






 论文介绍了一种结合无线信号和光学图像生成人体姿态的新方法,利用深度学习处理CSI数据和初始图像,通过GAN实现高质量图像合成。实验结果显示,该方法在WiFiDance和WiFiWalk数据集上优于现有技术,具有更好的精度和视觉质量。
论文介绍了一种结合无线信号和光学图像生成人体姿态的新方法,利用深度学习处理CSI数据和初始图像,通过GAN实现高质量图像合成。实验结果显示,该方法在WiFiDance和WiFiWalk数据集上优于现有技术,具有更好的精度和视觉质量。
论文概述
提出了一种通过将无线信号与初始光学图像相结合来生成目标人体姿态图像的框架。使用多个无线设备来收集WiFi信号,并使用相机来捕捉初始光学图像。最后,深度学习模型从处理后的无线信号和初始光学图像中学习生成人体姿态图像。
研究背景
光学相机很容易受到光线不好或浓烟和灰尘的限制。 从无线电信号中提取的信息非常缺乏,只能获得人类的低分辨率姿势,而环境信息被完全遗漏。
解决方法:
将无线电信号与初始光学图像相结合来合成人类活动的光学图像。 照明良好时,初始光学图像可获得环境和人类主体的外观信息。 照明变差后(例如,照明设备关闭、浓烟或灰尘遮挡摄像头等),无线电感应设备就会工作。
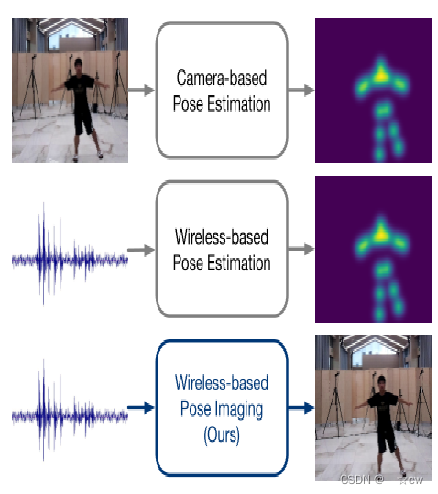
场景构建
本文目标是仅从一个初始图像和WiFi信号生成不同时间的光学人体姿态图像。 系统由两个主要部分组成:数据收集和预处理,以及深度学习模型。
在10米×10米的区域内,有一个配备了一个天线的WiFi发射器和五个接收器,每个接收器配备了三个天线。 受试者被要求在场景中进行一些活动,其中包括各种人体姿势和肢体动作。
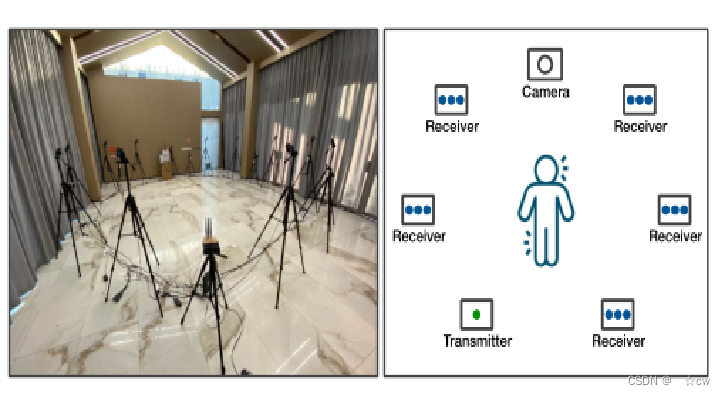
上图是为收集WiFi和视觉数据而构建的场景。 左边是实际场景,右边是显示相机以及WiFi发射器和接收器放置的示意图。
数据分析
CSI会随着人的运动而变化,即CSI包含人的运动信息。 测量的CSI可以表示为
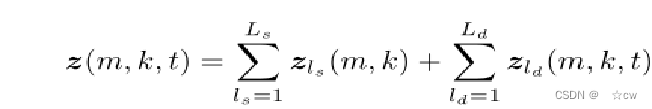
m、 k,t分别表示天线、子载波和时间的索引 zls表示由室内环境引入的静态信号传播路径,它是时不变的 zld是由移动的人反射的信号,它由于人的移动而是时变的。
由于CSI中涉及的信息有限,故利用多个接收器来通过获取更多信息。 CSI包含几种时变相位偏移,会影响传感性能,本文仅利用CSI的幅度,即z的绝对值,作为神经网络的输入。
模型结构
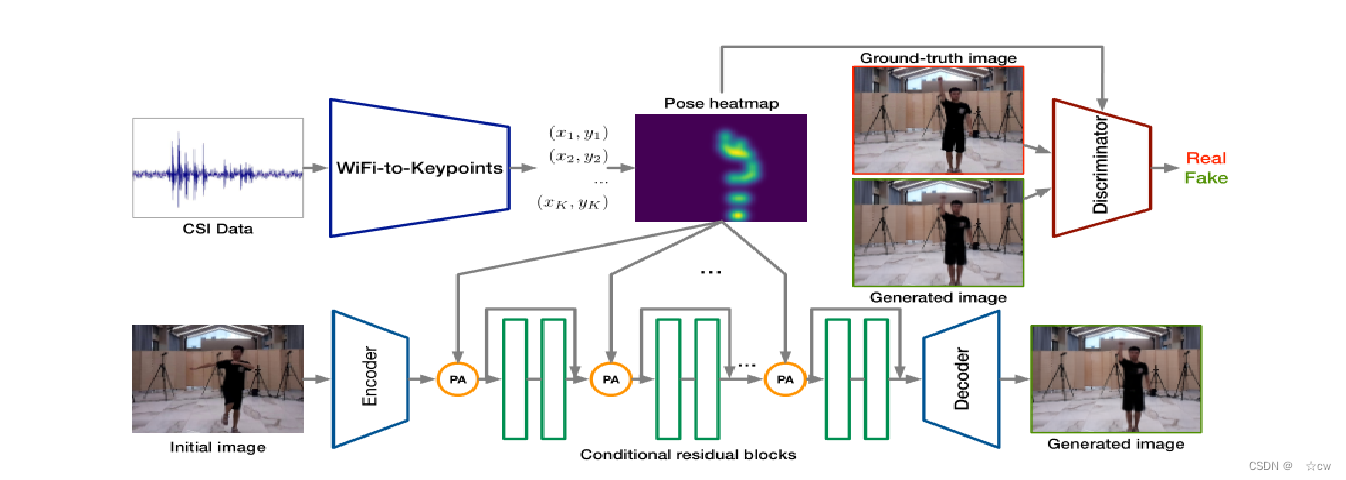
主要包括两个部分: 一个从CSI数据预测姿态关键点的轻量级WiFi——关键点网络 一个生成基于预测姿态和初始图像的光学图像的GAN网络。
CSI用维度R×F×N表示,R表示接收天线的数量,F表示子载波数量,N表示一定时间内WiFi帧的数量。 由于WiFi信号的低空间分辨率,单个WiFi帧可能会错过一些肢体,并且无法对身体运动的动力学进行建模。因此输入从一段时间(例如0.1s)获得的多个WiFi帧,然后遵循几个卷积层来提取信息。 最后,采用仿射变换M来获得姿势关键点坐标: p_k×2^^=M[CNN(z)] 目标函数是最小化每个关键点的预测坐标与相应真值之间的误差: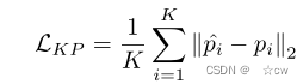
p_i^表示第i个关键点的预测坐标,pi是真值坐标
WiFi信号只能捕捉人体的运动,不能获得环境信息,本文使用初始人体姿态图像来补充WiFi信号的环境信息。 GAN模块主要由三部分组成:编码器网络、一系列条件残差块、解码器网络 将关键点像素坐标转换为高斯热图h,然后使用Pose-Attention(PA)操作将姿势热图h与从初始图像中提取的特征相组合: 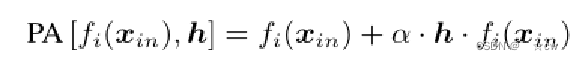
h可以被视为热图权重,α用于调整注意力水平 在每个残差块的输入层中应用PA运算,确保了生成器将初始人体姿态图像转换为具有目标人体姿态的图像。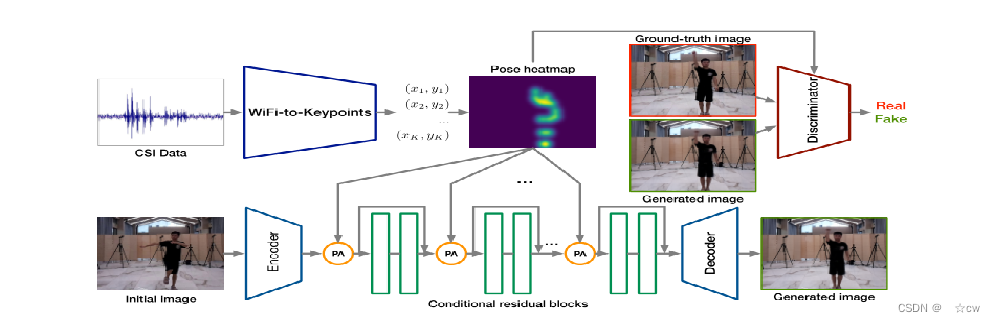
实验部分
总共创建了两种类型的WiFi Vision数据集,即WiFi Dance和WiFi Walk。
| 方法 | WiFi Dance | WiFi Walk |
| Person-in-WiFi | 0.839 | 0.542 |
| 本文的方法 | 0.875 | 0.851 |
Person-in-WiFi: 使用去卷积层对输入WiFi数据进行上采样 使用编码器-解码器网络来提取信息 使用额外的卷积层对信息进行下采样以生成关键点热图 可以看出,本文的方法在两个数据集上都优于Person-in-WiFi
评估来自以下几个方面:
图像质量(FID):它计算生成的图像集和真实图像之间的Fréchet启始距离。距离越小,质量越好 图像相似性(SSIM):测量生成的人体姿势图像与真实人体姿势图像之间的相似性,值越高越好 用户调研(User study):随机向受试者展示一些姿势热图,然后询问其是不是与生成图形结果相对应

C2GAN:一种基于关键点的生成对抗性网络,它包含两种不同类型的生成器,即面向关键点的生成器和面向图像的生成器
与上述先进的姿态成像方法相比,本文的方法可以很好地将WiFi信号转换为高质量的人体姿态图像,并且生成的图像与相应的地面实况非常相似。
为了评估我们系统的泛化能力,我们收集了一个从未出现在训练集中的新受试者的数据。
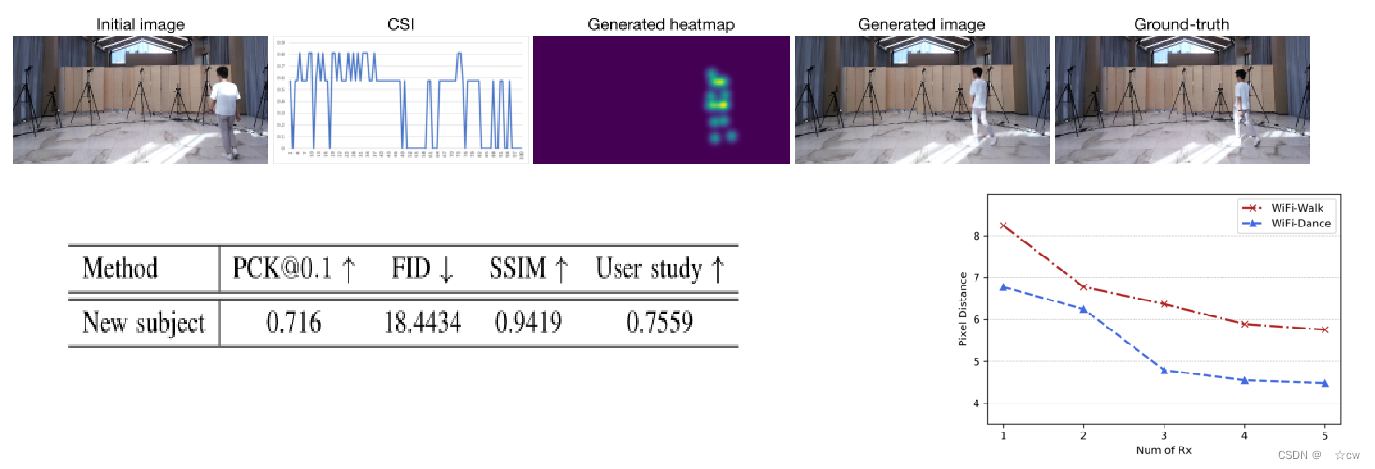
更多的WiFi接收器会得到更小的ℒ_kp像素距离,这意味着系统性能更好。 通过实验来评估本文提出的框架,结果表明,它比最先进的基于WiFi的姿态估计方法具有更高的精度,并且比最新的人工生成方法具有更好的视觉质量。
论文总结
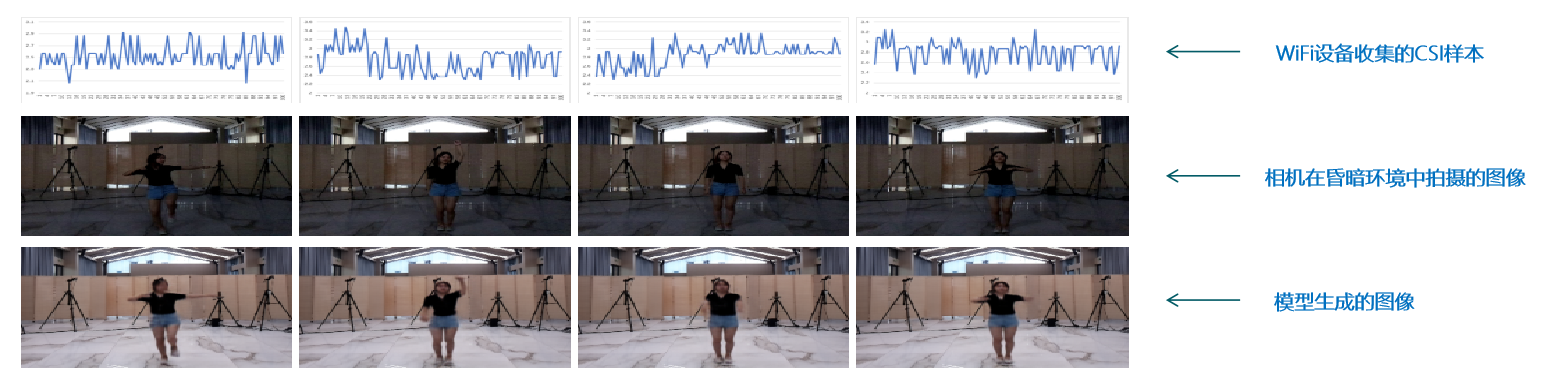
本文首次探索了将WiFi信号和视觉信息融合在一起的技术,并提出了一种基于WiFi信号生成光学人体姿态图像的解决方案。所提出的方法使用无线设备和相机来收集数据,经过数据预处理,设计了一个深度学习模型来直接预测WiFi信号中的姿势关键点坐标,并利用GAN模型来合成高质量图像。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











