





在dec的学习中,有一个新名词kl散度,在此写下我的理解。
KL 散度,是一个用来衡量两个概率分布的相似性的一个度量指标。
回到机器学习课上的信息熵
I=-sigma(PlogP)
再引入新概念
交叉熵就是把上述式子中log部分换成Q
kl散度
描述两个概率分布的相似性,用交叉熵减去信息熵
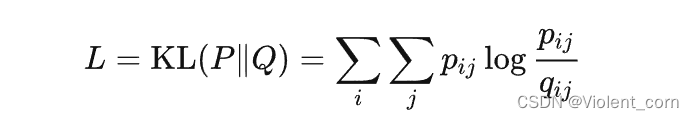
其值越小,说明越相似,概率分布就越接近

在dec的学习中,有一个新名词kl散度,在此写下我的理解。
KL 散度,是一个用来衡量两个概率分布的相似性的一个度量指标。
回到机器学习课上的信息熵
I=-sigma(PlogP)
再引入新概念
交叉熵就是把上述式子中log部分换成Q
kl散度
描述两个概率分布的相似性,用交叉熵减去信息熵
其值越小,说明越相似,概率分布就越接近
 129
4万+
129
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























