






上次老师布置了一个实验:
这次在上次的基础上又布置了一个实验,也是做了好久才做出,所以把实验报告放到CSDN保存,自己忘了方便查阅,也为其他人提供借鉴。
实验源码自取:
卢东艺/pytorch_cv_nlp - 码云 - 开源中国 (gitee.com)![]() https://gitee.com/Ludongyi/pytorch_cv_nlp
https://gitee.com/Ludongyi/pytorch_cv_nlp
手写数字加法器
- 实验目标和要求
目标:
1.学会pytorch框架。
2.学会CNN网络原理。
3.学会迁移学习原理。
近年来,迁移学习受到广泛关注,相关研究呈现出持续的指数式增长,在计算机视觉、自然语言处理、语音识别等领域,已经掀起了新一波的浪潮,有望引领下一代人工智能商业化应用。本实验针对MNIST手写数字识别数据集,首先设计实现一个手写数字识别模型,然后在此基础之上,利用迁移学习,实现一个手写数字加法器,输入两张手写数字图像,输出这两个数字的和。具体要求如下:
1. 在PyCharm平台上,基于PyTorch实现。
2. 使用第一次实验的MNIST数据集。
3. 首先设计实现一个基于PyTorch的CNN模型,训练、测试,保留其最优参数。
4. 基于第三步的模型,通过迁移学习,以“微调”方式实现端到端的手写加法器。模型的输入是手写数字图像,最终输出是对应两个数字的和。
5. 不使用迁移学习,从头开始训练一个CNN模型,实现同样的手写数字加法功能。
6. 在同一张图上画出两种方法的错误率曲线图,横坐标为训练时间或者迭代次数,纵坐标为错误率。
7. 结合曲线图,对两种方法进行分析比对。
- 实验过程(含错误调试)
1.迁移模型
神经网络结构图:
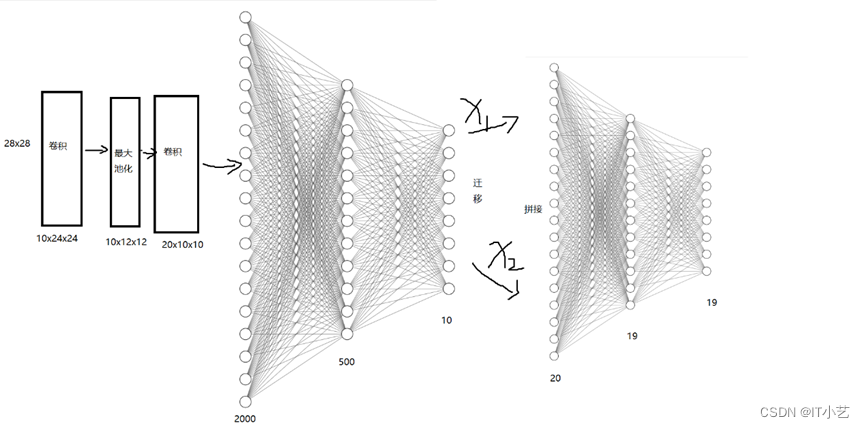
模型的处理流程:
首先设计实现一个基于PyTorch的CNN模型,训练、测试,保留其最优参数,跟上次实验一样。保留的模型命名为cnn.pth,留着进行下一步。
打开并统计数据集,发现训练集有50000个,验证集有10000个,测试集有10000个。根据题目要求,把训练集和验证集分成两部分,测试集单独加载图片进行测试。
对各两部分数据集的图像矩阵转成张量 ,把图像张量和目标张量一一对应放到 TensorDataset()函数转成迭代器对象,然后调用DataLoader()函数分批打包数据,生成迭代器对象。最终返回两个训练集对象,两个验证集对象。单独加载测试图片,把mnist.pkl里的图片imwrite()保存下载来,编号为1到20,加载图片和数字,转成张量放到字典,用于测试。
定义Adder类,继承Model类,实现初始化网络、把预训练好的手写数字识别网络模型对象传入加法器模型,再定义全连接层Linear(20,19)和Linear(19,19),对于每次输入的两张图片,先输入到预训练的模型,分别输出张量为10的概率值,把这两个张量拼接在一起,输入到20个神经元的层,由于两个数相加最大值为18,最小值为0,模型经过训练学习,输出19个值,最大值的数对应的下标就是两个数相加的结果。
加法器模型迭代10次,输入训练数据进行前向传播,把结果放进交叉熵损失函数、后向传播计算梯度,更新参数,验证模型,继续迭代,寻找最优参数。
简单版手写数字加法器 - 飞桨AI Studio星河社区 (baidu.com)
2.非迁移模型
神经网络结构图:
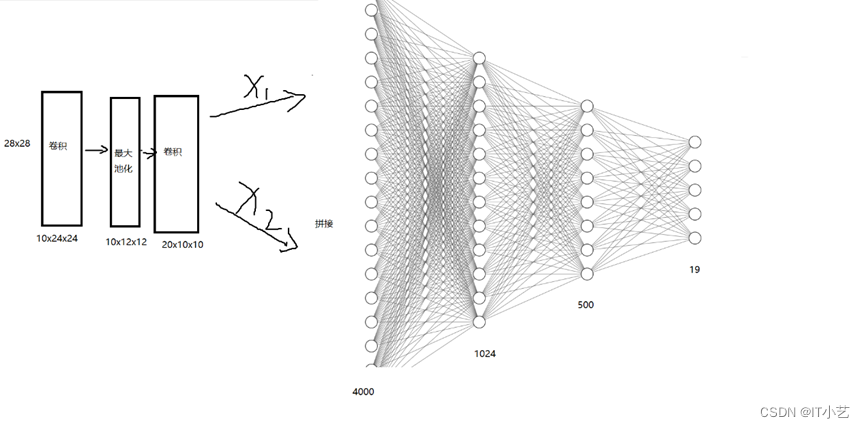
模型的处理流程:
定义MNIST_Adder类,继承Model类,参考上面迁移模型的想法,使用Sequential()函数将模型模块化,分成conv卷积模块和fc全连接模块,对于每次输入的两张图片,conv卷积模块负责对图片进行卷积和最大池化操作,分别获得维度为2000的特征向量,然后把这两个特征向量拼接在一起输入全连接层,最后输出长度为19的张量,里面最大值的下标索引就是两个数的相加结果。
加法器模型迭代10次,输入训练数据进行前向传播,把结果放进交叉熵损失函数、后向传播计算梯度,更新参数,验证模型,继续迭代,寻找最优参数。
迁移模型:
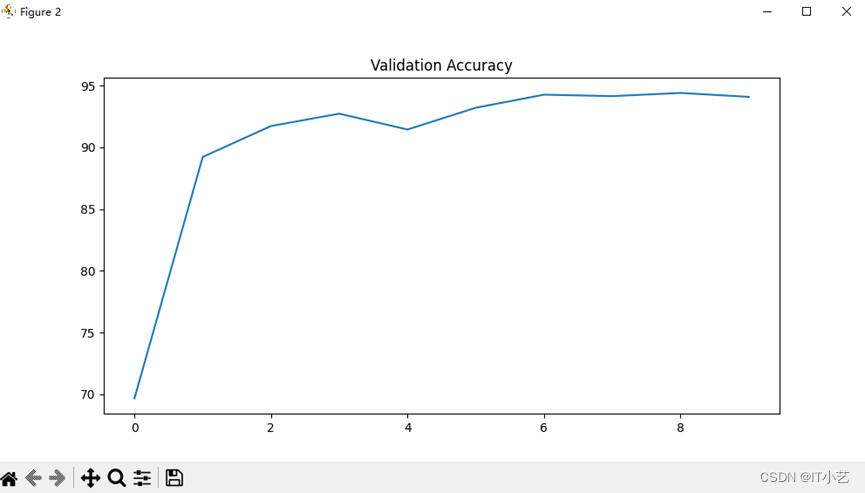
当批量大小batch_size=200,迭代次数为10,AdamW优化器的参数lr=0.003,weight_decay=0.002,使用交叉熵损失函数时,运行结果如下:

验证精度在到达95%时开始收敛,最高有96%,为了防止偶然性,使用10组图片进行测试,10组图片的数字相加结果都正确。
非迁移模型:
当批量大小batch_size=200,迭代次数为10,AdamW优化器的参数lr=0.002,weight_decay=0.003,使用交叉熵损失函数时,运行结果如下:
验证精度在到达94%时开始收敛,为了防止偶然性,使用10组图片进行测试,10组图片的数字相加结果中有一组错误。
可见非迁移模型的验证精度和测试结果准确率都不如迁移模型的。
......
- 总结
学到了许多,对pytorch框架的使用更熟练了。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











