






 本文介绍如何使用R语言对数据框进行各种操作,包括选择特定变量、剔除变量、设定条件筛选观测值、选定时间范围、随机抽样等实用技巧。
本文介绍如何使用R语言对数据框进行各种操作,包括选择特定变量、剔除变量、设定条件筛选观测值、选定时间范围、随机抽样等实用技巧。
##1.创建leadership数据框
manager <- c(1,2,3,4,5)
date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09")
country <- c("US", "US", "UK", "UK", "UK")
gender <- c("M", "F", "F", "M", "F")
age <- c(32,45,25,39,99)
q1 <- c(5,3,3,3,2)
q2 <- c(4,5,5,3,2)
q3 <- c(5,2,5,4,1)
q4 <- c(5,5,5,NA,2)
q5 <- c(5,5,2,NA,1)
leadership <- data.frame(manager, date, country, gender, age,
q1,q2,q3,q4,q5, stringsAsFactors = FALSE)
从leadership数据框中选择变量q1, q2, q3, q4, q5,并将其保存到数据框newdata中
方法1:直接取 数据集名称[,]
newdata <- leadership[, c(6:10)]
myvars <- c("q1", "q2", "q3", "q4", "q5")
##myvars <- paste("q", 1:5, sep = "")
newdata = leadership(, myvars)
剔除变量q4、q5
方法1:
myvars <- names(leadership) %in% c("q4", "q5")
##names(leadership)中的每一个检查其中的每一个元素是否被包含于c(“q4”, “q5”),所以myvars一个由真假值组成的vector: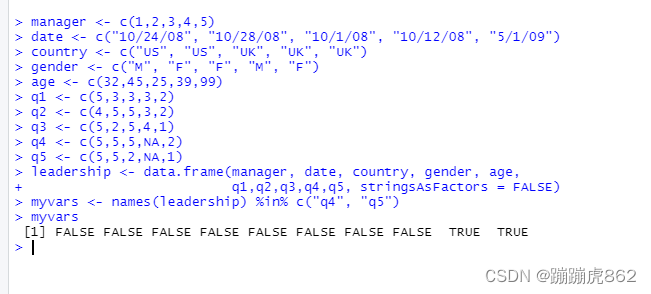
newdata <- leadership[!myvars]
方法2:
idx <- which(names(leadership) == c("q4","q5")) ##返回9 10
newdata <- leadership[-idx] ##- 表示除此之外
leadership[idx] <- NULL
##newdata <- leadership[!idx] 返回data frame with 0 columns and 5 rows方法3:
leadership$q4 <- NULL
leadership$q5 <- NULL设定条件gender为M,age大于30的选入观测值
方法1:
newdata <- leadership[leadership$gender == "M" & leadership$age >30,]方法2:
attach(leadership)
newdata <- leadership[gender == "M" & age > 30,]
detach(leadership)
##attach(),避免使用leadership$gender、leadership$age
##记得detach(),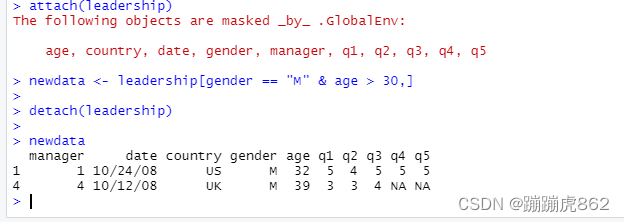
选定时间范围在2009-01-01~2009-10-31之间的观测值
leadership$date <- as.Date(leadership$date, "%m/%d/%y")
##as.data(),将leadership$data改成日期格式
startdate <- as.Date("2009-01-01")
##开始时间,方便用比较进行限定
enddate <- as.Date("2009-10-31")
##结束时间,同上 as.data()函数改变其格式
newdata <- leadership[which(leadership$date >= startdate & leadership$date <= enddate),]
##同时满足要求截取子集
利用subset函数提取子集
选择age大于35或age小于24的行,并保留变量q1到q4
newdata <- subset(leadership, age>=35|age<=24, select = c('q1', 'q2', 'q3', 'q4'))
##subset截取,(数据集,限定条件,保留内容)
选择所有25岁以上的男性,并保留变量gender到q4(即gender到q4和其间的所有列)
newdata <- subset(leadership, age>25 &gender=="M", select = gender:q4)
利用sample函数从leadership数据集中随机抽取大小为3的样本
mysample <- leadership[sample(1:nrow(leadership), 3, replace = FALSE),]
##sample(范围,个数,是否重复抽样)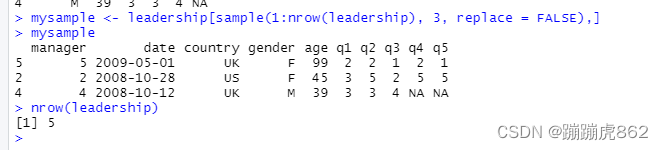

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









