







一.论文原文
What is YOLOv8: An In-Depth Exploration of the Internal Features of the Next-Generation Object Detector
什么是 YOLOv8:深入探索下一代对象检测器的内部特性
Muhammad Yaseen
Department of Sciences and Humanities, National University of Computer and Emerging Sciences, Lahore 54770, Pakistan;*Correspondence: m.yaseen@nu.edu.pk;
Abstract 抽象
This study presents a detailed analysis of the YOLOv8 object detection model, focusing on its architecture, training techniques, and performance improvements over previous iterations like YOLOv5. Key innovations, including the CSPNet backbone for enhanced feature extraction, the FPN+PAN neck for superior multi-scale object detection, and the transition to an anchor-free approach, are thoroughly examined. The paper reviews YOLOv8’s performance across benchmarks like Microsoft COCO and Roboflow 100, highlighting its high accuracy and real-time capabilities across diverse hardware platforms. Additionally, the study explores YOLOv8’s developer-friendly enhancements, such as its unified Python package and CLI, which streamline model training and deployment. Overall, this research positions YOLOv8 as a state-of-the-art solution in the evolving object detection field.
本研究详细分析了 YOLOv8 对象检测模型,重点介绍了其架构、训练技术以及相对于 YOLOv5 等先前迭代的性能改进。对关键创新进行了全面检查,包括用于增强特征提取的 CSPNet 主干、用于卓越多尺度目标检测的 FPN+PAN neck 以及向无锚点方法的过渡。该白皮书回顾了 YOLOv8 在 Microsoft COCO 和 Roboflow 100 等基准测试中的性能,强调了其在不同硬件平台上的高精度和实时功能。此外,该研究还探讨了 YOLOv8 对开发人员友好的增强功能,例如其统一的 Python 包和 CLI,可简化模型训练和部署。总体而言,这项研究将 YOLOv8 定位为不断发展的目标检测领域中最先进的解决方案。
Keywords YOLOv8; Object Detection; Real-Time Image Processing; Computer Vision; Convolutional Neural Networks (CNN)
Keywords YOLOv8;对象检测;实时图像处理;计算机视觉;卷积神经网络 (CNN)
1Introduction 1介绍
Computer vision continues to be a dynamic and rapidly advancing field, enabling machines to interpret and understand visual data [1]. Central to this domain is object detection, a critical task that involves accurately identifying and localizing objects within images or video sequences [2]. Over the years, a range of sophisticated algorithms has been developed to tackle this challenge, with each iteration bringing new advancements and improvements [3].
计算机视觉仍然是一个动态且快速发展的领域,使机器能够解释和理解视觉数据 [1]。该领域的核心是对象检测,这是一项关键任务,涉及准确识别和定位图像或视频序列中的对象 [2]。多年来,已经开发了一系列复杂的算法来应对这一挑战,每次迭代都会带来新的进步和改进 [3]。
A significant breakthrough in object detection came with the introduction of the You Only Look Once (YOLO) algorithm by Redmon et al. in 2015 [4]. The YOLO series revolutionized the field by framing object detection as a single regression problem, where a convolutional neural network processes an entire image in one pass to predict bounding boxes and class probabilities [5]. This approach marked a departure from traditional multi-stage detection methods, offering significant gains in speed and efficiency.
2015 年,Redmon 等人推出了 You Only Look Once (YOLO) 算法 [4],这是对象检测领域的重大突破。YOLO 系列通过将对象检测构建为单个回归问题,其中卷积神经网络一次性处理整个图像以预测边界框和类概率 [5],从而彻底改变了该领域。这种方法与传统的多阶段检测方法不同,在速度和效率方面都有了显著提高。
Building on the success of its predecessors, YOLOv8 introduces advanced architectural and methodological innovations that significantly enhance its accuracy, efficiency, and usability in real-time object detection [6, 7, 8].
YOLOv8 在其前辈的成功基础上引入了先进的架构和方法创新,显著提高了其在实时对象检测中的准确性、效率和可用性 [6, 7, 8]。
1.1Survey Objective
1.1调查目标
The primary objective of this study is to thoroughly evaluate the performance of the YOLOv8 object detection model in comparison to other state-of-the-art detection algorithms. This research will assess the trade-offs between accuracy and inference speed across different versions of YOLOv8 (tiny, small, medium, large) to determine the most suitable model size for various application scenarios.
本研究的主要目的是全面评估 YOLOv8 目标检测模型与其他最先进的检测算法相比的性能。本研究将评估不同版本 YOLOv8 (小、小、中、大) 的准确性和推理速度之间的权衡,以确定最适合各种应用场景的模型大小。
Key areas of focus include:
重点领域包括:
-
1.
The impact of the CSPNet backbone and FPN+PAN neck on feature extraction and multi-scale object detection.
1. CSPNet 主干网和 FPN+PAN neck 对特征提取和多尺度目标检测的影响。 -
2.
The benefits of the anchor-free approach in simplifying training and enhancing detection accuracy.
2. 无锚点方法在简化训练和提高检测准确性方面的好处。 -
3.
The role of YOLOv8’s unified Python package and CLI in streamlining model development, training, and deployment.
3. YOLOv8 的统一 Python 包和 CLI 在简化模型开发、训练和部署方面的作用。 -
4.
The model’s performance on benchmarks such as Microsoft COCO and Roboflow 100, including comparisons with previous YOLO iterations.
4. 模型在 Microsoft COCO 和 Roboflow 100 等基准测试中的性能,包括与以前的 YOLO 迭代的比较。
Furthermore, the study will examine the developer-centric improvements introduced in YOLOv8, such as its compatibility with Darknet and PyTorch frameworks, and the enhanced user experience offered by its Python API and command-line interface. By providing an in-depth exploration of YOLOv8’s innovations and performance, this research seeks to contribute valuable insights to the ongoing development and application of advanced object detection models in the field of computer vision.
此外,该研究将检查 YOLOv8 中引入的以开发人员为中心的改进,例如它与 Darknet 和 PyTorch 框架的兼容性,以及其 Python API 和命令行界面提供的增强用户体验。通过深入探索 YOLOv8 的创新和性能,本研究旨在为计算机视觉领域高级目标检测模型的持续开发和应用提供有价值的见解。
2Evolution of YOLOv8
阿拉伯数字YOLOv8 的进化
YOLOv8[9] emerged as the latest evolution in the YOLO series, developed by Ultralytics in 2023. It builds upon the foundation laid by YOLOv5[10], incorporating significant architectural and methodological innovations. YOLOv8 represents a refinement and expansion of the ideas introduced in YOLOv5, with an emphasis on enhancing both model accuracy and usability for real-time object detection tasks[11, 12].
YOLOv8[9] 是 YOLO 系列的最新发展,由 Ultralytics 于 2023 年开发。它建立在 YOLOv5[10] 奠定的基础之上,融合了重要的架构和方法创新。YOLOv8 代表了 YOLOv5 中引入的思想的改进和扩展,重点是提高模型的准确性和实时对象检测任务的可用性[11, 12]。
This is the YOLOv8 development timeline:
这是 YOLOv8 的开发时间表:
-
•
January 10, 2023: YOLOv8 was officially released, featuring a new anchor-free architecture aimed at simplifying model training and improving detection accuracy across various tasks.
• 2023 年 1 月 10 日,YOLOv8 正式发布,采用全新的无锚架构,旨在简化模型训练并提高各种任务的检测准确性。 -
•
February 15, 2023: Introduction of the YOLOv8 Python package and command-line interface (CLI), streamlining the process of model training, validation, and deployment.
• 2023 年 2 月 15 日:推出 YOLOv8 Python 软件包和命令行界面 (CLI),简化了模型训练、验证和部署的过程。 -
•
March 5, 2023: Implementation of advanced augmentation techniques such as mosaic and mixup augmentation, enhancing the model’s ability to generalize across diverse datasets.
• 2023 年 3 月 5 日:实施高级增强技术,例如马赛克和混合增强,增强了模型跨不同数据集进行泛化的能力。 -
•
April 20, 2023: Integration of the CSPNet backbone for improved feature extraction and a hybrid FPN+PAN neck, optimizing the model’s performance in multi-scale object detection.
• 2023 年 4 月 20 日:集成 CSPNet 主干以改进特征提取和混合 FPN+PAN 颈部,优化模型在多尺度目标检测中的性能。 -
•
June 1, 2023: Support for ONNX and TensorRT formats was added, facilitating deployment on a wider range of hardware platforms, including edge devices.
• 2023 年 6 月 1 日:增加了对 ONNX 和 TensorRT 格式的支持,有助于在更广泛的硬件平台上进行部署,包括边缘设备。
YOLOv8’s release and subsequent updates have significantly influenced the object detection landscape. It is considered a dynamic and evolving model, with ongoing research and development efforts aimed at further enhancing its capabilities. This study delves into the novel techniques and performance metrics introduced in YOLOv8, as detailed in the official Ultralytics documentation and GitHub repository.
YOLOv8 的发布和后续更新对对象检测领域产生了重大影响。它被认为是一种充满活力且不断发展的模型,正在进行的研发工作旨在进一步增强其功能。本研究深入探讨了 YOLOv8 中引入的新技术和性能指标,详见官方 Ultralytics 文档和 GitHub 存储库。
3Architectural Footprint of YOLOv8
3YOLOv8 的架构足迹
YOLOv8 builds upon the strong foundation established by its predecessors in the YOLO family, integrating cutting-edge advancements in neural network design and training methodologies. Similar to earlier versions, YOLOv8 unifies object localization and classification tasks within a single, end-to-end differentiable neural network framework, maintaining the balance between speed and accuracy.
YOLOv8 建立在 YOLO 家族前辈建立的坚实基础之上,集成了神经网络设计和训练方法的前沿进步。与早期版本类似,YOLOv8 将对象定位和分类任务统一在一个端到端的可微分神经网络框架中,从而保持速度和准确性之间的平衡。
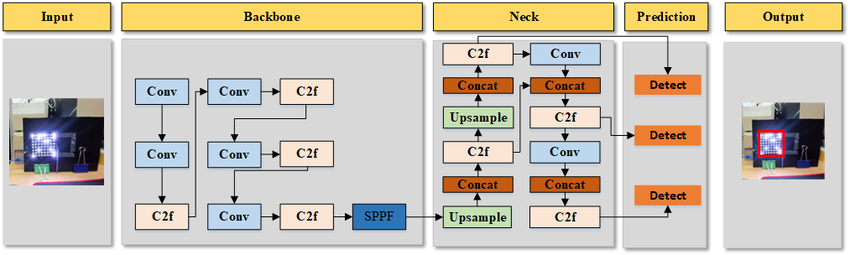
Figure 1:Process of Object Detection [13]
图 1:目标检测过程 [13]
The architecture of YOLOv8 is structured around three core components: Backbone YOLOv8 employs a sophisticated convolutional neural network (CNN) backbone designed to extract multi-scale features from input images. This backbone, possibly an advanced version of CSPDarkne
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7329
7329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









