






本文基于Anaconda和Pycharm已经安装
目录
一、下载Yolo11的源代码
1.云盘链接 (无需加速 yolov11的版本为8.3.11 24年10月上传)
包括yolov11n.pt的文件一并下载
2.GitHub官方链接(需要加速)
GitHub - ultralytics/ultralytics: Ultralytics YOLO11 🚀
没有加速方法的话可以下载下面这个加速器,加速Github(steam也能加速哟)
瓦特工具箱(Steam++官网) - Watt Toolkit (steampp.net)

点击官网的那个【绿色Code按钮】再点击【Download ZIP】进行下载
下载得到一个压缩包,把它解压到你的电脑上的文件夹里就行了
官网往下滑点击YOLO11n下载

3.把yolo11n.pt文件放到yolo项目的根目录里
二、部署环境
1.打开Anaconda软件
点击左侧的【Environments】

2.创建环境
点击软件下方的【Create】

Name是环境的名称,用英文,比如yolo
Location是环境保存的路径
Packages这里选Python,版本选择3.10的
点击【Create】然后等待下载完成就行了

3.运行环境
直接点yolo旁边的【绿按钮】,再点击弹出来的【Open Terminal】就会打开环境终端了,接下来的操作都在这个黑框框里进行


终端如下

4.安装必要的包
注意:如果你下载包很慢
如果下载失败或者非常慢,正常pytorch的包预计一分钟内下完,如果确定你的本地网络没问题的话,就看下一步配置清华大学镜像源
以下两个命令选其一在终端进行
如果只是临时下载一个包,可以执行:(一次性使用)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名如果不想每次都添加的话,可以永久修改,这样不用每次都加辣莫长的网址了
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple4.1安装Torch
点击打开官网:PyTorch
4.1.1【GPU版本】
(重要:你的电脑装载了英伟达的显卡,比如RTX3060)
打开官网网址,往下滑,找到如图位置,可以按我图中的选
版本就选最新版就可以,比如Stable(2.5.0)的
(想使用老版本的可以点击左下角的【Previous versions of PyTorch】)
最后复制【Run this Command】的代码到你的环境终端(就那个黑框框)回车运行就开始下载安装了

安装结束后
验证GPU版本的PyTorch是否成功安装
(顺手创建个py文件复制下面代码运行一下就行)
运行这个之前你要先把整个环境配置好,马上了 OvO
import torch # 如果pytorch安装成功即可导入
print(torch.__version__) # 查看pytorch版本
print(torch.cuda.is_available()) # 查看CUDA是否可用
print(torch.cuda.device_count()) # 查看可用的CUDA数量
print(torch.version.cuda) # 查看CUDA的版本号如果输出true就可以了
4.1.2【CPU版本】
(重要:如果你的电脑没有独立显卡选这个版本,CPU跑代码会很慢)
打开官网网址,往下滑,找到如图位置,可以按我图中的选
版本就选最新版就可以,比如Stable(2.5.0)的
(想使用老版本的可以点击左下角的【Previous versions of PyTorch】)
最后复制【Run this Command】的代码到你的环境终端(就那个黑框框)回车运行就开始下载安装了

(下载ing...)

4.2安装其他依赖包
在终端上输入cd命令 转到你的yolo11项目的文件路径
如果不在C盘就先转到其他盘如D盘就是D: E盘就是 E: 然后回车
D:再输入 cd 你的yolo项目路径(我这里用我的C盘目录举个栗子)
cd C:\Users\11131\Desktop\DeepLearn\yolov11
在这个yolo的项目路径新建一个文本文档,如requirements.txt
把下面的代码复制进去保存关闭文本
# Base ------------------------------------------------------------------------
gitpython>=3.1.30
matplotlib>=3.3
numpy>=1.23.5
opencv-python>=4.1.1
pillow>=10.3.0
psutil # system resources
PyYAML>=5.3.1
requests>=2.32.2
scipy>=1.4.1
thop>=0.1.1 # FLOPs computation
torch>=1.8.0 # see https://pytorch.org/get-started/locally (recommended)
torchvision>=0.9.0
tqdm>=4.66.3
ultralytics>=8.2.34 # https://ultralytics.com
# protobuf<=3.20.1 # https://github.com/ultralytics/yolov5/issues/8012
# Logging ---------------------------------------------------------------------
# tensorboard>=2.4.1
# clearml>=1.2.0
# comet
# Plotting --------------------------------------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export ----------------------------------------------------------------------
# coremltools>=6.0 # CoreML export
# onnx>=1.10.0 # ONNX export
# onnx-simplifier>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn<=1.1.2 # CoreML quantization
# tensorflow>=2.4.0,<=2.13.1 # TF exports (-cpu, -aarch64, -macos)
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export
# Deploy ----------------------------------------------------------------------
setuptools>=70.0.0 # Snyk vulnerability fix
# tritonclient[all]~=2.24.0
# Extras ----------------------------------------------------------------------
# ipython # interactive notebook
# mss # screenshots
# albumentations>=1.0.3
# pycocotools>=2.0.6 # COCO mAP在终端中运行
pip install -r requirements.txt
三、运行项目
1.打开项目
右键你的yolo根目录文件夹,点击Open Folder as Pycharm...
通过Pycharm打开整个项目
2.更换解释器
先点击右下角【无解释器】,然后添加新的本地解释器

没有Conda可执行文件的话就点浏览,寻找Anaconda软件目录下的condabin文件夹里的conda.bat然后点击【加载环境】

选择我们刚才创建的yolo环境就行了
3.验证运行
在yolo根目录新建val.py文件,并复制以下代码进行运行
from ultralytics import YOLO
if __name__ == '__main__':
# 加载模型
model = YOLO(model=r'yolo11n.pt')
# 进行推理
model.predict(source=r'ultralytics/assets/bus.jpg', # source是要推理的图片路径这里使用yolo自带的图片
save=True, # 是否在推理结束后保存结果
show=True, # 是否在推理结束后显示结果
project='runs/detect', # 结果的保存路径
)
运行成功的话结果如下:


至此环境配置完成
四、如何训练以及数据集配置
1.训练代码
在yolo11的根目录创建一个新的train.py的文件,把以下代码内容进入train.py
其中,data是你数据集的配置文件路径
from ultralytics import YOLO
if __name__ == '__main__':
# 记录训练开始时间
start_time = datetime.now()
model = YOLO(model=r'yolo11n.pt') # .pt类型的文件是从预训练模型的基础上进行训练
# model = YOLO(model=r'ultralytics/cfg/models/11/yolo11s.yaml') # .yaml文件是从零开始训练,后缀n s x等是不同参数的模型,看具体应用场景
# 开始训练
model.train(data=r'D:\填入数据集yaml文件的地址\文件名.yaml', # 填入训练数据集配置文件的路径
imgsz=640, # 该参数代表输入图像的尺寸,指定为 640x640
epochs=200, # 该参数代表训练的轮数,默认100
# 但一般对于新数据集,我们还不知道这个数据集学习的难易程度,可以加大轮数,例如300,来找到更佳性能
batch=-1, # 每个批次中的图像数量。在训练过程中,数据被分成多个批次进行处理,每个批次包含一定数量的图像。
# 这个参数确定了每个批次中包含的图像数量。特殊的是,如果设置为-1,则会自动调整批次大小,至你的显卡能容纳的最多图像数量。
workers=8, # 该参数代表数据加载的工作线程数,出现显存爆了的话可以设置为0,默认是8
device='0', # 该参数代表用哪个显卡训练,0是GPU CPU就是直接写CPU
resume=False, # 该参数代表是否从上一次中断的训练状态继续训练。设置为False表示从头开始新的训练。如果设置为True,则会加载上一次训练的模型权重和优化器状态,继续训练。
name='yolo_res', # 该参数代表保存的结果文件夹名称(文件保存在上面project路径里)
)
训练的参数详解可以看这位大佬写的(写的非常非常好)yolov8和v11的参数基本都一样
YOLOv8训练参数详解(全面详细、重点突出、大白话阐述小白也能看懂)-CSDN博客
2.数据集配置文件的创建
假设你的数据集名字为"person_dataset",那么它的子文件夹应如下创建(除了Readme.txt是作者自己乱写的,实际不需要).yaml文件就是数据集的配置文件
为了方便使用,写成如下内容:train和val不需要更改,test可选用,nc代表你数据集有多少类别,比如person, cat, dog这是三个类别,nc后填3,那么names后面也要写上这三个类别
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: images/train
val: images/val
test:
# number of classes
nc: 1
# class names
names: ["目标检测的类别名字"]
images和labels文件里的子文件夹名字都有两个并且只有名字是一样的如下:

train(训练集)和val(验证集)里存放各自的图片和标签,一般val只需存放数据集总量的15%-20%,剩下的都放置在训练集里
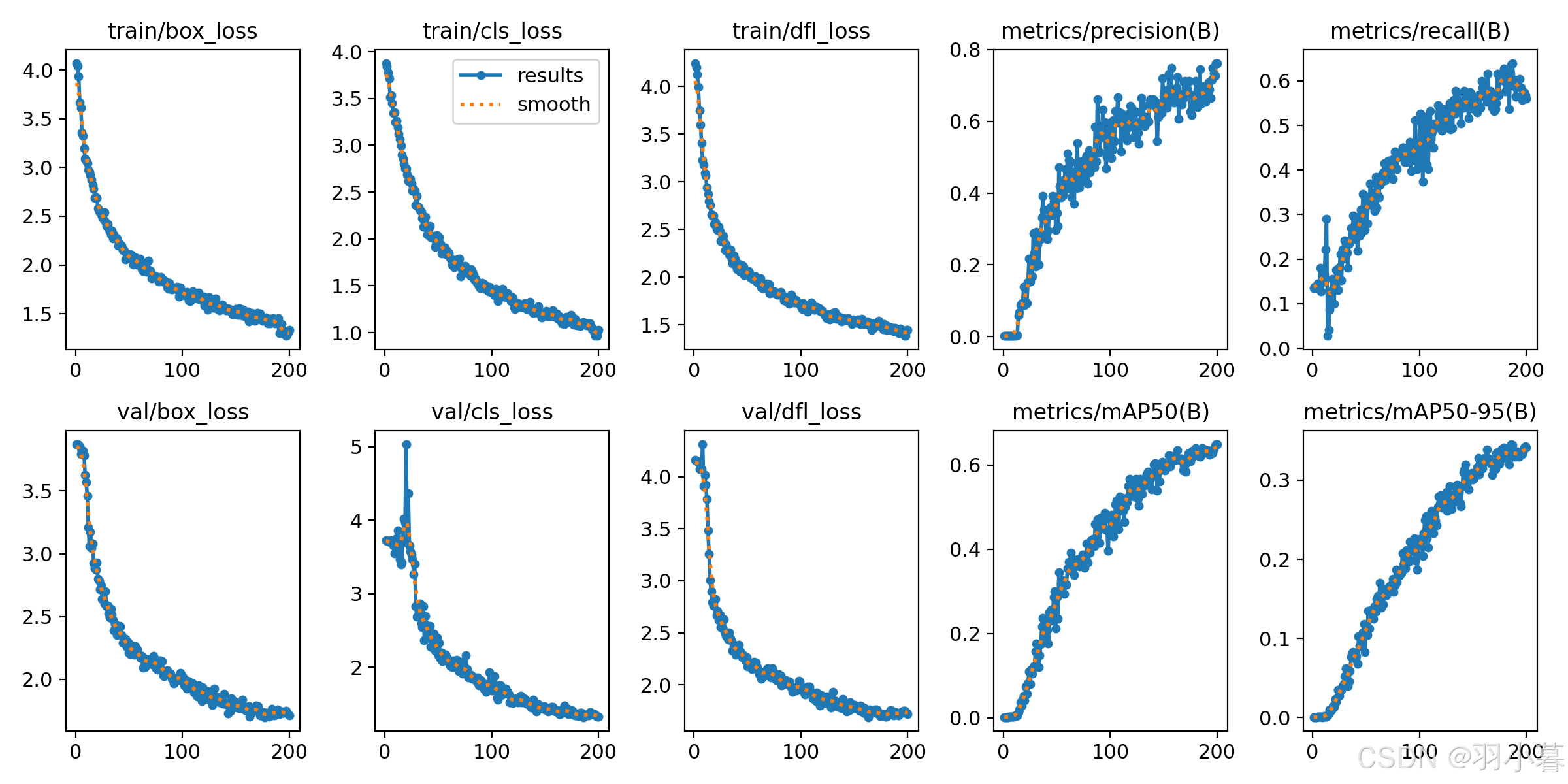
3.训练结果图的参数介绍
-
最重要的指标:
metrics/mAP50(B)和metrics/mAP50-95(B)是评估模型性能的核心指标,直接反映了模型在目标检测任务中的表现。 -
重要的损失指标:
train/box_loss、train/cls_loss、train/dfl_loss、val/box_loss、val/cls_loss、val/dfl_loss反映了模型在训练和验证过程中的表现。 -
次要指标:
epoch、time、lr/pg0、lr/pg1、lr/pg2主要用于监控训练过程和调试。
在YOLO(You Only Look Once)目标检测模型的训练过程中,输出的每个参数都代表了模型在不同方面的表现。
以下是对每个参数的详细解释及其重要性:
1. epoch
-
含义:当前训练的轮次。一个epoch表示模型已经遍历了整个训练数据集一次。
-
重要性:重要。随着epoch的增加,模型通常会逐渐收敛,但过多的epoch可能导致过拟合。
2. time
-
含义:当前epoch所花费的时间(通常以秒为单位)。
-
重要性:次要。主要用于监控训练速度,帮助评估训练效率。
3. train/box_loss
-
含义:训练集上的边界框回归损失。衡量模型预测的边界框与真实边界框之间的差异。
-
重要性:重要。较低的box_loss表示模型在定位目标方面表现较好。
4. train/cls_loss
-
含义:训练集上的分类损失。衡量模型预测的类别与真实类别之间的差异。
-
重要性:重要。较低的cls_loss表示模型在分类目标方面表现较好。
5. train/dfl_loss
-
含义:训练集上的分布焦点损失(Distribution Focal Loss)。这是YOLOv8中引入的一种损失函数,用于优化分类任务。
-
重要性:重要。较低的dfl_loss表示模型在分类任务上的表现较好。
6. metrics/precision(B)
-
含义:模型在验证集上的精确率(Precision)。精确率表示模型预测为正样本的样本中,实际为正样本的比例。
-
重要性:重要。高精确率表示模型预测的正样本中误报较少。
7. metrics/recall(B)
-
含义:模型在验证集上的召回率(Recall)。召回率表示实际为正样本的样本中,被模型正确预测为正样本的比例。
-
重要性:重要。高召回率表示模型能够检测到更多的正样本。
8. metrics/mAP50(B)
-
含义:模型在验证集上的mAP(mean Average Precision)@0.5 IoU阈值。mAP50表示在IoU阈值为0.5时的平均精度。
-
重要性:非常重要。mAP50是评估目标检测模型性能的核心指标之一,较高的mAP50表示模型在检测目标方面表现较好。
9. metrics/mAP50-95(B)
-
含义:模型在验证集上的mAP@0.5:0.95 IoU阈值。这是在不同IoU阈值(从0.5到0.95,步长为0.05)下的平均精度。
-
重要性:非常重要。mAP50-95是一个更全面的评估指标,能够反映模型在不同IoU阈值下的表现。
10. val/box_loss
-
含义:验证集上的边界框回归损失。
-
重要性:重要。较低的val/box_loss表示模型在验证集上的定位表现较好。
11. val/cls_loss
-
含义:验证集上的分类损失。
-
重要性:重要。较低的val/cls_loss表示模型在验证集上的分类表现较好。
12. val/dfl_loss
-
含义:验证集上的分布焦点损失。
-
重要性:重要。较低的val/dfl_loss表示模型在验证集上的分类任务表现较好。
13. lr/pg0, lr/pg1, lr/pg2
-
含义:不同参数组的学习率(learning rate)。YOLO模型通常将参数分为不同的组(如卷积层、批归一化层等),并为每个组设置不同的学习率。
-
重要性:次要。学习率的调整对模型训练有重要影响,但这些参数主要用于监控和调试。
4.WiderPerson数据集(附加)
此数据集官网:WiderPerson: A Diverse Dataset for Dense Pedestrian Detection in the Wild
另外,下面这个网盘里的是我经过处理后的,可以直接用于yolo训练的数据集
https://www.123684.com/s/7G74jv-W4cqh
总共两个数据集,一个是处理成yolo标注格式后的正常数据集,一个是把数据量8:1缩减后的mini数据集
mini版数据量小适合新手以及电脑显卡性能不好的使用(训练快),训练集图片1000张(原数据集8000张)

















 1682
1682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









