







Adversarial Attacks on Event-Based Pedestrian Detectors: A Physical Approach
本文 “Adversarial Attacks on Event-Based Pedestrian Detectors: A Physical Approach” 提出一种端到端的对抗攻击框架,研究基于事件的行人检测器在物理对抗攻击下的安全性,通过数字域优化纹理并在现实场景中验证,证明了此类模型存在安全漏洞。
摘要-Abstract
Event cameras, known for their low latency and high dynamic range, show great potential in pedestrian detection applications. However, while recent research has primarily focused on improving detection accuracy, the robustness of eventbased visual models against physical adversarial attacks has received limited attention. For example, adversarial physical objects, such as specific clothing patterns or accessories, can exploit inherent vulnerabilities in these systems, leading to misdetections or misclassifications. This study is the first to explore physical adversarial attacks on event-driven pedestrian detectors, specifically investigating whether certain clothing patterns worn by pedestrians can cause these detectors to fail, effectively rendering them unable to detect the person. To address this, we developed an end-to-end adversarial framework in the digital domain, framing the design of adversarial clothing textures as a 2D texture optimization problem. By crafting an effective adversarial loss function, the framework iteratively generates optimal textures through backpropagation. Our results demonstrate that the textures identified in the digital domain possess strong adversarial properties. Furthermore, we translated these digitally optimized textures into physical clothing and tested them in realworld scenarios, successfully demonstrating that the designed textures significantly degrade the performance of event-based pedestrian detection models. This work highlights the vulnerability of such models to physical adversarial attacks.
事件相机以其低延迟和高动态范围而闻名,在行人检测应用中展现出巨大的潜力。然而,尽管近期的研究主要集中在提高检测精度上,但基于事件的视觉模型对物理对抗攻击的鲁棒性却受到了较少关注。例如,对抗性物理实体,如特定的服装图案或配饰,能够利用这些系统的固有漏洞,导致误检测或误分类。本研究首次探索了对基于事件驱动的行人检测器的物理对抗攻击,具体研究行人所穿的某些服装图案是否会导致这些检测器失效,使其无法有效地检测到行人。为了解决这个问题,我们在数字领域开发了一个端到端的对抗框架,将对抗性服装纹理的设计构建为一个二维纹理优化问题。通过精心设计有效的对抗损失函数,该框架通过反向传播迭代生成最优纹理。我们的结果表明,在数字领域识别出的纹理具有很强的对抗性。此外,我们将这些经过数字优化的纹理转化为实际的服装,并在现实场景中进行测试,成功证明了所设计的纹理显著降低了基于事件的行人检测模型的性能。这项工作突出了此类模型在物理对抗攻击下的脆弱性。
引言-Introduction
在行人检测应用场景中,传统相机存在明显不足,事件相机展现出独特优势,但相关模型的安全性研究存在空白。本研究针对这一现状,开展对基于事件的行人检测器的物理对抗攻击研究,具有重要的现实意义和创新性。
- 事件相机在行人检测中的优势与研究现状:传统相机因存在较大的帧延迟,不适用于交通场景下行人检测这类对实时感知和快速响应要求较高的应用。相比之下,事件相机凭借其异步触发机制,具备微秒级的超低延迟和大于120dB的宽动态范围,在行人检测任务中优势明显。近年来,基于深度学习的事件相机行人检测研究备受关注,随着大规模数据集的出现和网络架构的创新,检测精度不断提升。然而,当前研究主要聚焦于提高检测性能,对基于事件的行人检测器潜在的脆弱性关注较少。
- 基于事件的行人检测器的安全问题与研究方向:鉴于基于深度学习的事件相机行人检测模型,以及深度学习模型在RGB领域已被证实存在安全漏洞,推测此类检测器可能也有类似弱点。以往研究多关注数字对抗攻击,本研究首次探索物理对抗攻击对基于事件的行人检测模型的影响,具体考察行人服装风格如何影响检测模型的性能,旨在设计出能欺骗检测器的服装纹理,使穿着者不被检测到。
- 研究方法与贡献:为模拟真实场景,开发端到端数字对抗攻击框架,利用3D可微渲染技术将物理攻击的对抗纹理设计转化为2D纹理优化问题,通过精心设计损失函数并借助反向传播迭代生成最优2D纹理。将数字域优化后的纹理应用到现实场景进行实验,成功实现物理对抗攻击。本研究首次验证基于事件的视觉中物理对抗攻击的存在;开发的框架为物理对抗攻击提供有效手段;实验证明方法有效,凸显基于事件的行人检测器在物理对抗攻击下的脆弱性。
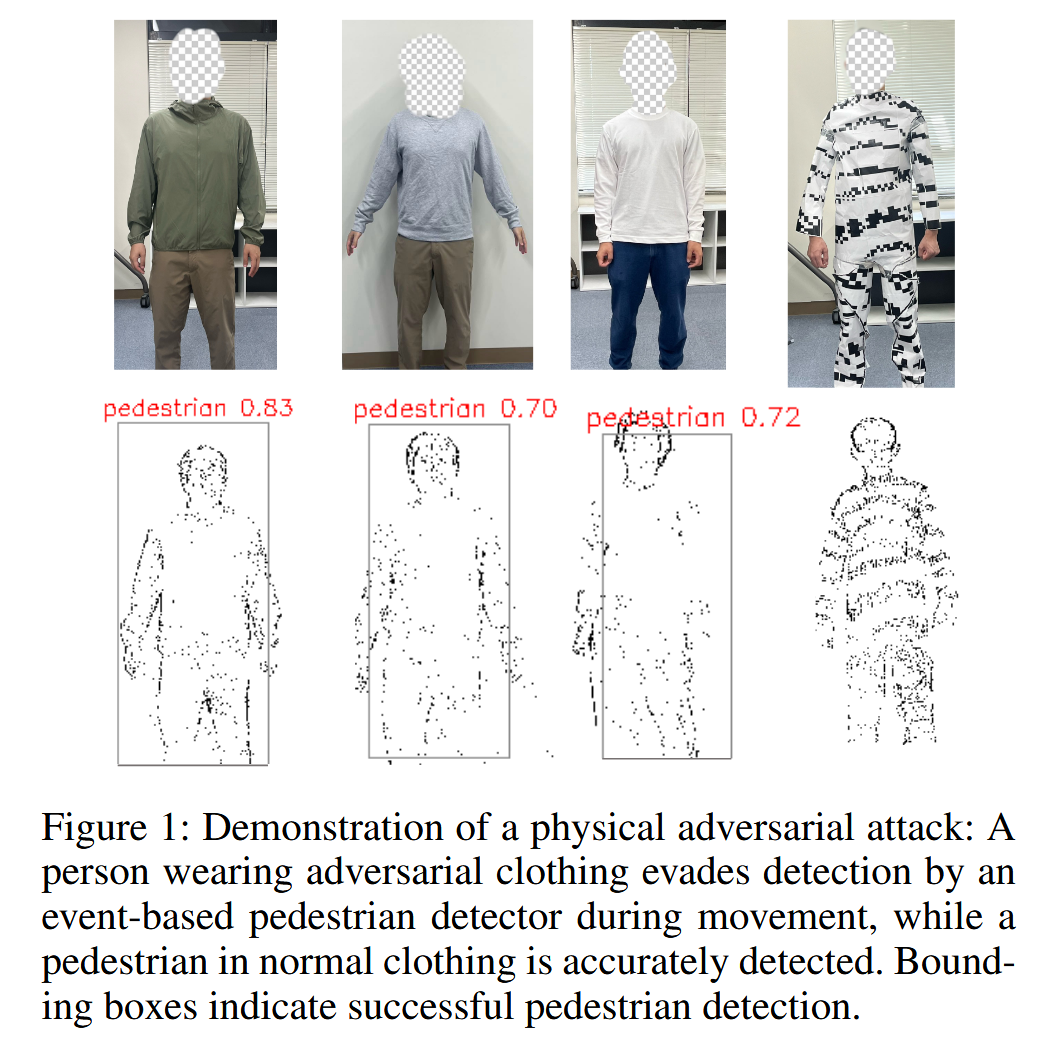
图1:物理对抗攻击示例:一名穿着对抗性服装的人在移动过程中避开了基于事件的行人检测器的检测,而穿着普通服装的行人则被准确检测到。边界框表示行人被成功检测到。
相关工作-Related Work
该部分主要介绍了物理对抗攻击和基于事件的视觉对抗攻击两方面的研究现状,为后续研究提供了背景和基础,具体内容如下:
- 物理对抗攻击:基于深度学习的视觉模型易受对抗攻击,攻击者在数字域对模型输入进行细微扰动,会大幅改变模型输出结果。随着研究深入,物理世界中的对抗攻击受到关注,这种攻击将扰动施加于现实中的物体或环境,能适应光照、视角和距离等现实变化,进而在实际场景中影响视觉AI模型。常见的物理攻击形式包括对抗图块和贴纸,根据对目标模型的了解程度,可分为白盒攻击和黑盒攻击。白盒攻击需详细知晓模型架构和参数,以设计高效的对抗扰动;黑盒攻击则通过探测模型对不同输入的响应来生成扰动,无需了解模型内部细节。本文采用白盒攻击方式开展研究。
- 基于事件的视觉对抗攻击:多数对抗攻击研究集中于RGB模型,对热红外视觉、近红外视觉和基于事件的视觉等其他模态视觉AI系统的脆弱性探索较少。基于事件的视觉因其异步、高时间分辨率的特性,为对抗攻击研究带来独特的挑战与机遇。虽有针对脉冲神经网络(SNNs)的对抗攻击研究适用于事件数据,但本文聚焦于基于事件数据的深度学习模型的对抗攻击。Marchisio等人通过将基于事件的数据投影到2D图像生成对抗图像,但该方法间接处理事件数据,在现实场景中的有效性和适用性受限。Lee等人开发了针对基于事件模型的对抗攻击算法,在数字域对事件数据进行扰动并在N - Caltech101数据集上测试成功,但这些研究均未涉及物理手段。本文则将基于事件的视觉对抗攻击拓展到物理领域,针对行人检测任务设计对抗服装纹理,验证物理对抗攻击在基于事件的视觉系统中的可行性和有效性。
方法-Methodology
阐述-Formulation
该部分主要对事件表示和问题定义进行了阐述,具体内容如下:
- 事件表示:事件流由一系列事件构成,每个事件 e i e_{i} ei 由位置 ( x i , y i ) (x_{i}, y_{i}) (xi,yi)、时间戳 t i t_{i} ti 和极性 p i p_{i} pi 表征。当像素强度对数变化超过正负对比度阈值时分别触发正负事件,本文将正负对比度阈值统一记为 θ \theta θ. 借鉴RVT中的方法,在时间区间 [ t 1 , t 2 ) [t_{1}, t_{2}) [t1,t2) 内,事件流 E E E 可表示为公式 E ( p , τ , x , y ) = ∑ e i ∈ E δ ( p − p i ) δ ( x − x i , y − y i ) δ ( τ − τ i ) E(p, \tau, x, y)=\sum_{e_{i} \in E} \delta\left(p - p_{i}\right) \delta\left(x - x_{i}, y - y_{i}\right) \delta\left(\tau - \tau_{i}\right) E(p,τ,x,y)=∑ei∈Eδ(p−pi)δ(x−xi,y−yi)δ(τ−τi),其中 τ i = ⌊ t i − t 1 t 2 − t 1 ⋅ B ⌋ \tau_{i}=\left\lfloor\frac{t_{i}-t_{1}}{t_{2}-t_{1}} \cdot B\right\rfloor τi=⌊t2−t1ti−t1⋅B⌋, B B B 为离散时间区间, δ ( x ) \delta(x) δ(x) 为狄拉克 δ δ δ 函数。
- 问题定义:用
f
f
f 表示预训练的基于事件的行人检测模型,输入事件
E
E
E 时,模型输出
Y
Y
Y 包含边界框位置
f
p
o
s
(
E
)
f_{pos }(E)
fpos(E)、目标概率
f
o
b
j
(
E
)
f_{obj }(E)
fobj(E) 和类别分数
f
c
l
s
(
E
)
f_{cls }(E)
fcls(E) ,即
Y
=
f
(
E
)
=
[
f
p
o
s
(
E
)
,
f
o
b
j
(
E
)
,
f
c
l
s
(
E
)
]
Y = f(E)=[f_{pos }(E), f_{obj }(E), f_{cls }(E)]
Y=f(E)=[fpos(E),fobj(E),fcls(E)]。
研究目标是欺骗检测器,使其无法检测到行人,具体通过最小化目标概率与类别分数之和 m i n f c o n f ( E ) = m i n ( f o b j ( E ) + f c l s ( E ) ) min f_{conf }(E)=min \left(f_{obj }(E)+f_{cls }(E)\right) minfconf(E)=min(fobj(E)+fcls(E)) 实现。为此,构建神经网络 G G G 生成含对抗图块的2D纹理图 U ~ \tilde{U} U~,即 U ~ = F i l t e r ( G ( z ) , M ) \tilde{U}=Filter(G(z), M) U~=Filter(G(z),M),其中 z z z 为输入参数, M M M 为掩码。
利用3D人体模型形状 β \beta β、连续姿态参数集 ϕ \phi ϕ、纹理图掩码 M M M 和相机外部参数 [ R ∣ t ] [R | t] [R∣t],通过可微渲染过程 R R R 生成一系列2D帧 I I I,表示穿着含对抗图块衣服的人体,即 I = { I k } k = 1 N = R ( U ~ , β , ϕ , [ R ∣ t ] ) I=\left\{I_{k}\right\}_{k = 1}^{N}=\mathcal{R}(\tilde{U}, \beta, \phi,[R | t]) I={Ik}k=1N=R(U~,β,ϕ,[R∣t]). 再使用可微的视频到事件(V2E)方法 T T T,基于事件渲染时间 t = { t k } k = 1 N t=\{t_{k}\}_{k = 1}^{N} t={tk}k=1N 生成相应的对抗事件 E ~ \tilde{E} E~,即 E ~ = T ( I , t ) \tilde{E}=T(I, t) E~=T(I,t),那么目标函数可重新表示为 a r g m i n f c o n f ( E ~ ) arg min f_{conf }(\tilde{E}) argminfconf(E~),其中 E ~ = T ( R ( F i l t e r ( G ( z ) , M ) , β , ϕ , [ R ∣ t ] ) , t ) \tilde{E}=T(\mathcal{R}(Filter (G(z), M), \beta, \phi,[R | t]), t) E~=T(R(Filter(G(z),M),β,ϕ,[R∣t]),t) ,该方法旨在找到最优对抗纹理图 U ~ \tilde{U} U~ 以欺骗行人检测器。
对抗攻击框架-Adversarial Attack Framework
该部分详细介绍了对抗攻击流程的构成,包括纹理图生成、3D人体渲染和对抗事件攻击三个关键部分,旨在系统地将对抗图块融入事件序列,误导基于事件的行人检测器,具体内容如下:
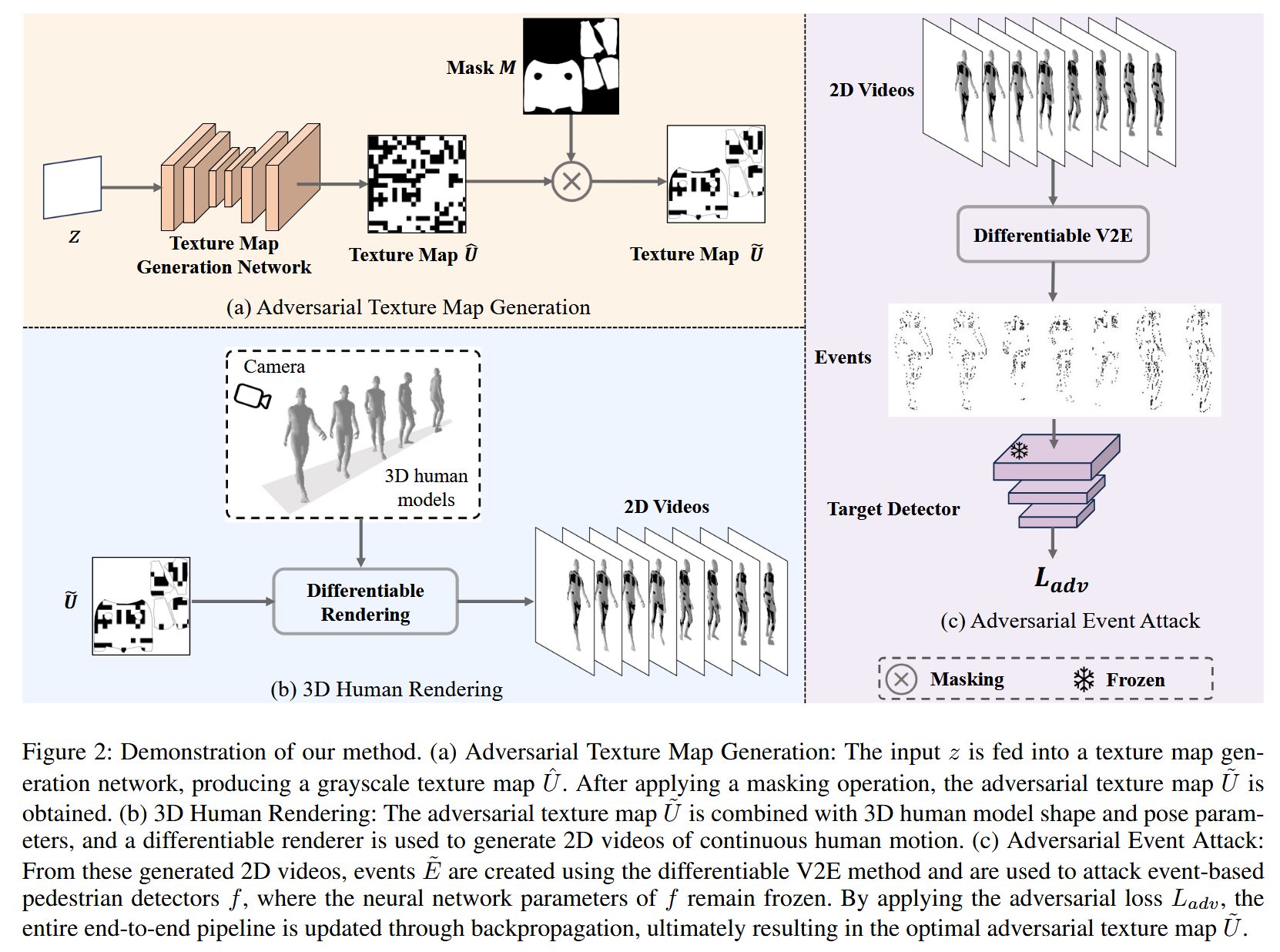
图2:我们方法的示意图。(a)对抗纹理图生成:将输入
z
z
z 输入到纹理图生成网络中,生成灰度纹理图
U
^
\hat{U}
U^. 经过掩码操作后,得到对抗纹理图
U
ˉ
\bar{U}
Uˉ. (b)3D人体渲染:将对抗纹理图
U
ˉ
\bar{U}
Uˉ 与3D人体模型形状和姿态参数相结合,使用可微渲染器生成连续人体运动的2D视频。(c)对抗事件攻击:利用可微的视频到事件(V2E)方法,从这些生成的2D视频中创建事件
E
ˉ
\bar{E}
Eˉ,并用于攻击基于事件的行人检测器
f
f
f,其中
f
f
f 的神经网络参数保持固定。通过应用对抗损失
L
a
d
v
L_{adv}
Ladv,整个端到端的流程通过反向传播进行更新,最终得到最优的对抗纹理图
U
ˉ
\bar{U}
Uˉ.
- 纹理图模式设计:事件相机仅捕捉亮度变化,因此攻击用的服装图案设计聚焦于高对比度的黑白颜色块,摒弃彩色网格。行人模型的服装纹理通过黑色代表低亮度区域、白色代表高亮度区域来呈现,设计的纹理图 U ^ \hat{U} U^ 由黑白块组成。
- 纹理图生成网络:纹理图分辨率为
H
×
W
H×W
H×W(
H
=
W
H = W
H=W),由
n
×
n
n×n
n×n 个
c
×
c
c×c
c×c 像素的块构成(
c
=
H
n
c=\frac{H}{n}
c=nH)。输入
z
z
z(初始化为白色的单通道
n
×
n
n×n
n×n 图像)经生成块处理,输出
n
×
n
n×n
n×n 灰度矩阵,再经二值化得到仅含黑白值的纹理图
u
b
u_b
ub,最后上采样得到目标纹理图。二值化采用直通估计器(STE),为保证训练稳定性,采用先软后硬的二值化方式。同时,利用掩码操作(公式
U
~
(
x
,
y
)
=
M
(
x
,
y
)
⋅
U
^
(
x
,
y
)
+
(
1
−
M
(
x
,
y
)
)
⋅
1
\tilde{U}(x, y)=M(x, y) \cdot \hat{U}(x, y)+(1 - M(x, y)) \cdot 1
U~(x,y)=M(x,y)⋅U^(x,y)+(1−M(x,y))⋅1)排除如头部、脚部和手指等特定区域进行纹理渲染,得到最终的纹理图
U
~
\tilde{U}
U~.
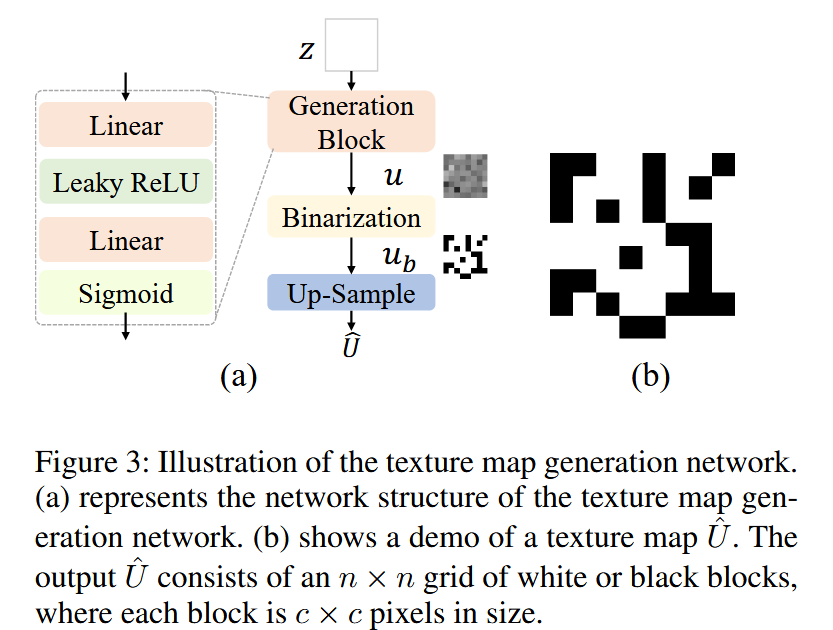
图3:纹理图生成网络示意图。(a)展示了纹理图生成网络的结构。(b)展示了纹理图 U ^ \hat{U} U^ 的示例。输出的 U ^ \hat{U} U^ 由一个 n × n n×n n×n 的网格组成,网格中的块为白色或黑色,每个块的大小为 c × c c×c c×c 像素。 - 3D人体模型渲染:为实现基于2D检测的对抗损失来寻找适用于3D人体的可行图案,采用可微渲染技术生成基于SMPL的3D人体参数化模型的连续帧,确保UV映射的时间一致性。借助PyTorch3D进行可微渲染,因其与PyTorch具有原生兼容性。
- 视频到事件转换:将2D视频从RGB颜色空间转换到YUV颜色空间,提取Y通道图像序列并转换到对数空间。根据一系列渲染时间和预定义的对比度阈值 θ = 0.2 \theta = 0.2 θ=0.2,计算相邻帧之间的差异,并行计算所有正事件和负事件的数量。采用的可微事件渲染机制源自(Gu et al. 2021),并对其进行了改进,使视频到事件(V2E)的转换过程可微。
- 对抗损失:构建对抗损失 L a d v L_{adv} Ladv,目的是同时最小化目标置信度分数和类别置信度分数。其中, L o b j = 1 M ∑ i = 1 M f o b j ( i ) ( E ~ ) L_{obj}=\frac{1}{M} \sum_{i = 1}^{M} f_{obj}^{(i)}(\tilde{E}) Lobj=M1∑i=1Mfobj(i)(E~) 表示目标置信度分数, L c l s = 1 M ∑ i = 1 M f c l s ( i ) ( E ~ ) L_{cls}=\frac{1}{M} \sum_{i = 1}^{M} f_{cls}^{(i)}(\tilde{E}) Lcls=M1∑i=1Mfcls(i)(E~) 表示类别置信度分数,总损失 L a d v = λ 1 L o b j + λ 2 L c l s L_{adv}=\lambda_{1} L_{obj}+\lambda_{2} L_{cls} Ladv=λ1Lobj+λ2Lcls (实验中 λ 1 = λ 2 = 10000 \lambda_{1}=\lambda_{2}=10000 λ1=λ2=10000)。利用该对抗损失,通过反向传播迭代更新对抗纹理图,从而实现对基于事件的行人检测器的有效攻击。
实验-Experiments
设置-Settings
该部分主要介绍了实验中用于评估对抗攻击有效性的指标、模型及参数设置、所使用的数据集等内容,为实验的实施和结果分析提供了标准与基础,具体如下:
- 评估指标
- 平均精度(AP):作为检测任务的标准指标,在本文实验中,AP值越低,表明对抗攻击性能越强,用于衡量模型检测行人的准确性。
- 序列攻击成功率(SeqASR):专门针对基于事件序列检测行人的任务提出,计算公式为 S e q A S R = 1 − N M SeqASR = 1-\frac{N}{M} SeqASR=1−MN,其中(M)是事件序列总数, N N N 是成功检测到行人的序列数。SeqASR值越高,说明行人检测器无法正确识别行人的可能性越大,即攻击效果越有效。
- 模型及参数设置
- 目标检测器:选用RVT(Gehrig和Scaramuzza,2023)的官方预训练基线模型RVT - B作为目标检测器,该模型在处理事件序列的检测任务中表现出色,且在Gen1汽车检测数据集上进行过训练,数据集由分辨率为304×240的事件相机捕获的真实世界事件数据构成。
- 其他参数:为确保与目标检测器兼容,实验中渲染的2D视频和生成的事件数据分辨率均设置为304×240;纹理图分辨率设为1024×1024;时间bins B B B 设置为10;使用Adam优化器对网络进行11,500次迭代训练,初始学习率为 1 0 − 4 10^{-4} 10−4;实验在NVIDIA 3090 GPU上进行,训练和验证的批次大小为1。
- 数据集:在数字空间实验中,使用AMASS提供的CMU运动捕捉数据集。训练数据集选取47次试验,包含114,173个姿态;测试数据集选取13次试验,共10,323个姿态。训练过程中,通过对相机外部参数引入随机性、改变渲染人体的角度和大小等方式进行数据增强。测试集包含三种不同尺度的3D人体渲染,用于全面评估攻击模型的性能。
结果-Results
该部分主要展示了数字攻击和物理攻击的实验结果,通过对比不同纹理和不同身体部位覆盖情况下的指标,验证了对抗攻击的有效性,具体内容如下:
- 数字攻击
- 不同阈值和纹理的影响:选取0.001 - 0.25之间的四个常见阈值,对比白色、黑色、随机(60×60像素)纹理以及不同网格大小(60×60 - 10×10)生成的纹理对攻击效果的影响。以平均精度(AP)和序列攻击成功率(SeqASR)为评估指标,结果表明20×20和10×10网格的纹理在AP和SeqASR得分上表现更优,其中10×10网格在SeqASR指标上表现最佳,因此被选为后续实验的最优纹理模式。
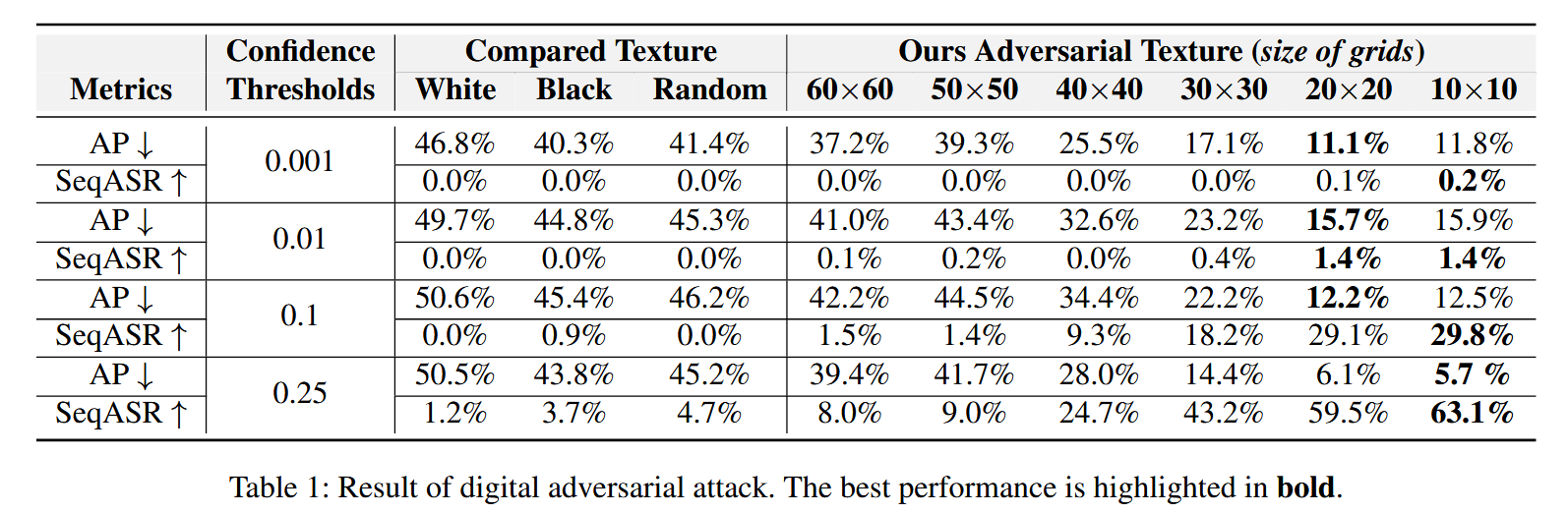
表1:数字对抗攻击的结果。最佳性能以粗体突出显示。

图4:用于所有纹理的掩码以及用于对比的基础纹理图。 - 不同身体部位纹理的影响:选定10×10网格大小,通过训练不同的掩码组合来研究纹理覆盖不同身体部位(上身、腿部、手臂)对整体攻击性能的影响,训练和测试时置信度阈值设为0.25。结果显示,腿部区域的攻击性能最佳,并且随着对抗纹理覆盖身体部位的增多,攻击性能总体呈提升趋势,全身覆盖时影响最为显著。
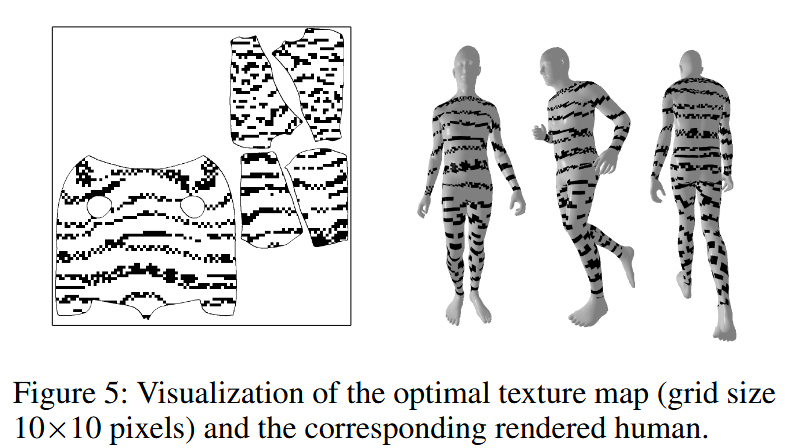
图5:最优纹理图(网格大小为10×10像素)及相应渲染人体的可视化展示。
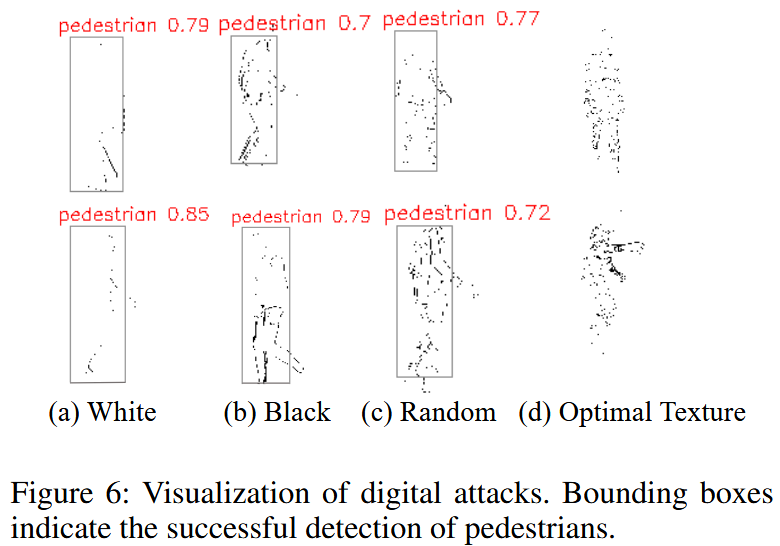
图6:数字攻击的可视化展示。边界框表示行人被成功检测到。
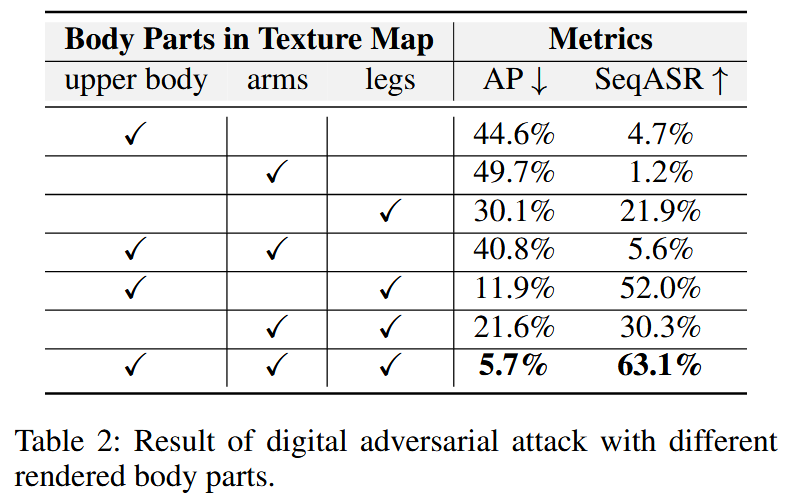
表2:不同渲染身体部位的数字对抗攻击结果。
- 不同阈值和纹理的影响:选取0.001 - 0.25之间的四个常见阈值,对比白色、黑色、随机(60×60像素)纹理以及不同网格大小(60×60 - 10×10)生成的纹理对攻击效果的影响。以平均精度(AP)和序列攻击成功率(SeqASR)为评估指标,结果表明20×20和10×10网格的纹理在AP和SeqASR得分上表现更优,其中10×10网格在SeqASR指标上表现最佳,因此被选为后续实验的最优纹理模式。
- 物理攻击
- 室内实验:使用INIVATION DAVIS346 MONO事件相机捕获真实世界事件数据,分辨率为346×260像素,裁剪为304×240像素以匹配目标检测器。将数字攻击实验得到的最优纹理图案放大打印在纸上,裁剪并组装成服装。选取普通服装作为对照,结果显示普通服装的SeqASR较低,而最优纹理的服装在物理攻击中展现出优越的对抗性能,表明数字域优化的纹理在物理攻击中依然有效。

图7:具有最优纹理的服装以及用于验证对比的服装的可视化展示。
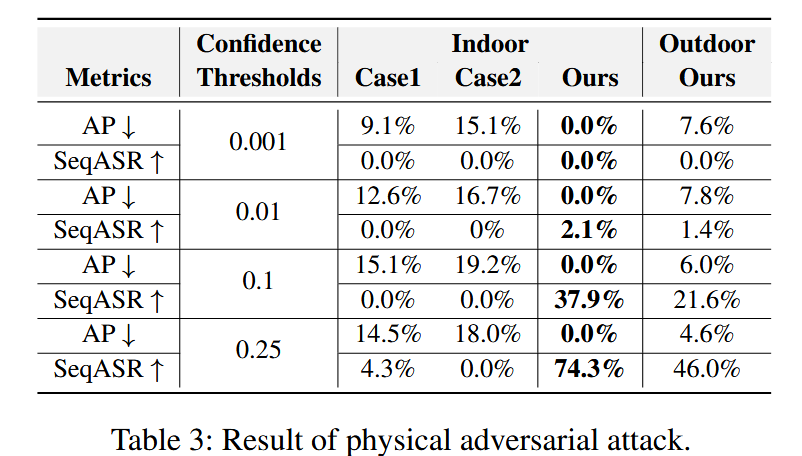
表3:物理对抗攻击的结果。 - 室外实验:在室外场景下测试最优纹理服装,结果表明,由于室外复杂的动态背景和波动的光照条件,对抗服装的有效性有所下降,但物理对抗攻击成功率仍然较高。这说明尽管室外环境增加了攻击难度,基于事件的行人检测器在物理对抗攻击下依然存在较大的脆弱性。

图8:室内场景中物理攻击的可视化效果。边界框表示行人被成功检测到。为了更好地展示,图像进行了裁剪。

图9:室外场景中检测结果的可视化展示。没有一个行人被检测到。
- 室内实验:使用INIVATION DAVIS346 MONO事件相机捕获真实世界事件数据,分辨率为346×260像素,裁剪为304×240像素以匹配目标检测器。将数字攻击实验得到的最优纹理图案放大打印在纸上,裁剪并组装成服装。选取普通服装作为对照,结果显示普通服装的SeqASR较低,而最优纹理的服装在物理攻击中展现出优越的对抗性能,表明数字域优化的纹理在物理攻击中依然有效。
结论-Conclusion
该部分总结了研究成果、指出研究存在的局限性,并对未来工作方向进行了展望,具体内容如下:
- 研究成果总结:提出了一种端到端的方法,用于设计在物理域中攻击基于事件的行人检测器的对抗服装。将寻找最有效的对抗服装问题转化为在数字域中优化2D纹理图的任务,借助3D渲染技术,将优化后的纹理映射到3D人体模型上,在数字空间展现出强大的对抗效果。进一步将纹理转化到物理域进行实验,取得了可比的攻击结果,证实了基于事件的行人检测器与基于RGB的模型一样,容易受到安全攻击,突出了此类模型在物理对抗攻击下的脆弱性。
- 研究局限性:研究主要设计黑白对抗补丁用于纹理映射,然而现实世界中的服装颜色更加丰富,纹理也更为复杂。当前的研究方法虽然有效,但在与现实场景的契合度上存在不足。
- 未来工作展望:未来将拓展对抗补丁的设计,使其涵盖更多现实中多样的服装风格,更好地模拟真实场景。同时,会致力于开发先进的防御机制,以应对各种物理对抗攻击,提升基于事件的视觉系统的安全性和鲁棒性。


















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











