



 本文介绍如何从NCBI网站下载特定基因组数据,并通过Linux命令进行解压及信息提取。具体步骤包括使用wget下载文件、gunzip解压.gz文件,以及利用grep和awk等工具处理并统计基因信息。
本文介绍如何从NCBI网站下载特定基因组数据,并通过Linux命令进行解压及信息提取。具体步骤包括使用wget下载文件、gunzip解压.gz文件,以及利用grep和awk等工具处理并统计基因信息。
第一步、找到目的文件下载:
1、登录NCBI网站(https://ftp.ncbi.nlm.nih.gov或者https://www.ncbi.nlm.nih.gov)
##FTP:文件传输协议FTP,它支持不同种类主机系统之间的文件传输
##WWW:万维网www是一个大规模的、联机式的信息储藏所/资料空间,是无数个网络站点和网页的集合
##HTTP:超文本传输协议
2、按目录(genomes/all/GCA/000/817/325/GCA_000817325.1_ASM81732v1)找到目的基因及其注释
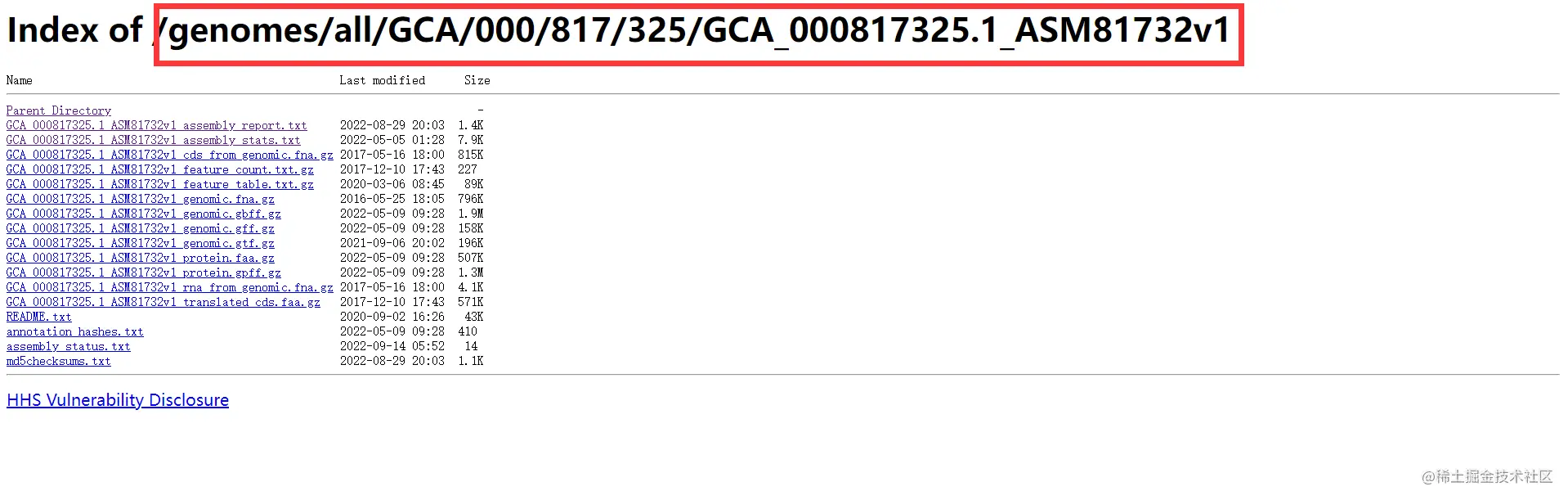
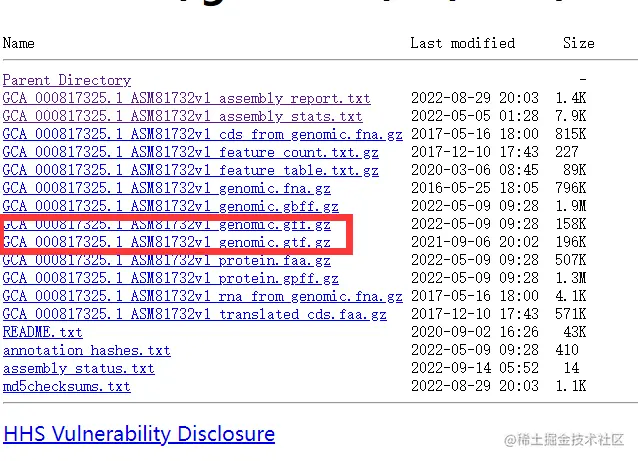
将其网址复制到Linux下:
wget https://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/000/817/325/GCA_000817325.1_ASM81732v1/GCA_000817325.1_ASM81732v1_genomic.gff.gz
##wget:wget支持HTTP,HTTPS和FTP协议
##可以使用参数-O来指定一个文件名:
##wget -O wordpress.zip http://www.minjieren.com/download.aspx?id=1080
##使用wget –limit -rate限速下载:
##wget --limit-rate=300k http://www.minjieren.com/wordpress-3.1-zh_CN.zip
##使用wget -b后台下载:
##wget -b http://www.minjieren.com/wordpress-3.1-zh_CN.zip
第二步、解压该文件查看:
1、ls查看当前目录下是否下载该文件:
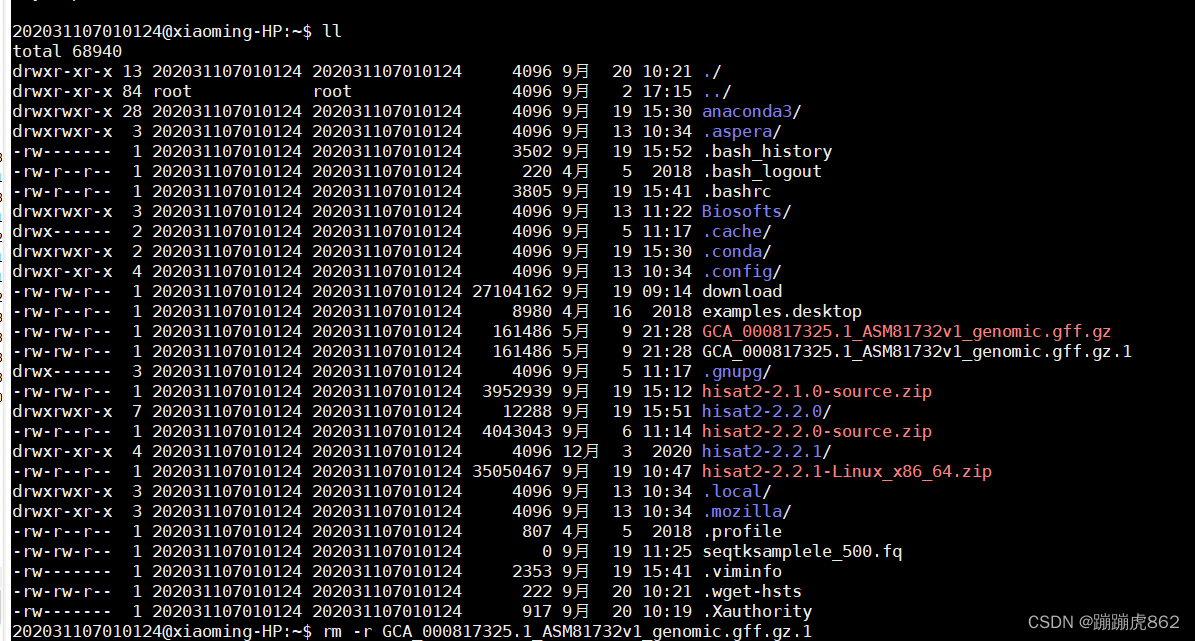
##命令“ll”是“ls -l"的别名,"ll"和“ls -l”的功能是一样的。
-a 列出目录下的所有文件,包括以 . 开头的隐含文件。
-b 把文件名中不可输出的字符用反斜杠加字符编号(就象在C语言里一样)的形式列出。
ls -l是显示当前目录下文件详细信息,ls是显示当前目录下文件。
2、解压该文件:
gunzip GCA_000817325.1_ASM81732v1_genomic.gff.gz
##.gz文件,所以使用gunzip命令解压
## .gz
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
.tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
.zip
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
.tar
解包: tar xvf FileName.tar
打包:tar cvf FileName.tar DirName (详见“压缩详解”)
第三步、处理统计信息:
命令grep,文本搜索(正则匹配)
grep 完整语法结构
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
grep常用的参数总结
| 参数选项 | 解释说明 |
|---|---|
| -V | 排除匹配结果 |
| -n | 显示匹配行与行号 |
| -i | 不区分大小写 |
| -c | 只统计匹配行数 |
| -E | 使用egrep命令 |
| -o | 只输出匹配内容 |
| -w | 只输出过滤的单词 |
| -F | 不适用正则表达式 |
| -l | 列出包含匹配项的文件名 |
| -L | 列出不包含匹配项的文件名 |
^ 用于模式最左侧,如 “^yu” 即匹配以yu开头的单词
$ 用于模式最右侧,如 “yu$” 即匹配以yu结尾的单词
^$ 组合符,表示空行
. 匹配任意一个且只有一个字符,不能匹配空行
| 转义字符
* 重匹配前一个字符连续出现0次或1次以上
.* 匹配任意字符
^.* 组合符,匹配任意多个字符开头的内容
.*$ 组合符,匹配任意多个字符结尾的内容
[abc] 匹配 [] 内集合中的任意一个字符,a或b或c,也可以写成 [ac]
[^abc] 匹配除了 ^后面的任意一个字符,a或b或c,[]内 ^ 表示取反操作
1、less查看文件GCA_000817325.1_ASM81732v1_genomic.gff ,如图:
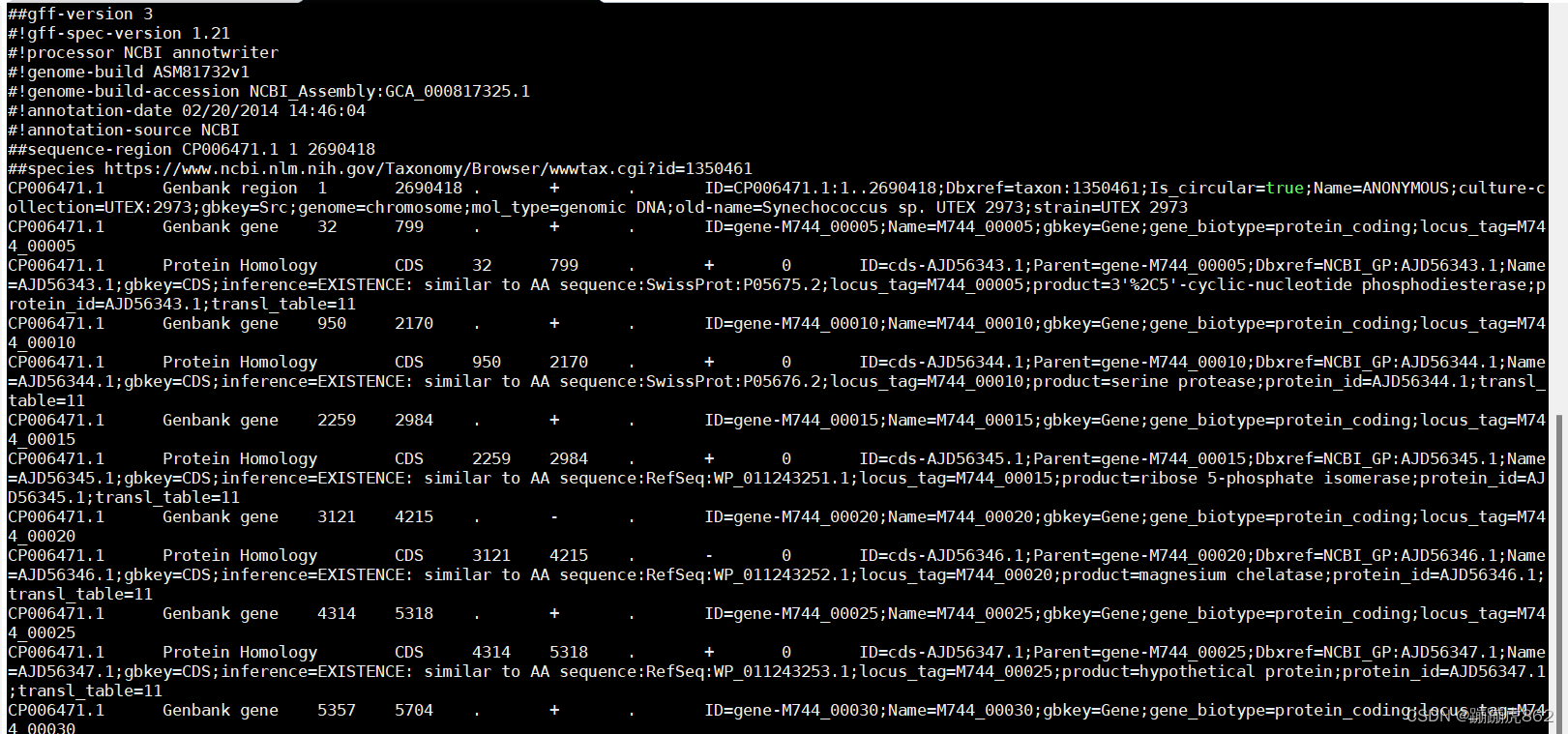
grep '^CP006471.1' GCA_000817325.1_ASM81732v1_genomic.gff |awk -v FS="\t" {if($5<10000){print $_}}'|sort|uniq|wc -l
##要捕捉的基因信息是从左第一个开始,所以使用^(从每行开头匹配)
##awk的用法:-v(定义或者修改内部变量)FS(字段分隔符)OFS(输出字段分隔符)让awk以制表符为分隔符读取第五列信息
##sort排序,uniq合并相同项,wc用于计算字数,-l计算行数,-w计算字数
结果为9行:![]()
易错为10行,原因:未加^,读取了另外的一行(包含CP006471.1,但不在行首)

















 2311
2311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









