






一. 原文网址 2410.17725 (arxiv.org)
二. 论文原文和机翻
YOLOv11: An Overview of the Key Architectural Enhancements
YOLOv11:关键架构增强功能概述
Rahima Khanam* and Muhammad Hussain
Department of Computer Science, Huddersfield University, Queensgate, Huddersfield HD1 3DH, UK;*Correspondence: rahima.khanam@hud.ac.uk;
Abstract 抽象
This study presents an architectural analysis of YOLOv11, the latest iteration in the YOLO (You Only Look Once) series of object detection models. We examine the models architectural innovations, including the introduction of the C3k2 (Cross Stage Partial with kernel size 2) block, SPPF (Spatial Pyramid Pooling - Fast), and C2PSA (Convolutional block with Parallel Spatial Attention) components, which contribute in improving the models performance in several ways such as enhanced feature extraction. The paper explores YOLOv11’s expanded capabilities across various computer vision tasks, including object detection, instance segmentation, pose estimation, and oriented object detection (OBB). We review the model’s performance improvements in terms of mean Average Precision (mAP) and computational efficiency compared to its predecessors, with a focus on the trade-off between parameter count and accuracy. Additionally, the study discusses YOLOv11’s versatility across different model sizes, from nano to extra-large, catering to diverse application needs from edge devices to high-performance computing environments. Our research provides insights into YOLOv11’s position within the broader landscape of object detection and its potential impact on real-time computer vision applications.
本研究介绍了对 YOLOv11 的架构分析,YOLOv11 是 YOLO (You Only Look Once) 系列对象检测模型的最新版本。我们研究了模型架构创新,包括引入 C3k2 (Cross Stage Partial with kernel size 2) 块、SPPF (Spatial Pyramid Pooling - Fast) 和 C2PSA (Convolutional block with Parallel Spatial Attention) 组件,这些组件以多种方式有助于提高模型性能,例如增强的特征提取。本白皮书探讨了 YOLOv11 在各种计算机视觉任务中的扩展功能,包括对象检测、实例分割、姿势估计和定向对象检测 (OBB)。我们回顾了该模型与前代模型相比在平均精度 (mAP) 和计算效率方面的性能改进,重点是参数数量和精度之间的权衡。此外,该研究还讨论了 YOLOv11 在不同模型尺寸(从纳米到超大型)中的多功能性,可满足从边缘设备到高性能计算环境的各种应用需求。我们的研究深入了解了 YOLOv11 在更广泛的对象检测领域中的地位及其对实时计算机视觉应用的潜在影响。
Keywords Automation; Computer Vision; YOLO; YOLOV11; Object Detection; Real-Time Image processing; YOLO version comparison
Keywords 自动化;计算机视觉;YOLO;YOLOV11;对象检测;实时图像处理;YOLO 版本对比
1Introduction 1介绍
Computer vision, a rapidly advancing field, enables machines to interpret and understand visual data [1]. A crucial aspect of this domain is object detection[2], which involves the precise identification and localization of objects within images or video streams[3]. Recent years have witnessed remarkable progress in algorithmic approaches to address this challenge [4].
计算机视觉是一个快速发展的领域,它使机器能够解释和理解视觉数据 [1]。该领域的一个关键方面是对象检测[2],它涉及精确识别和定位图像或视频流中的对象[3]。近年来,在应对这一挑战的算法方法方面取得了显著进展 [4]。
A pivotal breakthrough in object detection came with the introduction of the You Only Look Once (YOLO) algorithm by Redmon et al. in 2015 [5]. This innovative approach, as its name suggests, processes the entire image in a single pass to detect objects and their locations. YOLO’s methodology diverges from traditional two-stage detection processes by framing object detection as a regression problem [5]. It employs a single convolutional neural network to simultaneously predict bounding boxes and class probabilities across the entire image [6], streamlining the detection pipeline compared to more complex traditional methods.
Redmon 等人在 2015 年引入了 You Only Look Once (YOLO) 算法 [5],这是对象检测的关键突破。顾名思义,这种创新方法在一次通过中处理整个图像以检测物体及其位置。YOLO 的方法与传统的两阶段检测过程不同,它将对象检测视为回归问题 [5]。它采用单个卷积神经网络来同时预测整个图像的边界框和类概率 [6],与更复杂的传统方法相比,它简化了检测管道。
YOLOv11 is the latest iteration in the YOLO series, building upon the foundation established by YOLOv1. Unveiled at the YOLO Vision 2024 (YV24) conference, YOLOv11 represents a significant leap forward in real-time object detection technology. This new version introduces substantial enhancements in both architecture and training methodologies, pushing the boundaries of accuracy, speed, and efficiency.
YOLOv11 是 YOLO 系列的最新版本,建立在 YOLOv1 建立的基础之上。YOLOv2024 (YV24) 大会上亮相,代表着实时物体检测技术的重大飞跃。此新版本在架构和训练方法方面引入了大量增强功能,突破了准确性、速度和效率的界限。
YOLOv11’s innovative design incorporates advanced feature extraction techniques, allowing for more nuanced detail capture while maintaining a lean parameter count. This results in improved accuracy across a diverse range of computer vision (CV) tasks, from object detection to classification. Furthermore, YOLOv11 achieves remarkable gains in processing speed, substantially enhancing real-time performance capabilities.
YOLOv11 的创新设计融合了先进的特征提取技术,允许在保持精简参数计数的同时实现更细致的细节捕获。这可以提高从对象检测到分类的各种计算机视觉 (CV) 任务的准确性。此外,YOLOv11 在处理速度方面取得了显著的提升,大大增强了实时性能。
In the following sections, this paper will provide a comprehensive analysis of YOLOv11’s architecture, exploring its key components and innovations. We will examine the evolution of YOLO models, leading up to the development of YOLOv11. The study will delve into the model’s expanded capabilities across various CV tasks, including object detection, instance segmentation, pose estimation, and oriented object detection. We will also review YOLOv11’s performance improvements in terms of accuracy and computational efficiency compared to its predecessors, with a particular focus on its versatility across different model sizes. Finally, we will discuss the potential impact of YOLOv11 on real-time CV applications and its position within the broader landscape of object detection technologies.
在以下部分中,本文将对 YOLOv11 的架构进行全面分析,探讨其关键组件和创新。我们将研究 YOLO 模型的演变,从而导致 YOLOv11 的开发。该研究将深入研究该模型在各种 CV 任务中的扩展功能,包括对象检测、实例分割、姿态估计和定向对象检测。我们还将回顾 YOLOv11 与前代产品相比在准确性和计算效率方面的性能改进,特别关注其在不同模型大小的多功能性。最后,我们将讨论 YOLOv11 对实时 CV 应用的潜在影响,以及它在更广泛的对象检测技术领域中的地位。
2Evolution of YOLO models
第二YOLO 模型的演变
Table 1 illustrates the progression of YOLO models from their inception to the most recent versions. Each iteration has brought significant improvements in object detection capabilities, computational efficiency, and versatility in handling various CV tasks.
表 1 说明了 YOLO 模型从开始到最新版本的进展。每次迭代都带来了对象检测能力、计算效率和处理各种 CV 任务的多功能性的显著改进。
Table 1:YOLO: Evolution of models
表 1:YOLO:模型的演变
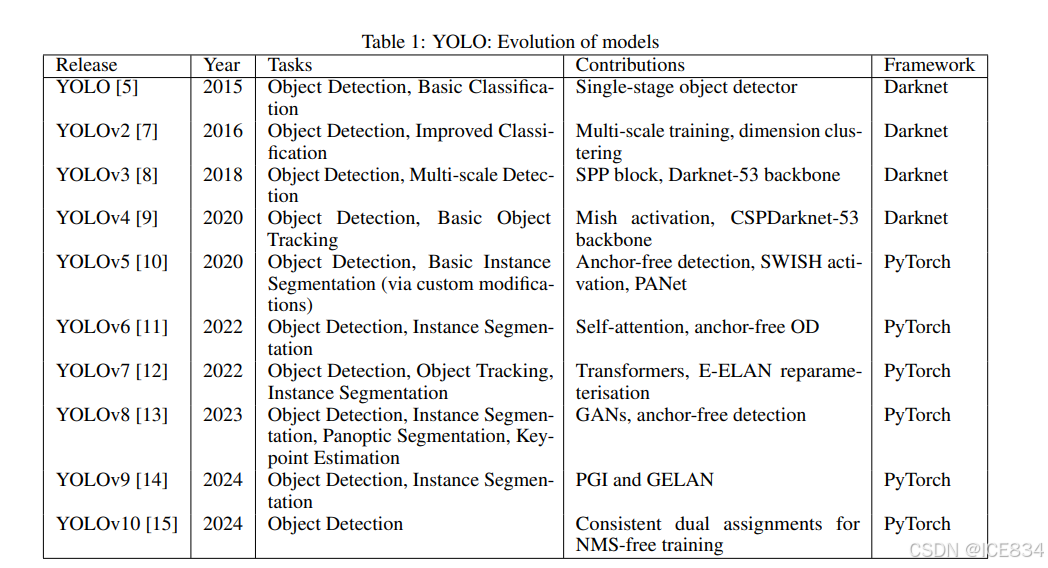
This evolution showcases the rapid advancement in object detection technologies, with each version introducing novel features and expanding the range of supported tasks. From the original YOLO’s groundbreaking single-stage detection to YOLOv10’s NMS-free training, the series has consistently pushed the boundaries of real-time object detection.
这种演变展示了对象检测技术的快速发展,每个版本都引入了新功能并扩展了支持的任务范围。从最初的 YOLO 开创性的单阶段检测到 YOLOv10 的无 NMS 训练,该系列不断突破实时物体检测的界限。
The latest iteration, YOLO11, builds upon this legacy with further enhancements in feature extraction, efficiency, and multi-task capabilities. Our subsequent analysis will delve into YOLO11’s architectural innovations, including its improved backbone and neck structures, and its performance across various computer vision tasks such as object detection, instance segmentation, and pose estimation.
最新版本 YOLO11 以这一传统为基础,在特征提取、效率和多任务功能方面进一步增强。我们随后的分析将深入研究 YOLO11 的架构创新,包括其改进的主干和颈部结构,以及它在各种计算机视觉任务(如对象检测、实例分割和姿势估计)中的性能。
3What is YOLOv11?
3什么是 YOLOv11?
The evolution of the YOLO algorithm reaches new heights with the introduction of YOLOv11 [16], representing a significant advancement in real-time object detection technology. This latest iteration builds upon the strengths of its predecessors while introducing novel capabilities that expand its utility across diverse CV applications.
随着 YOLOv11 [16] 的推出,YOLO 算法的演变达到了新的高度,代表了实时目标检测技术的重大进步。最新版本建立在其前辈的优势之上,同时引入了新功能,将其实用性扩展到各种 CV 应用中。
YOLOv11 distinguishes itself through its enhanced adaptability, supporting an expanded range of CV tasks beyond traditional object detection. Notable among these are posture estimation and instance segmentation, broadening the model’s applicability in various domains. YOLOv11’s design focuses on balancing power and practicality, aiming to address specific challenges across various industries with increased accuracy and efficiency.
YOLOv11 以其增强的适应性而著称,支持超越传统对象检测的扩展 CV 任务范围。其中值得注意的是态势估计和实例分割,拓宽了该模型在各个领域的适用性。YOLOv11 的设计注重平衡功能和实用性,旨在以更高的准确性和效率解决各个行业的特定挑战。
This latest model demonstrates the ongoing evolution of real-time object detection technology, pushing the boundaries of what’s possible in CV applications. Its versatility and performance improvements position YOLOv11 as a significant advancement in the field, potentially opening new avenues for real-world implementation across diverse sectors.
这个最新的模型展示了实时对象检测技术的持续发展,突破了 CV 应用的可能性。它的多功能性和性能改进使 YOLOv11 成为该领域的重大进步,有可能为跨不同行业的实际实施开辟新的途径。
4Architectural footprint of Yolov11
4Yolov11 的架构足迹
The YOLO framework revolutionized object detection by introducing a unified neural network architecture that simultaneously handles both bounding box regression and object classification tasks [17]. This integrated approach marked a significant departure from traditional two-stage detection methods, offering end-to-end training capabilities through its fully differentiable design.
YOLO 框架通过引入统一的神经网络架构来彻底改变对象检测,该架构同时处理边界框回归和对象分类任务 [17]。这种集成方法标志着与传统的两阶段检测方法的重大背离,通过其完全可区分的设计提供端到端的训练功能。
At its core, the YOLO architecture consists of three fundamental components. First, the backbone serves as the primary feature extractor, utilizing convolutional neural networks to transform raw image data into multi-scale feature maps. Second, the neck component acts as an intermediate processing stage, employing specialized layers to aggregate and enhance feature representations across different scales. Third, the head component functions as the prediction mechanism, generating the final outputs for object localization and classification based on the refined feature maps.
YOLO 架构的核心由三个基本组件组成。首先,主干网充当主要特征提取器,利用卷积神经网络将原始图像数据转换为多尺度特征图。其次,neck 组件充当中间处理阶段,采用专用层来聚合和增强不同比例下的特征表示。第三,头部组件作为预测机制,根据细化的特征图生成用于目标定位和分类的最终输出。
Building on this established architecture, YOLO11 extends and enhances the foundation laid by YOLOv8, introducing architectural innovations and parameter optimizations to achieve superior detection performance as illustrated in Figure 1. The following sections detail the key architectural modifications implemented in YOLO11:
基于此已建立的架构,YOLO11 扩展和增强了 YOLOv8 奠定的基础,引入了架构创新和参数优化,以实现卓越的检测性能,如图 1 所示。以下部分详细介绍了在 YOLO11 中实现的关键架构修改:
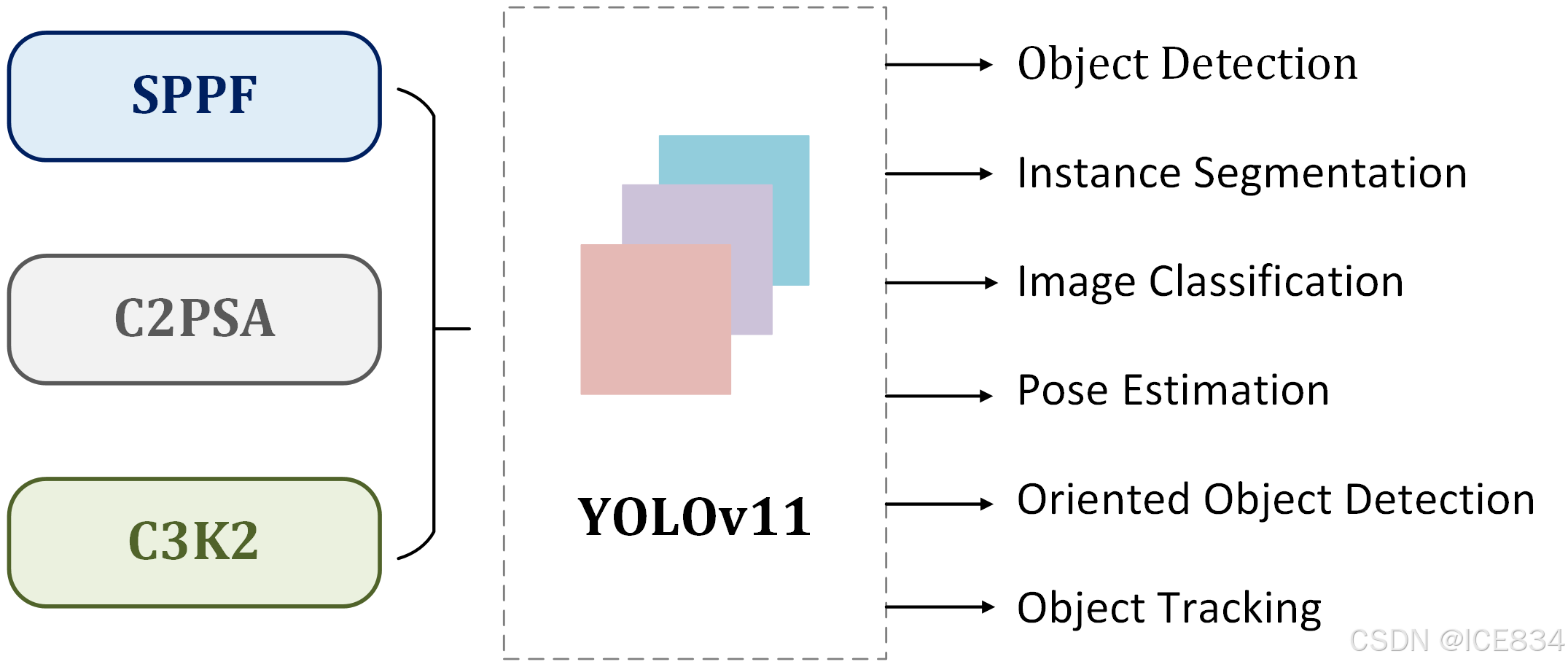
Figure 1:Key architectural modules in YOLO11
图 1:YOLO11 中的关键架构模块
4.1Backbone 4.1骨干
The backbone is a crucial component of the YOLO architecture, responsible for extracting features from the input image at multiple scales. This process involves stacking convolutional layers and specialized blocks to generate feature maps at various resolutions.
主干是 YOLO 架构的关键组成部分,负责从多个比例的输入图像中提取特征。此过程涉及堆叠卷积层和专用块,以生成各种分辨率的特征图。
4.1.1Convolutional Layers
4.1.1卷积层
YOLOv11 maintains a structure similar to its predecessors, utilizing initial convolutional layers to downsample the image. These layers form the foundation of the feature extraction process, gradually reducing spatial dimensions while increasing the number of channels. A significant improvement in YOLO11 is the introduction of the C3k2 block, which replaces the C2f block used in previous versions [18]. The C3k2 block is a more computationally efficient implementation of the Cross Stage Partial (CSP) Bottleneck. It employs two smaller convolutions instead of one large convolution, as seen in YOLOv8 [13]. The "k2" in C3k2 indicates a smaller kernel size, which contributes to faster processing while maintaining performance.
YOLOv11 保持了与其前辈类似的结构,利用初始卷积层对图像进行下采样。这些层构成了特征提取过程的基础,逐渐减小空间维度,同时增加通道数。YOLO11 的一个重大改进是引入了 C3k2 块,它取代了以前版本中使用的 C2f 块 [18]。C3k2 块是跨阶段部分 (CSP) 瓶颈的更高效的实现。它采用两个较小的卷积,而不是一个大卷积,如 YOLOv8 [13] 所示。C3k2 中的“k2”表示较小的内核大小,这有助于在保持性能的同时加快处理速度。
4.1.2SPPF and C2PSA
4.1.2SPPF 和 C2PSA
YOLO11 retains the Spatial Pyramid Pooling - Fast (SPPF) block from previous versions but introduces a new Cross Stage Partial with Spatial Attention (C2PSA) block after it [18]. The C2PSA block is a notable addition that enhances spatial attention in the feature maps. This spatial attention mechanism allows the model to focus more effectively on important regions within the image. By pooling features spatially, the C2PSA block enables YOLO11 to concentrate on specific areas of interest, potentially improving detection accuracy for objects of varying sizes and positions.
YOLO11 保留了以前版本中的 Spatial Pyramid Pooling - Fast (SPPF) 模块,但在它之后引入了一个新的 Cross Stage Partial with Spatial Attention (C2PSA) 模块[18]。C2PSA 块是一个值得注意的新增功能,它增强了特征图中的空间注意力。这种空间注意力机制使模型能够更有效地关注图像中的重要区域。通过在空间上汇集特征,C2PSA 模块使 YOLO11 能够专注于特定的感兴趣区域,从而有可能提高不同大小和位置的物体的检测精度。
4.2Neck 4.2脖子
The neck combines features at different scales and transmits them to the head for prediction. This process typically involves upsampling and concatenation of feature maps from different levels, enabling the model to capture multi-scale information effectively.
颈部结合了不同尺度的特征,并将它们传输到头部进行预测。此过程通常涉及对不同级别的特征图进行上采样和串联,使模型能够有效地捕获多尺度信息。
4.2.1C3k2 Block
4.2.1C3k2 块
YOLO11 introduces a significant change by replacing the C2f block in the neck with the C3k2 block. The C3k2 block is designed to be faster and more efficient, enhancing the overall performance of the feature aggregation process. After upsampling and concatenation, the neck in YOLO11 incorporates this improved block, resulting in enhanced speed and performance [18].
YOLO11 引入了一个重大变化,将琴颈中的 C2f 块替换为 C3k2 块。C3k2 块旨在更快、更高效,从而提高特征聚合过程的整体性能。在上采样和连接之后,YOLO11 中的 neck 包含了这个改进的块,从而提高了速度和性能 [18]。
4.2.2Attention Mechanism
4.2.2注意力机制
A notable addition to YOLO11 is its increased focus on spatial attention through the C2PSA module. This attention mechanism enables the model to concentrate on key regions within the image, potentially leading to more accurate detection, especially for smaller or partially occluded objects. The inclusion of C2PSA sets YOLO11 apart from its predecessor, YOLOv8, which lacks this specific attention mechanism [18].
YOLO11 的一个显着新增功能是它通过 C2PSA 模块更加关注空间注意力。这种注意力机制使模型能够专注于图像中的关键区域,从而有可能实现更准确的检测,尤其是对于较小或部分被遮挡的对象。C2PSA 的加入使 YOLO11 与其前身 YOLOv8 不同,后者缺乏这种特定的注意力机制 [18]。
4.3Head 4.3头
The head of YOLOv11 is responsible for generating the final predictions in terms of object detection and classification. It processes the feature maps passed from the neck, ultimately outputting bounding boxes and class labels for objects within the image.
YOLOv11 的负责人负责生成对象检测和分类方面的最终预测。它处理从 neck 传递的特征图,最终输出图像中对象的边界框和类标签。
4.3.1C3k2 Block
4.3.1C3k2 块
In the head section, YOLOv11 utilizes multiple C3k2 blocks to efficiently process and refine the feature maps. The C3k2 blocks are placed in several pathways within the head, functioning to process multi-scale features at different depths. The C3k2 block exhibits flexibility depending on the value of the c3k parameter:
在 head 部分,YOLOv11 利用多个 C3k2 块来高效处理和完善特征图。C3k2 块放置在头部内的多个通路中,用于处理不同深度的多尺度特征。C3k2 模块表现出灵活性,具体取决于 c3k 参数的值:
-
•
When c3k = False, the C3k2 module behaves similarly to the C2f block, utilizing a standard bottleneck structure.
• 当 c3k = False 时,C3k2 模块的行为类似于 C2f 模块,采用标准瓶颈结构。 -
•
When c3k = True, the bottleneck structure is replaced by the C3 module, which allows for deeper and more complex feature extraction.
• 当 c3k = True 时,瓶颈结构被 C3 模块取代,从而允许更深入、更复杂的特征提取。
Key characteristics of the C3k2 block:
C3k2 块的主要特性:
-
•
Faster processing: The use of two smaller convolutions reduces the computational overhead compared to a single large convolution, leading to quicker feature extraction.
• 更快的处理速度:与单个大型卷积相比,使用两个较小的卷积可以减少计算开销,从而更快地提取特征。 -
•
Parameter efficiency: C3k2 is a more compact version of the CSP bottleneck, making the architecture more efficient in terms of the number of trainable parameters.
• 参数效率:C3k2 是 CSP 瓶颈的更紧凑版本,使架构在可训练参数的数量方面更加高效。
Another notable addition is the C3k block, which offers enhanced flexibility by allowing customizable kernel sizes. The adaptability of C3k is particularly useful for extracting more detailed features from images, contributing to improved detection accuracy.
另一个值得注意的新增功能是 C3k 块,它通过允许自定义内核大小来提供增强的灵活性。C3k 的适应性对于从图像中提取更详细的特征特别有用,有助于提高检测准确性。
4.3.2CBS Blocks
4.3.2CBS 区块
The head of YOLOv11 includes several CBS (Convolution-BatchNorm-Silu) [19] layers after the C3k2 blocks. These layers further refine the feature maps by:
YOLOv11 的头部包括 C3k2 块之后的几个 CBS (Convolution-BatchNorm-Silu) [19] 层。这些层通过以下方式进一步细化特征图:
-
•
Extracting relevant features for accurate object detection.
• 提取相关特征以进行准确的对象检测。 -
•
Stabilizing and normalizing the data flow through batch normalization.
• 通过批量规范化来稳定和规范化数据流。 -
•
Utilizing the Sigmoid Linear Unit (SiLU) activation function for non-linearity, which improves model performance.
• 利用 Sigmoid 线性单元 (SiLU) 激活函数实现非线性,从而提高模型性能。
CBS blocks serve as foundational components in both feature extraction and the detection process, ensuring that the refined feature maps are passed to the subsequent layers for bounding box and classification predictions.
CBS 块在特征提取和检测过程中都充当基础组件,确保将细化的特征图传递到后续层以进行边界框和分类预测。
4.3.3Final Convolutional Layers and Detect Layer
4.3.3最终卷积层和检测层
Each detection branch ends with a set of Conv2D layers, which reduce the features to the required number of outputs for bounding box coordinates and class predictions. The final Detect layer consolidates these predictions, which include:
每个检测分支都以一组 Conv2D 层结尾,这些层将特征减少到边界框坐标和类预测所需的输出数量。最终的 Detect 层整合了这些预测,其中包括:
-
•
Bounding box coordinates for localizing objects in the image.
• 用于定位图像中对象的边界框坐标。 -
•
Objectness scores that indicate the presence of objects.
• 指示对象存在的客观性分数。 -
•
Class scores for determining the class of the detected object.
• 用于确定检测到对象的类别的类别分数。
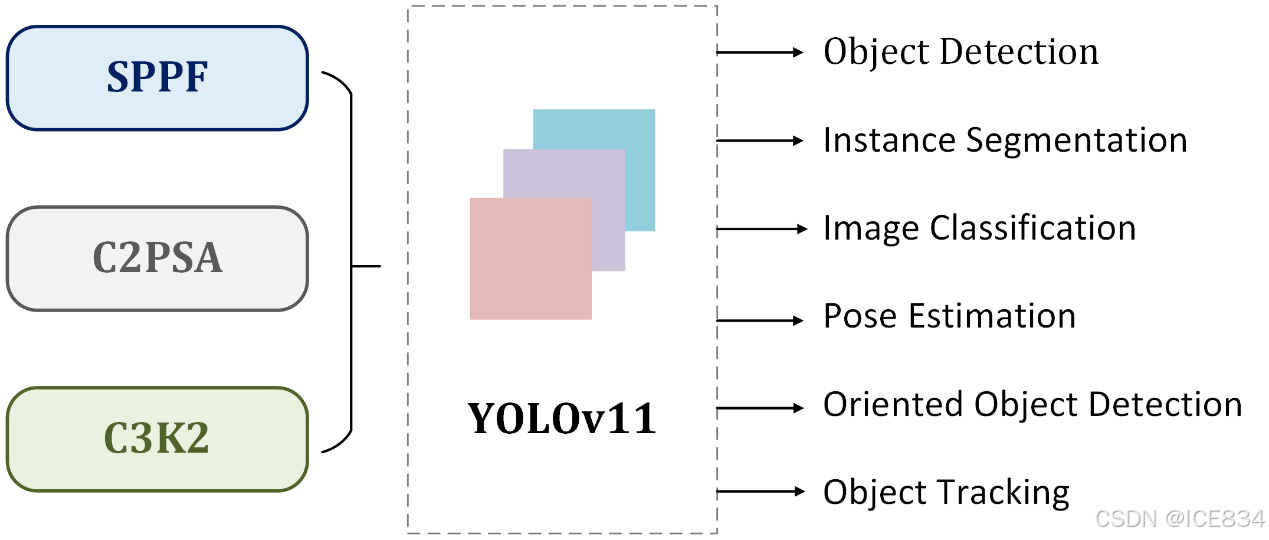
5Key Computer Vision Tasks Supported by YOLO11
5YOLO11 支持的关键计算机视觉任务
YOLO11 supports a diverse range of CV tasks, showcasing its versatility and power in various applications. Here’s an overview of the key tasks:
YOLO11 支持各种 CV 任务,在各种应用中展示其多功能性和强大功能。以下是关键任务的概述:
-
1.
Object Detection: YOLO11 excels in identifying and localizing objects within images or video frames, providing bounding boxes for each detected item [20]. This capability finds applications in surveillance systems, autonomous vehicles, and retail analytics, where precise object identification is crucial [21].
1. 目标检测:YOLO11 擅长识别和定位图像或视频帧中的目标,为每个检测到的项目提供边界框 [ 20]。这种能力在监控系统、自动驾驶汽车和零售分析中得到了应用,在这些应用中,精确的对象识别至关重要[ 21]。 -
2.
Instance Segmentation: Going beyond simple detection, YOLO11 can identify and separate individual objects within an image down to the pixel level [20]. This fine-grained segmentation is particularly valuable in medical imaging for precise organ or tumor delineation, and in manufacturing for detailed defect detection [21].
2. 实例分割:YOLO11 超越了简单的检测,可以识别和分离图像中的单个对象,直至像素级 [ 20]。这种细粒度分割在医学成像中特别有价值,用于精确的器官或肿瘤描绘,在制造中用于详细的缺陷检测 [ 21]。 -
3.
Image Classification: YOLOv11 is capable of classifying entire images into predetermined categories, making it ideal for applications like product categorization in e-commerce platforms or wildlife monitoring in ecological studies [21].
3. 图像分类:YOLOv11 能够将整个图像分类为预定的类别,非常适合电子商务平台中的产品分类或生态研究中的野生动物监测等应用 [ 21]。 -
4.
Pose Estimation: The model can detect specific key points within images or video frames to track movements or poses. This capability is beneficial for fitness tracking applications, sports performance analysis, and various healthcare applications requiring motion assessment [21].
4. 姿态估计:该模型可以检测图像或视频帧中的特定关键点,以跟踪运动或姿态。此功能有利于健身跟踪应用、运动表现分析和需要运动评估的各种医疗保健应用 [ 21]。 -
5.
Oriented Object Detection (OBB): YOLO11 introduces the ability to detect objects with an orientation angle, allowing for more precise localization of rotated objects. This feature is especially valuable in aerial imagery analysis, robotics, and warehouse automation tasks where object orientation is crucial [21].
5. 定向目标检测 (OBB):YOLO11 引入了使用方向角检测目标的能力,从而可以更精确地定位旋转的物体。此功能在航空图像分析、机器人和仓库自动化任务中特别有价值,因为在这些任务中,对象定位至关重要 [ 21]。 -
6.
Object Tracking: It identifies and traces the path of objects in a sequence of images or video frames[21]. This real-time tracking capability is essential for applications such as traffic monitoring, sports analysis, and security systems.
6. 对象跟踪:它识别和跟踪图像或视频帧序列中对象的路径[ 21]。这种实时跟踪功能对于交通监控、体育分析和安全系统等应用程序至关重要。
Table 2:YOLOv11 Model Variants and Tasks
表 2:YOLOv11 模型变体和任务
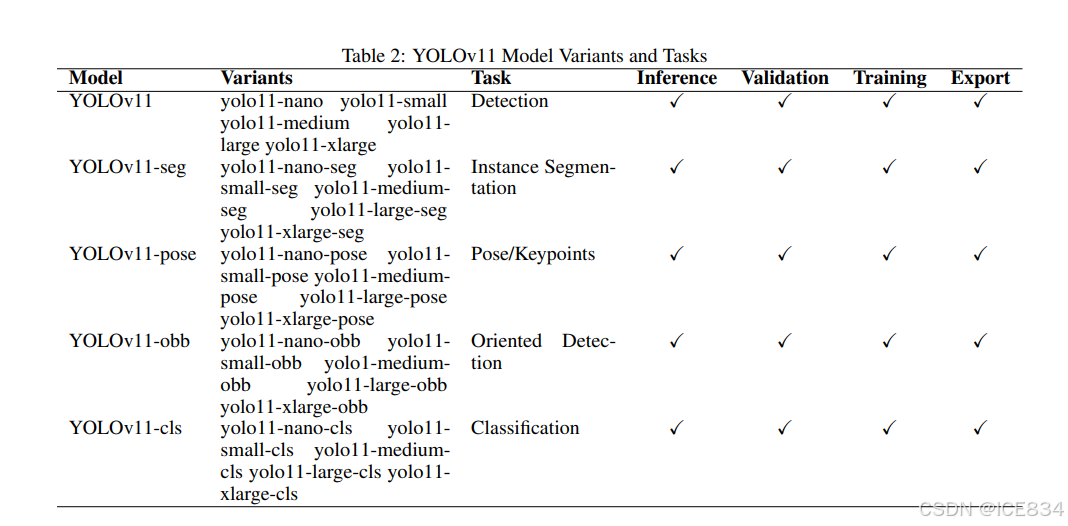
Table 2 outlines the YOLOv11 model variants and their corresponding tasks. Each variant is designed for specific use cases, from object detection to pose estimation. Moreover, all variants support core functionalities like inference, validation, training, and export, making YOLOv11 a versatile tool for various CV applications.
表 2 概述了 YOLOv11 模型变体及其相应的任务。每个变体都是为特定用例设计的,从对象检测到姿势估计。此外,所有变体都支持推理、验证、训练和导出等核心功能,使 YOLOv11 成为适用于各种 CV 应用的多功能工具。
6Advancements and Key Features of YOLOv11
6YOLOv11 的进步和主要功能
YOLOv11 represents a significant advancement in object detection technology, building upon the foundations laid by its predecessors, YOLOv9 and YOLOv10, which were introduced earlier in 2024. This latest iteration from Ultralytics showcases enhanced architectural designs, more sophisticated feature extraction techniques, and refined training methodologies. The synergy of YOLOv11’s rapid processing, high accuracy, and computational efficiency positions it as one of the most formidable models in Ultralytics’ portfolio to date [22]. A key strength of YOLOv11 lies in its refined architecture, which facilitates the detection of subtle details even in challenging scenarios. The model’s improved feature extraction capabilities allow it to identify and process a broader range of patterns and intricate elements within images. Compared to earlier versions, YOLOv11 introduces several notable enhancements:
YOLOv11 代表了对象检测技术的重大进步,建立在其前身 YOLOv9 和 YOLOv10 奠定的基础之上,这两个版本于 2024 年早些时候推出。Ultralytics 的最新版本展示了增强的架构设计、更复杂的特征提取技术和改进的训练方法。YOLOv11 的快速处理、高精度和计算效率的协同作用使其成为 Ultralytics 产品组合中迄今为止最强大的模型之一 [22]。YOLOv11 的一个关键优势在于其精致的架构,即使在具有挑战性的场景中,它也有助于检测细微的细节。该模型改进的特征提取功能使其能够识别和处理图像中更广泛的模式和复杂元素。与早期版本相比,YOLOv11 引入了几个显著的增强功能:
-
1.
Enhanced precision with reduced complexity: The YOLOv11m variant achieves superior mean Average Precision (mAP) scores on the COCO dataset while utilizing 22% fewer parameters than its YOLOv8m counterpart, demonstrating improved computational efficiency without compromising accuracy [23].
1. 提高精度,降低复杂性:YOLOv11m 变体在 COCO 数据集上获得了卓越的平均精度 (mAP) 分数,同时使用的参数比 YOLOv8m 变体少 22%,在不影响准确性的情况下展示了更高的计算效率 [ 23]。 -
2.
Versatility in CV tasks: YOLOv11 exhibits proficiency across a diverse array of CV applications, including pose estimation, object recognition, image classification, instance segmentation, and oriented bounding box (OBB) detection [23].
2. CV 任务的多功能性:YOLOv11 在各种 CV 应用中表现出熟练程度,包括姿势估计、对象识别、图像分类、实例分割和定向边界框 (OBB) 检测 [ 23]。 -
3.
Optimized speed and performance: Through refined architectural designs and streamlined training pipelines, YOLOv11 achieves faster processing speeds while maintaining a balance between accuracy and computational efficiency [23].
3. 优化的速度和性能:通过精细的架构设计和流线的训练管道,YOLOv11 实现了更快的处理速度,同时保持了准确性和计算效率之间的平衡 [ 23]。 -
4.
Streamlined parameter count: The reduction in parameters contributes to faster model performance without significantly impacting the overall accuracy of YOLOv11 [22].
4. 简化参数计数:参数的减少有助于提高模型性能,而不会显着影响 YOLOv11 的整体准确性 [ 22]。 -
5.
Advanced feature extraction: YOLOv11 incorporates improvements in both its backbone and neck architectures, resulting in enhanced feature extraction capabilities and, consequently, more precise object detection [23].
5. 高级特征提取:YOLOv11 在其 backbone 和 neck 架构中进行了改进,从而增强了特征提取能力,从而实现了更精确的对象检测 [ 23]。 -
6.
Contextual adaptability: YOLOv11 demonstrates versatility across various deployment scenarios, including cloud platforms, edge devices, and systems optimized for NVIDIA GPUs [23].
6. 上下文适应性:YOLOv11 在各种部署场景中展示了多功能性,包括云平台、边缘设备和针对 NVIDIA GPU 优化的系统 [ 23]。
YOLOv11 model demonstrates significant advancements in both inference speed and accuracy compared to its predecessors. In the benchmark analysis, YOLOv11 was compared against several of its predecessors including variants such as YOLOv5 [24] through to the more recent variants such as YOLOv10. As presented in Figure 2, YOLOv11 consistently outperforms these models, achieving superior mAP on the COCO dataset while maintaining a faster inference rate [25].
与前代产品相比,YOLOv11 模型在推理速度和准确性方面都取得了重大进步。在基准分析中,将 YOLOv11 与其几个前身进行了比较,包括 YOLOv5 [24] 等变体,以及 YOLOv10 等更新的变体。如图 2 所示,YOLOv11 的性能始终优于这些模型,在 COCO 数据集上实现了卓越的 mAP,同时保持了更快的推理速率 [25]。
The performance comparison graph depicted in Figure 2 overs several key insights. The YOLOv11 variants (11n, 11s, 11m, and 11x) form a distinct performance frontier, with each model achieving higher COCO mAP50-95 scores at their respective latency points. Notably, the YOLOv11x achieves approximately 54.5% mAP50-95 at 13ms latency, surpassing all previous YOLO iterations. The intermediate variants, particularly YOLOv11m, demonstrate exceptional efficiency by achieving comparable accuracy to larger models from previous generations while requiring significantly less processing time.
图 2 中描述的性能比较图涵盖了几个关键见解。YOLOv11 变体(11n、11s、11m 和 11x)形成了独特的性能前沿,每个模型在各自的延迟点都获得了更高的 COCO mAP50-95 分数。值得注意的是,YOLOv11x 在50-95 年间实现了大约 54.5% 的 mAP 延迟为 13 毫秒,超过了之前的所有 YOLO 迭代。中间型号,尤其是 YOLOv11m,通过实现与前几代大型型号相当的精度,同时需要显著减少的处理时间,表现出卓越的效率。
A particularly noteworthy observation is the performance leap in the low-latency regime (2-6ms), where YOLOv11s maintains high accuracy (approximately 47% mAP50-95) while operating at speeds previously associated with much less accurate models. This represents a crucial advancement for real-time applications where both speed and accuracy are critical. The improvement curve of YOLOv11 also shows better scaling characteristics across its model variants, suggesting more efficient utilization of additional computational resources compared to previous generations.
一个特别值得注意的观察结果是低延迟状态(2-6 毫秒)的性能飞跃,其中 YOLOv11s 保持高精度(在50-95 毫秒时约为 47% mAP),同时以以前与精度低得多的模型相关的速度运行。对于速度和准确性都至关重要的实时应用程序来说,这是一个至关重要的进步。YOLOv11 的改进曲线还显示出其模型变体中更好的扩展特性,表明与前几代相比,可以更有效地利用额外的计算资源。
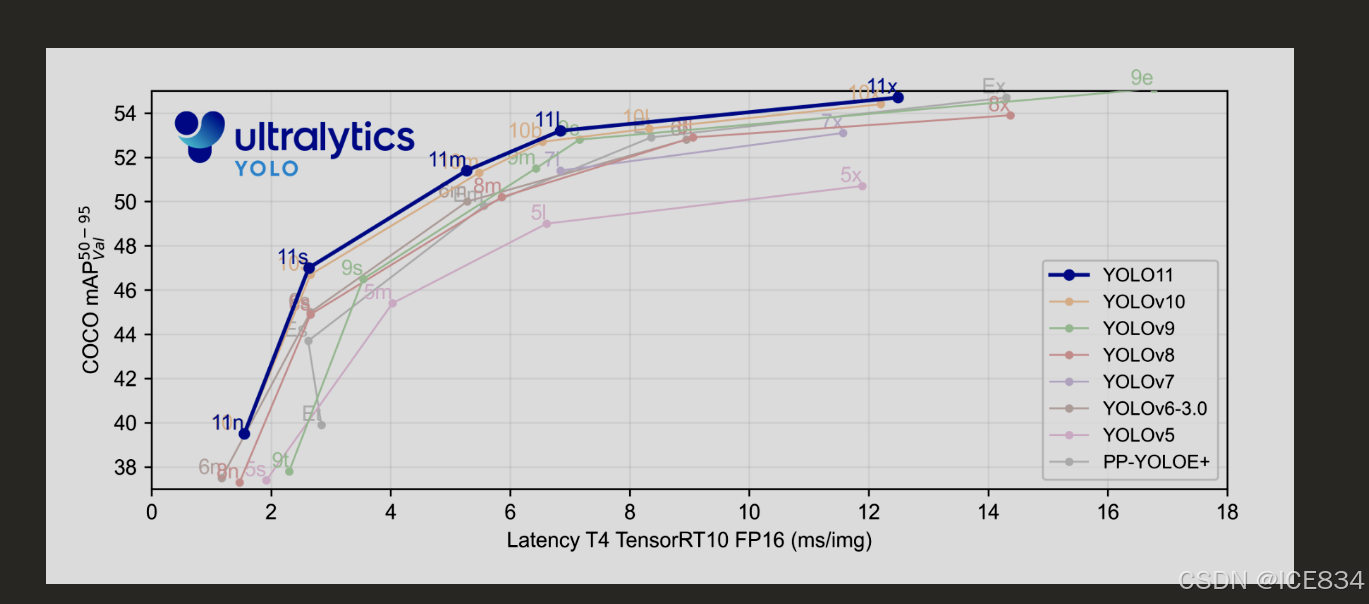
Figure 2:Benchmarking YOLOv11 Against Previous Versions [23]
图 2:将 YOLOv11 与以前的版本进行基准测试 [23]
-
ation, potentially leading to improved detection accuracy across various scenarios.
2. 架构创新:该模型融合了新颖的架构元素,增强了其特征提取和处理能力。C3k2 嵌段、SPPF 和 C2PSA 等新元件的掺入有助于更有效的特征提取和加工。这些增强功能使模型能够更好地分析和解释复杂的视觉信息,从而有可能提高各种场景的检测准确性。 -
3.
Multi-Task Proficiency: YOLO11’s versatility extends beyond object detection, encompassing tasks such as instance segmentation, image classification, pose estimation, and oriented object detection. This multi-faceted approach positions YOLO11 as a comprehensive solution for diverse CV challenges.
3. 多任务熟练度:YOLO11 的多功能性不仅限于对象检测,还包括实例分割、图像分类、姿态估计和定向对象检测等任务。这种多方面的方法将 YOLO11 定位为应对各种 CV 挑战的综合解决方案。 -
4.
Enhanced Attention Mechanisms: A key advancement in YOLO11 is the integration of sophisticated spatial attention mechanisms, particularly the C2PSA component. This feature enables the model to focus more effectively on critical regions within an image, enhancing its ability to detect and analyze objects. The improved attention capability is especially beneficial for identifying complex or partially occluded objects, addressing a common challenge in object detection tasks. This refinement in spatial awareness contributes to YOLO11’s overall performance improvements, particularly in challenging visual environments.
4. 增强的注意力机制:YOLO11 的一个关键进步是集成了复杂的空间注意力机制,尤其是 C2PSA 组件。此功能使模型能够更有效地关注图像中的关键区域,从而增强其检测和分析对象的能力。改进的注意力功能特别有利于识别复杂或部分遮挡的物体,解决了物体检测任务中的常见挑战。空间感知的这种改进有助于 YOLO11 的整体性能改进,尤其是在具有挑战性的视觉环境中。 -
5.
Performance Benchmarks: Comparative analyses reveal YOLO11’s superior performance, particularly in its smaller variants. The nano model, despite a slight increase in parameters, demonstrates enhanced inference speed and frames per second (FPS) compared to its predecessor. This improvement suggests that YOLO11 achieves a favorable balance between computational efficiency and detection accuracy.
5. 性能基准:比较分析揭示了 YOLO11 的卓越性能,尤其是在其较小的变体中。尽管参数略有增加,但与前代模型相比,纳米模型的推理速度和每秒帧数 (FPS) 有所提高。这一改进表明 YOLO11 在计算效率和检测精度之间实现了良好的平衡。 -
6.
Implications for Real-World Applications: The advancements in YOLO11 have significant implications for various industries. Its improved efficiency and multi-task capabilities make it particularly suitable for applications in autonomous vehicles, surveillance systems, and industrial automation. The model’s ability to perform well across different scales also opens up new possibilities for deployment in resource-constrained environments without compromising on performance.
6. 对实际应用的影响:YOLO11 的进步对各个行业都有重大影响。其更高的效率和多任务处理能力使其特别适用于自动驾驶汽车、监控系统和工业自动化中的应用。该模型在不同规模上表现良好的能力也为在资源受限的环境中部署而不影响性能开辟了新的可能性。
8Conclusion 8结论
YOLOv11 represents a significant advancement in the field of CV, offering a compelling combination of enhanced performance and versatility. This latest iteration of the YOLO architecture demonstrates marked improvements in accuracy and processing speed, while simultaneously reducing the number of parameters required. Such optimizations make YOLOv11 particularly well-suited for a wide range of applications, from edge computing to cloud-based analysis.
YOLOv11 代表了 CV 领域的重大进步,提供了增强的性能和多功能性的引人注目的组合。YOLO 架构的最新版本展示了准确性和处理速度的显着改进,同时减少了所需的参数数量。这种优化使 YOLOv11 特别适合从边缘计算到基于云的分析的广泛应用。
The model’s adaptability across various tasks, including object detection, instance segmentation, and pose estimation, positions it as a valuable tool for diverse industries such as emotion detection [26], healthcare [27] and various other industries [17]. Its seamless integration capabilities and improved efficiency make it an attractive option for businesses seeking to implement or upgrade their CV systems. In summary, YOLOv11’s blend of enhanced feature extraction, optimized performance, and broad task support establishes it as a formidable solution for addressing complex visual recognition challenges in both research and practical applications.
该模型在各种任务中的适应性,包括对象检测、实例分割和姿势估计,使其成为情绪检测 [26]、医疗保健 [27] 和其他各种行业 [17] 等不同行业的宝贵工具。它的无缝集成能力和更高的效率使其成为寻求实施或升级其 CV 系统的企业的有吸引力的选择。总之,YOLOv11 融合了增强的特征提取、优化的性能和广泛的任务支持,使其成为解决研究和实际应用中复杂视觉识别挑战的强大解决方案。
References 引用
-
[1]↑Milan Sonka, Vaclav Hlavac, and Roger Boyle.Image processing, analysis and machine vision.Springer, 2013.
米兰·松卡、瓦茨拉夫·赫拉瓦茨和罗杰·博伊尔。图像处理、分析和机器视觉。施普林格,2013 年。 -
[2]↑Zhengxia Zou, Keyan Chen, Zhenwei Shi, Yuhong Guo, and Jieping Ye.Object detection in 20 years: A survey.Proceedings of the IEEE, 111(3):257–276, 2023.
邹正霞、陈克燕、石振伟、郭玉红和叶杰平。20 年中的物体检测:一项调查。IEEE 会议记录,111(3):257–276,2023 年。 -
[3]↑Zhong-Qiu Zhao, Peng Zheng, Shou-tao Xu, and Xindong Wu.Object detection with deep learning: A review.IEEE transactions on neural networks and learning systems, 30(11):3212–3232, 2019.
Zhong-Qiu Zhao, Peng Zheng, Shou-tao Xu, 和 Xindong Wu.使用深度学习进行对象检测:综述。IEEE 神经网络和学习系统汇刊,30(11):3212–3232,2019 年。 -
[4]↑Muhammad Hussain and Rahima Khanam.In-depth review of yolov1 to yolov10 variants for enhanced photovoltaic defect detection.In Solar, volume 4, pages 351–386. MDPI, 2024.
穆罕默德·侯赛因 (Muhammad Hussain) 和拉希马·卡纳姆 (Rahima Khanam)。深入回顾 yolov1 到 yolov10 变体,以增强光伏缺陷检测。在 Solar 中,第 4 卷 ,第 351-386 页。MDPI,2024 年。 -
[5]↑Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi.You only look once: Unified, real-time object detection.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016.
约瑟夫·雷德蒙、桑托什·迪瓦拉、罗斯·吉尔希克和阿里·法哈迪。您只需看一次:统一的实时对象检测。在 IEEE 计算机视觉和模式识别会议论文集,第 779-788 页,2016 年。 -
[6]↑Juan Du.Understanding of object detection based on cnn family and yolo.In Journal of Physics: Conference Series, volume 1004, page 012029. IOP Publishing, 2018.
基于 cnn family 和 yolo 的对象检测理解。在物理学杂志:会议系列,第 1004 卷,第 012029 页。IOP 出版社,2018 年。 -
[7]↑Joseph Redmon and Ali Farhadi.Yolo9000: better, faster, stronger.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7263–7271, 2017.
约瑟夫·雷德蒙 (Joseph Redmon) 和阿里·法哈迪 (Ali Farhadi)。Yolo9000:更好、更快、更强。在 IEEE 计算机视觉和模式识别会议论文集中,第 7263-7271 页,2017 年。 -
[8]↑Joseph Redmon and Ali Farhadi.Yolov3: An incremental improvement.arXiv preprint arXiv:1804.02767, 2018.
约瑟夫·雷德蒙 (Joseph Redmon) 和阿里·法尔·哈迪 (Ali Far Hadi)Yolov3:渐进式改进。arXiv 预印本 arXiv:1804.02767,2018 年。 -
[9]↑Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao.Yolov4: Optimal speed and accuracy of object detection.arXiv preprint arXiv:2004.10934, 2020.
Alexey Bochkovskiy、Chien-Yao Wang 和 Hong-Yuan Mark Liao。Yolov4:对象检测的最佳速度和准确性。arXiv 预印本 arXiv:2004.10934,2020 年。 -
[10]↑Roboflow Blog Jacob Solawetz.What is yolov5? a guide for beginners., 2020.Accessed: 21 October 2024.
Roboflow 博客 Jacob Solawetz。什么是 yolov5?初学者指南,2020 年。访问时间:2024 年 10 月 21 日。 -
[11]↑Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, et al.Yolov6: A single-stage object detection framework for industrial applications.arXiv preprint arXiv:2209.02976, 2022.
李楚怡, 李璐璐, 江洪亮, 翁开恒, 耿逸飞, 李亮, 柯再丹, 李庆元, 程猛, 聂伟强, et al.Yolov6:用于工业应用的单级对象检测框架。arXiv 预印本 arXiv:2209.02976,2022 年。 -
[12]↑Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao.Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7464–7475, 2023.
Chien-Yao Wang、Alexey Bochkovskiy 和 Hong-Yuan Mark Liao。Yolov7:可训练的免费赠品袋为实时对象检测器设定了新的技术水平。在 IEEE/CVF 计算机视觉和模式识别会议论文集中,第 7464-7475 页,2023 年。 -
[13]↑Francesco Jacob Solawetz.What is yolov8? the ultimate guide, 2023.Accessed: 21 October 2024.
弗朗切斯科·雅各布 ·索拉维茨。什么是 yolov8?终极指南,2023 年。访问时间:2024 年 10 月 21 日。 -
[14]↑Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao.Yolov9: Learning what you want to learn using programmable gradient information.arXiv preprint arXiv:2402.13616, 2024.
Chien-Yao Wang、I-Hau Yeh 和 Hong-Yuan Mark Liao。Yolov9:使用可编程梯度信息学习您想学习的内容。arXiv 预印本 arXiv:2402.13616,2024 年。 -
[15]↑Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, and Guiguang Ding.Yolov10: Real-time end-to-end object detection.arXiv preprint arXiv:2405.14458, 2024.
Ao Wang, Hui Chen, Lihao Liu, Kai Chen, Zijia Lin, Jungong Han, 和 Guiguang Ding.Yolov10:实时端到端对象检测。arXiv 预印本 arXiv:2405.14458,2024 年。 -
[16]↑Glenn Jocher and Jing Qiu.Ultralytics yolo11, 2024.
Glenn Jocher 和 Jing Qiu。Ultralytics yolo11,2024 年。 -
[17]↑Rahima Khanam, Muhammad Hussain, Richard Hill, and Paul Allen.A comprehensive review of convolutional neural networks for defect detection in industrial applications.IEEE Access, 2024.
拉希马·卡南、穆罕默德·侯赛因、理查德·希尔和保罗·艾伦。对用于工业应用中缺陷检测的卷积神经网络的全面回顾。IEEE Access,2024 年。 -
[18]↑Satya Mallick.Yolo - learnopencv.YOLO11: Faster Than You Can Imagine!, 2024.Accessed: 2024-10-21.
萨蒂亚·马利克。Yolo - learnopencv.YOLO11: Faster Than You Can Imagine!,2024 年。访问时间:2024 年 10 月 21 日。 -
[19]↑Jingwen Feng, Qiaofeng An, Jiahao Zhang, Shuxun Zhou, Guangwei Du, and Kai Yang.Application of yolov7-tiny in the detection of steel surface defects.In 2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), pages 2241–2245. IEEE, 2024.
冯静文、安巧峰、张家浩、周淑勋、杜光伟和杨凯。yolov7-tiny 在钢材表面缺陷检测中的应用。2024 年第 5 届人工智能、网络和信息技术 (AINIT) 国际研讨会,第 2241-2245 页。IEEE,2024 年。 -
[20]↑Ultralytics.Instance segmentation and tracking, 2024.Accessed: 2024-10-21.
超溶性药物。实例分割和跟踪,2024 年。访问时间:2024 年 10 月 21 日。 -
[21]↑Ultralytics Abirami Vina.Ultralytics yolo11 has arrived: Redefine what’s possible in ai, 2024.Accessed: 2024-10-21.
Ultralytics Abirami Vina.Ultralytics yolo11 已经到来:重新定义 AI 的可能性,2024 年。访问时间:2024 年 10 月 21 日。 -
[22]↑Viso.AI Gaudenz Boesch.Yolov11: A new iteration of “you only look once.YOLO11: A New Iteration of "You Only Look Once" - viso.ai, 2024.Accessed: 2024-10-21.
Viso.AI 高登茨 ·博施。Yolov11:“你只看一次。YOLO11: A New Iteration of "You Only Look Once" - viso.ai,2024 年。访问时间:2024 年 10 月 21 日。 -
[23]↑Ultralytics.Ultralytics yolov11.https://docs.ultralytics.com/models/yolo11/s, 2024.Accessed: 21-Oct-2024.
超溶性药物。Ultralytics yolov11.https://docs.ultralytics.com/models/yolo11/s,2024 年。访问时间:2024 年 10 月 21 日。 -
[24]↑Rahima Khanam and Muhammad Hussain.What is yolov5: A deep look into the internal features of the popular object detector.arXiv preprint arXiv:2407.20892, 2024.
Rahima Khanam 和 Muhammad Hussain。什么是 yolov5:深入了解流行的对象检测器的内部功能。arXiv 预印本 arXiv:2407.20892,2024 年。 -
[25]↑DigitalOcean.What’s new in yolov11 transforming object detection once again part 1, 2024.Accessed: 2024-10-21.
数字海洋。yolov11 的新功能再次改变对象检测第 1 部分,2024 年。访问时间:2024 年 10 月 21 日。 -
[26]↑Muhammad Hussain and Hussain Al-Aqrabi.Child emotion recognition via custom lightweight cnn architecture.In Kids Cybersecurity Using Computational Intelligence Techniques, pages 165–174. Springer, 2023.
穆罕默德·侯赛因 (Muhammad Hussain) 和侯赛因·阿克拉比 (Hussain Al-Aqrabi)。通过自定义轻量级 cnn 架构识别儿童情绪。在儿童使用计算智能技术的网络安全中,第 165-174 页。施普林格,2023 年。 -
[27]↑Burcu Ataer Aydin, Muhammad Hussain, Richard Hill, and Hussain Al-Aqrabi.Domain modelling for a lightweight convolutional network focused on automated exudate detection in retinal fundus images.In 2023 9th International Conference on Information Technology Trends (ITT), pages 145–150. IEEE, 2023.
Burcu Ataer Aydin、Muhammad Hussain、Richard Hill 和 Hussain Al-Aqrabi。轻量级卷积网络的域建模,专注于视网膜眼底图像中的自动渗出液检测。2023 年第 9 届信息技术趋势国际会议 (ITT),第 145-150 页。IEEE,2023 年。
三. 论文笔记(作者自己觉得有价值的句子和理解)
Yolov11主要是对yolo算法的架构进行了优化。
主要改进的方法或者技术:C3k2(cross stage partial with kernel size 2)块,sppf(spatial pyramid pooling-fast),c2psa(convolutional block with parallel spatial attention)组件。
这些组件提高了模型性能,比如 特征提取
该模型在平均精度,计算效率有改进,重点是参数数量和精度之间的权衡。
重点关注:不同模型尺寸的多功能性
第一段
Yolo 将对象检测视为回归任务 采用单个卷积神经网络来同时预测整个图像的边界框和类概率 简化了检测管道
第二段
表信息:yolo1-4用的darknet框架5-10用的pytorch框架
第三段
Yolo11 适应性强 姿势估计和实例分割在这一代效果很好
第四段
Yolo 通过统一的神经网络架构同时处理边界框回归和对象分类
Yolo 架构核心由3部分组成 主干网络backbone为主要特征提取器,利用卷积神经网络将原始图像数据转换为多尺度特征图。 Neck为中间处理阶段,用专用层聚合和增强不同比例下的特征表示。 头部为预测机制,根据细化的特征图生成用于目标定位和分类的最终输出。
Yolo11 扩展和增强了yolo8的基础 包括架构创新和参数优化
Backbone 从多个比例的输入图像中提取特征,涉及堆叠卷积层和专用块,生成各种分辨率的特征图。
卷积层 用卷积层进行下采样 是特征提取的基础,减小空间维度,增加同道数。
C3k2取代了c2f k2表示使用了较小的内核大小 加快了处理速度
C2psa在sppf后引用 增强了特征图中的空间注意力,让模型能有效关注图像中的重要区域。
Neck 将不同尺度的特征传输到头部进行预测 过程涉及上采样和串联
Head 生成对象检测和分类方面的最终预测 输出对象边界框和类标签
C3k2块 c3k = false c3k2类似c2f模块 采用标准瓶颈结构
C3k2块 c3k = true 瓶颈结构被c3模块取代 允许更深入复杂的特征提取
C3k2块的主要特征 更快处理速度 与单个大型卷积相比 使用两个较小的卷积可以减少计算开销,更快提取特征 参数效率 c3k2是csp瓶颈的更紧凑版本 是架构在可训练参数的数量方面更加高效。
C3k块 允许自定义内核大小提供灵活性
Cbs块 通过3中方式细化特征 提取相关特征进行准确的对象检测 通过批量规范化来稳定和规范化数据流 利用sigmoid线性单元激活函数实现非线性 提高模型性能
最终卷积层和检测层
每个检测分支都以conv2d结尾,这些层减少到边框坐标和类预测所需的输出数量,最终的detect层整合这些预测 用于定位图像中对象的边界框坐标 指示对象存在的客观性分数 用于确定检测到对象的类别的类别分数
第5段
支持的任务类型 目标检测 实例分割 图像分类 姿势估计 定向目标检测 对象跟踪
第6段
Yolov11的进步点 架构优化 c3k2块 具体 提高精度降低复杂性 cv任务的多功能性
优化的速度和性能 简化参数技术 高级特征提取 上下文适应性
第7段
Yolov11 效率和可扩展性 架构创新 多任务熟练度 增强的注意力




















 1882
1882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









