







安泰杯算法大赛冠军数据处理思路分析
背景介绍
具体详细介绍可看这里
分析冠军baseline的数据分析思路
压缩数据大小
在面对上千万条数据进行分析的时候,一般个人笔记本需要占用的内存是很大的,所以需要适当的改变一下数据类型,减少缓存
代码如下:
item = pd.read_csv('./data/Antai_AE_round1_item_attr_20190626.csv')
train = pd.read_csv('./data/Antai_AE_round1_train_20190626.csv')
test = pd.read_csv('./data/Antai_AE_round1_test_20190626.csv')
submit = pd.read_csv('./data/Antai_AE_round1_submit_20190715.csv')
# 对数据进行预处理,将时间序列划分开来,为后续分析做准备
df = pd.concat([train.assign(is_train=1), test.assign(is_train=0)])
df['create_order_time'] = pd.to_datetime(df['create_order_time'])
df['date'] = df['create_order_time'].dt.date
df['day'] = df['create_order_time'].dt.day
df['hour'] = df['create_order_time'].dt.hour
df = pd.merge(df, item, how='left', on='item_id')
# 定义好新的数据类型,使用astype接口将df中的数据类型保存起来,随后删除
dtype_dict = {'buyer_admin_id' : 'int32',
'item_id' : 'int32',
'store_id' : pd.Int32Dtype(),
'irank' : 'int16',
'item_price' : pd.Int16Dtype(),
'cate_id' : pd.Int16Dtype(),
'is_train' : 'int8',
'day' : 'int8',
'hour' : 'int8',
}
df = df.astype(dtype_dict)
del train,test; gc.collect()
进过处理后文件内存占用从1200M减少至600M
接下来开始对数据进行预处理了
对数据集进行分析
我们可以对数据集的观察思路:
- 查看数据集的数据分布情况(条数)
- 查看缺失值情况和各属性的分布
冠军思路只提供了第一点
train = df['is_train']==1
test = df['is_train']==0
train_count = len(df[train])
print('训练集样本量是',train_count)
test_count = len(df[test])
print('测试集样本量是',test_count)
print('样本比例为:', train_count/test_count)
训练集样本量是 12868509
测试集样本量是 166832
样本比例为: 77.13453653975256
对于第二点,我们可以通过下面的代码实现
df[train].info(), df[test].info()

可以看到基本是没什么缺失值的
对国家编号进行分析
题目的描述中,我们可以知道的是,我们需要利用已成熟国家的稠密用户数据和待成熟国家的稀疏用户数据训练出对于待成熟国家用户的正确模型对于我们更好的服务待成熟国家用户。
通过对国家编号分析可以从下面几点实现:
- 以国家分组,看看总的订单数
- 以国家分组,看看每个人购买次数的情况
通过上面这两点,我们可以得到:
3. 国家订单记录数的分布情况
4. 每个国家中每个人购买的情况
代码实现:
def groupby_cnt_ratio(df, col):
if isinstance(col, str):
col = [col]
key = ['is_train', 'buyer_country_id'] + col
# groupby function
cnt_stat = df.groupby(key).size().to_frame('count')
ratio_stat = (cnt_stat / cnt_stat.groupby(['is_train', 'buyer_country_id']).sum()).rename(columns={'count':'count_ratio'})
return pd.merge(cnt_stat, ratio_stat, on=key, how='outer').sort_values(by=['count'], ascending=False)
groupby_cnt_ratio(df, [])

可以看出xx国比yy国多了5倍
画个图
plt.figure(figsize=(8,6))
sns.countplot(x='is_train', data = df, palette=['red', 'blue'], hue='buyer_country_id', order=[1, 0])
plt.xticks(np.arange(2), ('训练集', '测试集'))
plt.xlabel('数据文件')
plt.title('国家编号');

接下来直接对用户和国家分组,看看每个用户的订单数的情况,这里分组后只看每个国家前3个
admin_cnt = groupby_cnt_ratio(df, 'buyer_admin_id')
admin_cnt.groupby(['is_train','buyer_country_id']).head(3)

这样看可能还不够直观,所以需要画个图看看
fig, ax = plt.subplots(1, 2 ,figsize=(16,6))
ax[0].set(xlabel='用户记录数')
sns.kdeplot(admin_cnt.loc[(1, 'xx')]['count'].values, ax=ax[0]).set_title('训练集--xx国用户记录数')
ax[1].legend(labels=['训练集', '测试集'], loc="upper right")
ax[1].set(xlabel='用户记录数')
sns.kdeplot(admin_cnt[admin_cnt['count']<50].loc[(1, 'yy')]['count'].values, ax=ax[1]).set_title('yy国用户记录数')
sns.kdeplot(admin_cnt[admin_cnt['count']<50].loc[(0, 'yy')]['count'].values, ax=ax[1]);
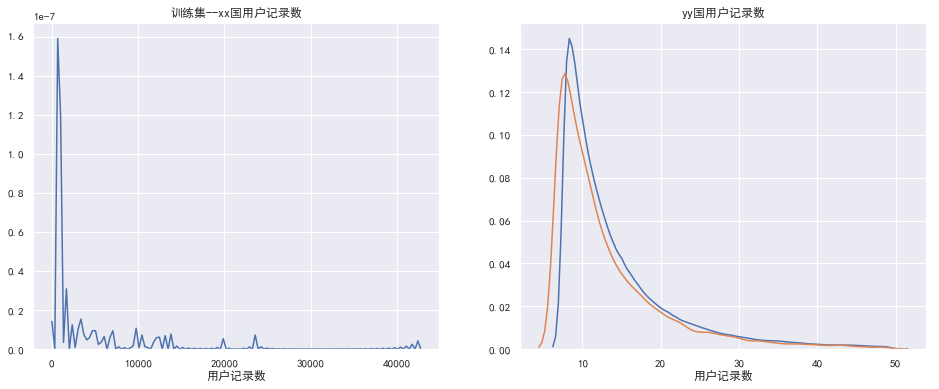
上面的图来自冠军的github代码分享图,本地跑可能是版本的问题,左边用户记录数显示不出来
通过上面的图可以知道的信息是,训练集每个人最少8条记录数,测试集最少每个人七条(之所以是7条,是因为题目介绍了说测试集把用户的最后一条购买数据给删掉了)。然后大部分(99%左右)用户都在50条左右(这里可以看右图,有图的kdeplot表示的是面积图,整个线和x围成的面积为1)
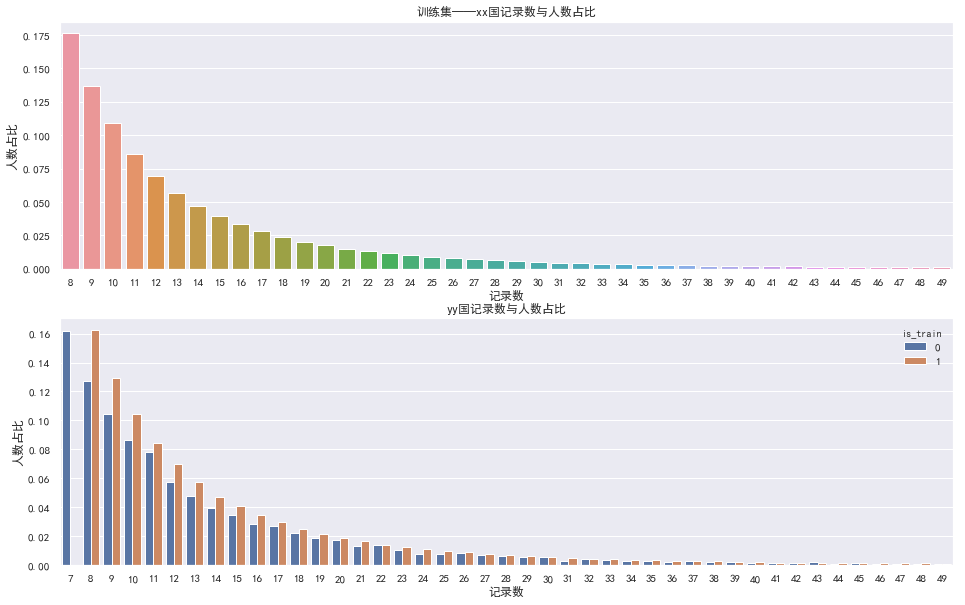
后面作者为了验证这个观点,对人数占比再次细化了一下,代码如下
admin_cnt.columns = ['记录数', '占比']
admin_user_cnt = groupby_cnt_ratio(admin_cnt, '记录数')
admin_user_cnt.columns = ['人数', '人数占比']
fig, ax = plt.subplots(2, 1, figsize=(16,10))
admin_plot = admin_user_cnt.reset_index()
sns.barplot(x='记录数', y='人数占比', data=admin_plot[(admin_plot['记录数']<50) & (admin_plot['buyer_country_id']=='xx')],
estimator=np.mean, ax=ax[0]).set_title('训练集——xx国记录数与人数占比');
sns.barplot(x='记录数', y='人数占比', hue='is_train', data=admin_plot[(admin_plot['记录数']<50) & (admin_plot['buyer_country_id']=='yy')],
estimator=np.mean, ax=ax[1]).set_title('yy国记录数与人数占比');
对商品进行分析
这一部分我们可以对商品展开分析,具体分析的思路如下:
- 看看数据集中商品的数量的情况
- 看看整体商品销量分布
- 看看每件商品销量情况
- 从品类来分析商品情况
- 从店铺来分析商品情况
- 从价格来分析
对商品数据情况分析
print('商品表中商品数:',len(item['item_id'].unique()))
print('训练集中商品数:',len(df[train]['item_id'].unique()))
print('验证集中商品数:',len(df[test]['item_id'].unique()))
print('仅训练集有的商品数:',len(list(set(df[train]['item_id'].unique()).difference(set(df[test]['item_id'].unique())))))
print('仅验证集有的商品数:',len(list(set(df[test]['item_id'].unique()).difference(set(df[train]['item_id'].unique())))))
print('训练集验证集共同商品数:',len(list(set(df[train]['item_id'].unique()).intersection(set(df[test]['item_id'].unique())))))
print('训练集中不在商品表的商品数:',len(list(set(df[train]['item_id'].unique()).difference(set(item['item_id'].unique())))))
print('验证集中不在商品表的商品数:',len(list(set(df[test]['item_id'].unique()).difference(set(item['item_id'].unique())))))
商品表中商品数: 2832669
训练集中商品数: 2812048
验证集中商品数: 104735
仅训练集有的商品数: 2735801
仅验证集有的商品数: 28488
训练集验证集共同商品数: 76247
训练集中不在商品表的商品数: 7733
验证集中不在商品表的商品数: 313
从商品整体销售情况来分析
item_order_cnt = groupby_cnt_ratio(item_cnt, '销量')
item_order_cnt.columns = ['商品数', '占比']
item_order_cnt.groupby(['is_train','buyer_country_id']).head(5).sort_values(by=['buyer_country_id','is_train'])

然后通过可视化
item_order_plot = item_order_cnt.reset_index()
item_order_plot = item_order_plot[item_order_plot['销量']<=8]
xx_item_order_plot = item_order_plot[item_order_plot['buyer_country_id']=='xx']
yy_item_order_plot = item_order_plot[item_order_plot['buyer_country_id']=='yy']
yy_item_order_plot_1 = yy_item_order_plot[yy_item_order_plot['is_train']==1]
yy_item_order_plot_0 = yy_item_order_plot[yy_item_order_plot['is_train']==0]
# 商品销量饼图
def text_style_func(pct, allvals):
absolute = int(pct/100.*np.sum(allvals))
return "{:.1f}%({:d})".format(pct, absolute)
def pie_param(ax, df, color_palette):
return ax.pie(df['占比'].values, autopct=lambda pct: text_style_func(pct, df['商品数']), labels = df['销量'],
explode = [0.1]+ np.zeros(len(df)-1).tolist(), pctdistance = 0.7, colors=sns.color_palette(color_palette, 8))
fig, ax = plt.subplots(1, 3, figsize=(16,12))
ax[0].set(xlabel='xx国-商品销量')
ax[0].set(ylabel='xx国-商品数量比例')
pie_param(ax[0], xx_item_order_plot, "coolwarm")
ax[1].set(xlabel='yy国-训练集商品销量')
pie_param(ax[1], yy_item_order_plot_1, "Set3")
ax[2].set(xlabel='yy国测试集集商品销量')
pie_param(ax[2], yy_item_order_plot_0, "Set3");
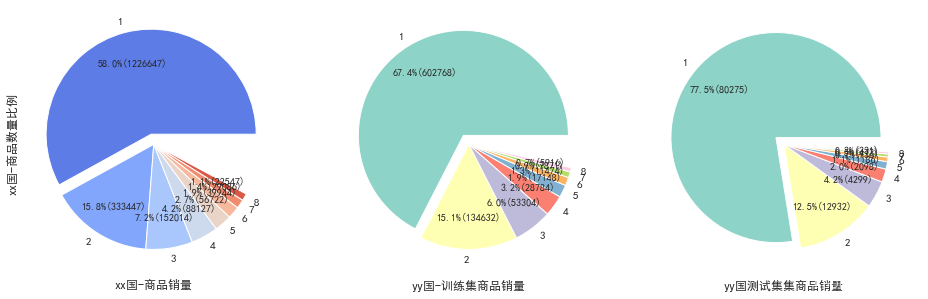
通过这个图,我们可以得到如下信息:
- xx国整体销量中,最高的一类商品销量占了56%
- yy国中测试集和训练集最高的一类占比是67.4和77.5
这个信息对我们完成baseline是有很强的启发作用的。baseline值得的是一个随便训练的模型得到的值,后续的模型提升都要基于这个baseline来提升,如果提升的幅度还没baseline高就要适当做出改变。这里得到的信息和结合我们题目中需要利用成熟国家去预测不成熟国家的情况,那么我们是否可以直接将xx国占比最高的去移植到yy国测试集的预测中呢?然后将结果作为baseline来参考
看看每件商品销量情况
代码实现:
item_cnt = groupby_cnt_ratio(df, 'item_id')
item_cnt.columns=['销量', '总销量占比']
item_cnt.reset_index(inplace=True)
top_item_plot = item_cnt.groupby(['is_train','buyer_country_id']).head(10)
fig, ax = plt.subplots(2, 1, figsize=(16,12))
sns.barplot(x='item_id', y='销量', data=top_item_plot[top_item_plot['buyer_country_id']=='xx'],
order=top_item_plot['item_id'][top_item_plot['buyer_country_id']=='xx'], ax=ax[0], estimator=np.mean).set_title('xx国-TOP热销商品')
sns.barplot(x='item_id', y='销量', hue='is_train', data=top_item_plot[top_item_plot['buyer_country_id']=='yy'],
order=top_item_plot['item_id'][top_item_plot['buyer_country_id']=='yy'], ax=ax[1], estimator=np.mean).set_title('yy国-TOP热销商品');

可以看到单件商品的销量情况。这种分析遇过遇到购买数据不到30次的用户时,可以通过直接推荐这种高销售的商品,毕竟这种商品肯定是满足用户日常所需的才会有这么高的销量
从品类分析商品情况
代码如下:
print('商品品类数', len(item['cate_id'].unique()))
print('训练集商品品类数', len(df[train]['cate_id'].unique()))
print('测试集商品品类数', len(df[test]['cate_id'].unique()))
商品品类数 4243
训练集商品品类数 4239
测试集商品品类数 2727
接着再看看各类商品中的数量
cate_cnt = item.groupby(['cate_id']).size().to_frame('count').reset_index()
cate_cnt.sort_values(by=['count'], ascending=False).head(5)

可以看到,从商品类别去分析的话,可以知道这些类别的大致情况,比如,编号为579的商品,被卖了17w次,这种情况我们大概可以知道:
- 这个估计是生活必需品,卖的多
- 这个价格便宜,或者是需要批量购买的东西
- 有可能存在恶意刷单现象
这种分析可能不一定对这个题目有用,但是这种思维却可以用来分析很多种场景
可视化一下
plt.figure(figsize=(12,4))
sns.kdeplot(data=cate_cnt[cate_cnt['count']<1000]['count']);

从店铺角度去分析
print('商品店铺数', len(item['store_id'].unique()))
print('训练集店铺数', len(df[train]['store_id'].unique()))
print('测试集店铺数', len(df[train]['store_id'].unique()))
store_cate_cnt = item.groupby(['store_id'])['cate_id'].nunique().to_frame('count').reset_index()
store_cate_cnt.sort_values(by=['count'], ascending=False).head(5)
商品店铺数 95105
训练集店铺数 94970
测试集店铺数 94970

可视化一下:
store_cnt_cate_cnt = store_cate_cnt.groupby(['count']).size().reset_index()
store_cnt_cate_cnt.columns = ['店铺品类数', '店铺数量']
plt.figure(figsize=(12,4))
sns.barplot(x='店铺品类数', y='店铺数量', data=store_cnt_cate_cnt[store_cnt_cate_cnt['店铺品类数']<50], estimator=np.mean);

可以看出大部分的店铺种类数平均在10以内
接着从商品价格去分析
先看看价格的分布情况
plt.figure(figsize=(16,4))
plt.subplot(121)
sns.kdeplot(item['item_price'])
plt.subplot(122)
sns.kdeplot(item['item_price'][item['item_price']<1000]);

想到价格,我们往往会直接和销量联想在一起,如果价格低的话,销量就高,价格高的话,销量就低。为了验证这一点,我们可以对商品分组,然后按价格排序,看看销量情况
price_cnt = groupby_cnt_ratio(df, 'item_price')
price_cnt.groupby(['is_train', 'buyer_country_id']).head(5)

但是当我们把结果弄出来以后却发现其实不然,价格和销量关系其实并不大。这也体现了数据分析的重要性,不能以直觉去估测,一切以数据说话
从时间角度去分析
订单日期分析
print(df[train]['create_order_time'].min(), df[train]['create_order_time'].max())
print(df[test]['create_order_time'].min(), df[test]['create_order_time'].max())
2018-07-13 05:54:54 2018-08-31 23:59:57
2018-07-17 07:43:40 2018-08-31 23:58:56
可以看到数据集中,训练集时间最早是2018-7-13 到 2018-8-31。测试集最早是2018-7-17 到2018-8-31
可视化一下
fig, ax = plt.subplots(2, 1, figsize=(16,10))
sns.lineplot(x='date', y='当天销量', hue='buyer_country_id', data=date_cnt[(date_cnt['is_train']==1)],
estimator=np.mean, ax=ax[0]).set_title('训练集——每日销量');
sns.lineplot(x='date', y='当天销量', hue='is_train', data=date_cnt[(date_cnt['buyer_country_id']=='yy')],
estimator=np.mean, ax=ax[1]).set_title('yy国每日销量');

可以看出无论是yy国还是xx国,在8月分都有一个小高峰,可能是搞了什么活动之类的
baseline
之前就说明了baseline是指我们训练一个很差的模型作为一个最低限度的指标,后续的优化都要参考这个指标。一定要比这个baseline好才能证明优化是有效的。
那么在这个比赛中的baseline我们可以直接不预测了,将用户近30次购买记录作为预测值,越近购买的商品放在越靠前的列,不够30次购买记录的用上面热销商品分析的结果,将热销商品5595070填充。得到一个baseline。
后续我们引入一些预测模型进行预测,肯定会比直接这样填充的效果要好,所以这样填充的结果很适合做baseline
代码:
test = pd.read_csv('../data/Antai_AE_round1_test_20190626.csv')
tmp = test[test['irank']<=31].sort_values(by=['buyer_country_id', 'buyer_admin_id', 'irank'])[['buyer_admin_id','item_id','irank']]
sub = tmp.set_index(['buyer_admin_id', 'irank']).unstack(-1)
sub.fillna(5595070).astype(int).reset_index().to_csv('../submit/sub.csv', index=False, header=None)
# 最终提交文件格式
sub = pd.read_csv('../submit/sub.csv', header = None)
sub.head()
总结
对于电商类别的比赛我们可以从一下的几个维度来思考。分别是:人,物,时间。人就是用户的行为。物就是商品和店铺的行为。时间就是和人物进行交互,从而分析出很多潜在的信息。
经过相关资料查询,这三个维度可以从以下几个角度展开,看看数据集适合计算哪些指标
从人的角度来看
- 用户分布情况
- 用户行为:如uv,pv等
- 用户画像:包括用户的年龄、性别、职业、收入水平、兴趣爱好等,这些数据可以帮助更好地理解用户需求和偏好。
- 用户生命周期:分析用户从首次访问到最终离开的整个过程,包括用户的留存率、流失率、复购率等。
- 用户社交行为:用户在社交媒体上的互动情况,如分享、评论、点赞等,可以反映出用户对品牌或产品的关注度和认可度。
- 用户购买路径:从用户进入网站到最终完成购买的整个路径,包括点击量、浏览时长、购物车添加次数等。
- 用户反馈与评价:分析用户在购买后的反馈和评价,可以帮助识别商品或服务的优缺点。
- 用户转化率:不同渠道、不同营销活动的转化效果,包括广告点击率、促销活动参与度等。
从物的角度来看
- 商品分类和数量:分析不同分类商品的数量及其占比,可以帮助了解平台上的商品结构。
- 商品销量:统计每个商品的销量数据,找出热销商品和滞销商品。
- 商品评价:分析用户对商品的评价和评分,找出评价较高和评价较低的商品。
- 库存管理:分析商品的库存情况,确保库存充足且不过量。
- 商品价格:商品定价策略及其对销量的影响,包括折扣、促销等。
- 商品上新与下架:商品的上新频率和下架情况,可以帮助了解商品的生命周期。
- 商品转化率:每个商品的浏览量、点击量与购买量之间的关系。
- 退货率:各商品的退货率,可以帮助识别哪些商品存在质量或描述问题。
- 店铺表现:各店铺的销售额、订单量、用户评价等。
- 物流和配送:商品的配送速度、物流成本及用户满意度。
从时间角度来看
- 销售趋势:分析不同时间段的销售数据,找出销售高峰期和低谷期。
- 用户活跃时间:用户在平台上的活跃时间段,帮助优化促销活动的时间安排。
- 季节性因素:分析不同季节、节假日对商品销售的影响,如双11、黑色星期五等购物节日。
- 促销活动:不同促销活动的时间安排及其效果,如秒杀、满减、打折等活动的效果分析。
- 用户购买频率:用户的购买周期,包括新用户首次购买到复购的时间间隔。
- 用户访问时长:用户在网站上的平均访问时长,分析用户的粘性和兴趣点。
- 订单处理时间:从用户下单到订单完成的整个时间周期,包括支付、处理、配送等环节的时间。
- 商品生命周期:商品从上架到下架的整个生命周期,包括销售高峰期和衰退期。
- 季节性商品:特定时间段销量较高的商品,如节庆商品、季节性商品等。
- 市场趋势预测:基于历史数据对未来销售趋势的预测,以便提前做好库存和促销准备。

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









