







 本文详细介绍了归并排序的基本步骤、图解、时间复杂度(O(nlogn))、空间复杂度(O(n)),以及其在稳定性和并行性方面的优点,展示了归并排序在实际编程中的应用场景。
本文详细介绍了归并排序的基本步骤、图解、时间复杂度(O(nlogn))、空间复杂度(O(n)),以及其在稳定性和并行性方面的优点,展示了归并排序在实际编程中的应用场景。
1.简介
归并排序(Merge Sort)是一种分治法(Divide and Conquer)的典型应用,它将待排序的数据分为两半,分别对这两半进行排序,然后将排序好的两半合并成一个有序的数组。归并排序的时间复杂度为O(nlogn),空间复杂度为O(n)。
2. 基本步骤
归并排序,顾名思义先归(递归)后并(合并)的一种排序方式,将数组的数据分而治之。
基本步骤如下:
- (归)将待排序的数据通过递归拆分到只有一个元素,那么它已经是有序的,直接返回。
- (并)将排序好的两半合并成一个最终的有序数组。
3. 图解
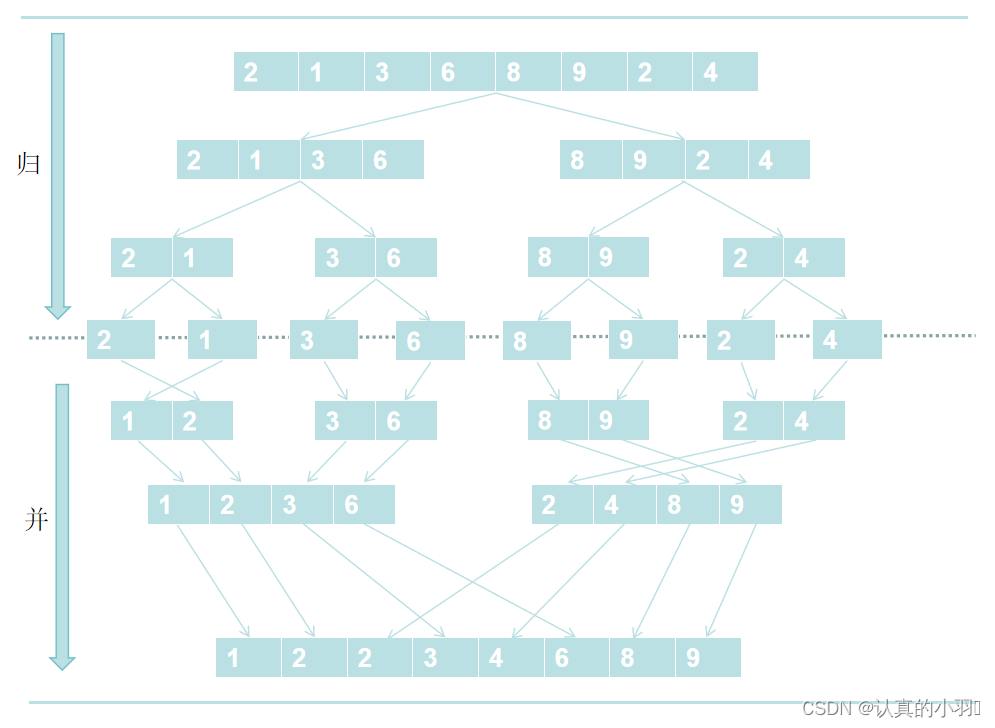
先归, 通过递归二分数组,分到数组不能再分了,分成了一个一个单独的元素,此时每个单独的元素必然有序。
后并,将两两数组进行合并,合并时保证数组有序,依次合并。在子数组有序的情况下,再合并两数组,最终使整个数组合并。
4. 复杂度分析
4.1 时间复杂度
时间复杂度通常是O(nlogn),由于归并排序采用分治策略,将原始数组不断分割成更小的子数组进行排序,然后再合并这些已排序的子数组。由于每次分割都将问题规模减半,而每一层合并操作都需要线性时间来完成。所以整体上,归并排序的时间复杂度是对数级别的。
4.2 空间复杂度
空间复杂度是O(n),这是因为在合并过程中,需要一个与原数组相同大小的辅助数组来暂存排序结果。这个辅助数组在每一次合并时都会被使用,因此归并排序需要额外的空间来存储这些临时数据。
5. 代码实现
// 递归将数组二分到不能再分为止
public static void divide(int[] arr, int l, int r){
if (l == r){
return;
}
// int mid = (l + r) / 2;
// int mid = (l + r) >> 1;
int mid = l + ((r - l) >> 1);
divide(arr, l, mid);
divide(arr, mid + 1, r);
merge(arr, l, mid, r);
}
// 合并数组
public static void merge(int[] arr, int l, int mid, int r){
int[] tmp = new int[r - l + 1]; // 辅助数组用于结果
int index = 0;
int p1 = l;
int p2 = mid + 1;
// 对比左右两部分 依次放入 辅助数组 ,即变成有序数组
while(p1 <= mid && p2 <= r){
tmp[index++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
// p1 或 p2 越界后, 代表剩下来的数可以直接放入数组后面
// 将另一部分直接加在数组后
while(p1 <= mid){
tmp[index++] = arr[p1++];
}
while(p2 <= r){
tmp[index++] = arr[p2++];
}
// 将有序数组覆盖原数组部分
for(int i = 0; i < tmp.length; i++){
arr[l + i] = tmp[i];
}
}
6. 总结
归并排序是非常高效的排序算法之一,它的优势主要包括以下几点:
- 时间复杂度低:归并排序的总体时间复杂度为O(nlogn)。这基于比较的排序算法中可达到的最高效率。
- 稳定性高:在归并排序过程中,大小相同的元素能够保持排序前的顺序不变。这一点在某些特定应用场景下特别重要。
- 易于理解和实现:归并排序的原理和步骤相对直观,理解起来比较容易。它通过递归地分割数组至单个元素,然后再将这些元素逐步合并成有序数组。
- 并行性强:归并排序具有天然的并行性,因为每个子序列的合并过程都是独立的。这使得归并排序非常适合于并行计算环境。
总的来说,尽管归并排序的空间复杂度相对较高,但它在时间效率、稳定性以及易于理解等方面的优势使其作用域多种场景下,比如 Java 的 Arrays.sort() 和 c++ 中对于非随机访问迭代器容器(std::list) 的 std::sort() 都是基于归并排序的。















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









