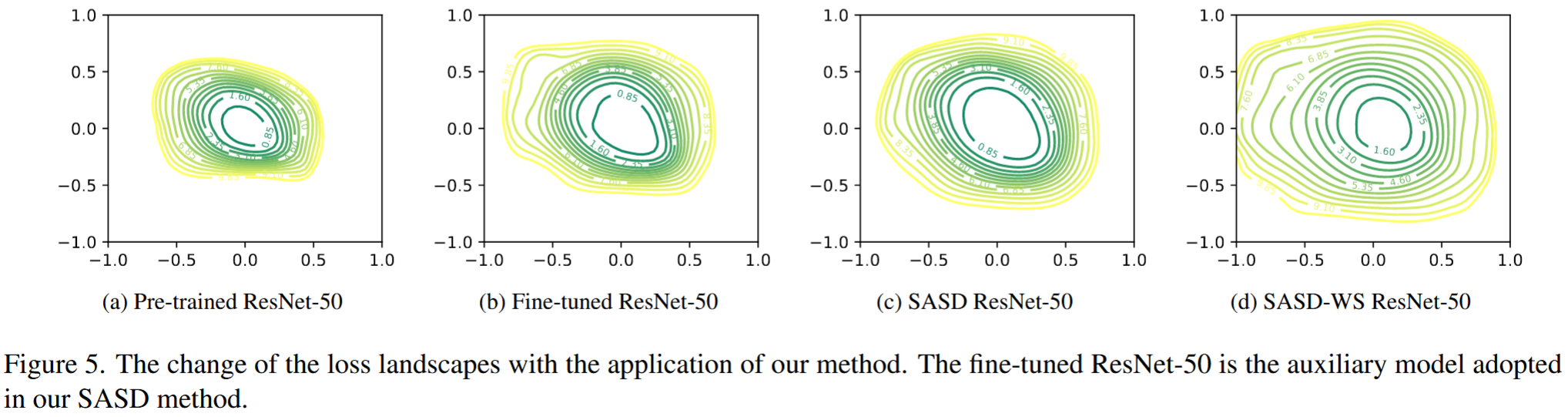
图5. 应用我们的方法后损失景观的变化。微调后的ResNet-50是我们的SASD方法中采用的辅助模型。
-
结论-Conclusion
在论文的结论部分,作者总结了研究成果、验证结果以及该研究的意义,具体内容如下:
- 研究成果:提出了一种全新的模型自增强方法,该方法融合了锐度感知自蒸馏(SASD)和权重缩放(WS)技术,显著提升了源模型生成更具迁移性的目标扰动的能力。
- 验证结果:大量实验表明,该方法在性能上明显超越了当前最先进的方法。在黑盒攻击场景下,平均能比现有基线方法高出12.2%的攻击成功率,展现出强大的优势。通过消融实验,进一步验证了所提方法设计的合理性与有效性。同时,通过对实际应用的攻击测试,证明了该方法在实际场景中的适用性。
- 研究意义:该研究成果在评估深度神经网络(DNN)的鲁棒性方面,可作为有力的基准,为后续研究提供重要参考。在对抗训练中,也可作为有效的手段,助力提升模型对抗攻击的能力,对增强DNN的安全性和可靠性具有重要意义。


















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











