







import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LassoCV
from sklearn.linear_model import ElasticNetCV
from sklearn.linear_model import RidgeCV
from xgboost import XGBRegressor
import pandas as pd
out_path = 'E:\gee_image\\trian_test\data_train.npz'
poem = np.load(out_path, allow_pickle=True) # 读取保存的.npz样本文件
print(poem.files)
flag = poem['ar0'] # [612,609]
data_train = poem['ar1'] # [8,10000]
data_test = poem['ar2'] # [8,20000]
spei_train = poem['ar3'] # [1,10000]
spei_test = poem['ar4'] # [1,20000]
# 加载数据
data_x = np.array(data_train)
X = data_x
X = np.reshape(X, [X.shape[1], -1])
print('data_train:')
print(X.shape)
data_y = np.array(spei_train)
y = data_y
y = np.reshape(y, [y.shape[1], -1])
print('spei_train:')
print(y.shape)
X = X.astype('float64')
y = y.astype('float64')
X_test = np.reshape(data_test, [data_test.shape[1], -1])
print('data_test:')
print(X_test.shape)
y_test = np.reshape(spei_test, [spei_test.shape[1], -1])
print('spei_test:')
print(y_test.shape)
def show_data (X, y):
plt.figure(dpi=120)
plt.scatter(X, y)
plt.show()
def Cost_function (theta, X, y): # 损失函数
X_matrix = np.matrix(X)
y_matrix = np.matrix(y).T
temp = np.dot(X_matrix, theta) - y_matrix
J = 1 / 2 * (np.dot(temp.T, temp))
return J
def Update_theta (theta, X, y, num = 150, a = 0.0001): # 通过损失函数对权重参数w进行缩小
m, n = X.shape
theta0 = theta[0]
theta1 = theta[1]
x = X[:, -1]
for i in range(num):
pred = x * theta1 + theta0
temp_0 = np.sum(pred - y) / (m)
theta0 = theta0 - a * (temp_0)
temp_1 = np.sum((pred - y) * x) / (m)
theta1 = theta1 - a * (temp_1)
theta[0] = theta0
theta[1] = theta1
return theta
# 线性回归
model = LinearRegression()
model.fit(X, y) # ValueError: Unknown label type: 'continuous'
y_new = model.predict(X_test)
print('spei_predict:')
print(y_new.shape)
print("新样本预测结果:", y_new)
show_data(y_test, y_new)
# 随机森林
# model = RandomForestRegressor()
# model.fit(X, y) # ValueError: Unknown label type: 'continuous'
# y_new = model.predict(X_test)
# print('spei_predict:')
# print(y_new.shape)
# print("新样本预测结果:", y_new)
# show_data(y_test, y_new)
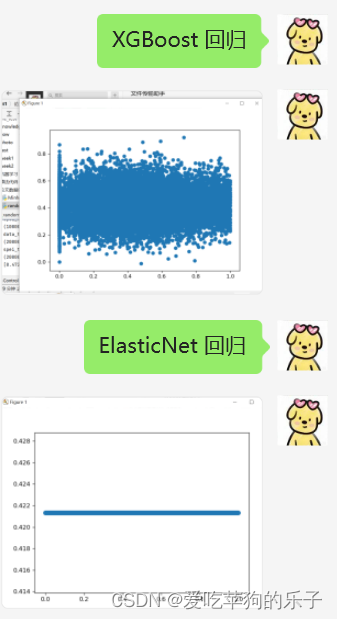
# XGBoost 回归
# model = XGBRegressor(
# n_estimators=1000,
# max_depth=7,
# eta=0.1,
# subsample=0.7,
# colsample_bytree=0.8,
# )
# model.fit(X, y)
# y_new = model.predict(X_test)
# print(y_new)
# show_data(y_test, y_new)
# ElasticNet 回归
# elasticNet = ElasticNetCV()
# elasticNet.fit(X, y.ravel())
# y_new = elasticNet.predict(X_test)
# print(y_new)
# show_data(y_test, y_new)
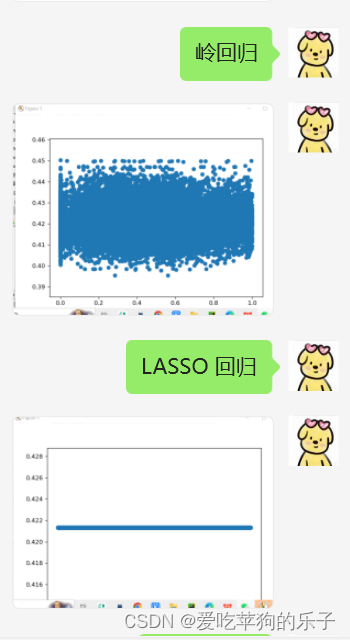
# 岭回归
# ridge = RidgeCV()
# ridge.fit(X, y)
# y_new = ridge.predict(X_test)
# print(y_new)
# show_data(y_test, y_new)
# LASSO 回归
# lasso = LassoCV()
# lasso.fit(X, y.ravel())
# y_new = lasso.predict(X_test)
# print(y_new)
# show_data(y_test, y_new)
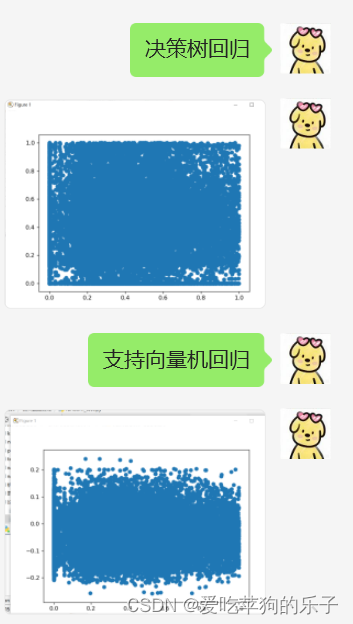
# 决策树回归
# tree_regressor = DecisionTreeRegressor(random_state = 0)
# tree_regressor.fit(X, y)
# y_new = tree_regressor.predict(X_test)
# print(y_new)
# show_data(y_test, y_new)
# 支持向量机回归
# scaled_X = StandardScaler()
# scaled_y = StandardScaler()
# scaled_X = scaled_X.fit_transform(X)
# scaled_y = scaled_y.fit_transform(y)
# svr_regressor = SVR(kernel='rbf', gamma='auto')
# svr_regressor.fit(scaled_X, scaled_y.ravel())
# y_new = svr_regressor.predict(X_test)
# print(y_new)
# show_data(y_test, y_new)
# 多项式回归____不考虑这个
# poly_reg = PolynomialFeatures(degree = 2)
# X_poly = poly_reg.fit_transform(X)
# model = LinearRegression()
# model.fit(X_poly, y)
# y_new = model.predict(X_test)
# print(y_new)
# show_data(y_test, y_new)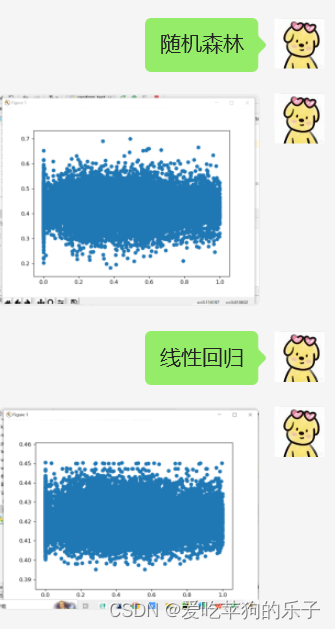
效果不理想,我还要继续学习,欢迎大家指正!















 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









