






这几天花了些时间读了这边论文,现在我以记笔记的形式为大家用代码讲解这篇文章的主要内容。
0.前向传播的过程
def forward(self, content, style, alpha=1.0):
assert 0 <= alpha <= 1
style_feats = self.encode_with_intermediate(style) #输入一张风格图片
content_feat = self.encode(content) #输入内容图片 输出的维度和style_feats对的维度一样
t = adain(content_feat, style_feats[-1]) #对风格图片 获取它通过relu4_1的特征图 与内容图计算adin
#t为实例化后的 经过实例化后的content_feat
t = alpha * t + (1 - alpha) * content_feat # ?????
g_t = self.decoder(t) #解码出图像
g_t_feats = self.encode_with_intermediate(g_t) #通过VGG19网络获取特征图
loss_c = self.calc_content_loss(g_t_feats[-1], t) #目的是为了训练decode 为了保证生成的图片不损失内容
loss_s = self.calc_style_loss(g_t_feats[0], style_feats[0]) #为了训练decode 为了保证生成的图片风格与style_image类似
for i in range(1, 4):
loss_s += self.calc_style_loss(g_t_feats[i], style_feats[i])
return loss_c, loss_s
这是论文中的网络结构。我用我自己的理解来讲述一下前向传播的过程,1.该过程输入两张图片,style是我们想要的图片内容,content是我们想要的图片内容,整个网络的目的是将content的图片风格转换为style的图片风格。2.将style输入进编码器,并分别得到relu1->relu4输出的特征图谱,这些特征图谱包含了style的风格信息。(将这些特征图谱命名未style_feature) 将content也输入进编码器,但是只获得relu4输出的特征图谱(将其命名为content_feature) 3.content_feature和style_feature[4]输入进AdaIN 进行自适应实例特征化(将经过AdaIN的输出命名为t)4.将t输入进decoder,将特征图谱转化为图片。4.将decoder产生的图片输入进encoder得到对应的特征图谱 并且计算内容损失和风格损失用来优化decoder。
1.解码器和编码器
decoder = nn.Sequential(
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 256, (3, 3)),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='nearest'),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 256, (3, 3)),
nn.ReLU(),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 256, (3, 3)),
nn.ReLU(),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 256, (3, 3)),
nn.ReLU(),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 128, (3, 3)),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='nearest'),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(128, 128, (3, 3)),
nn.ReLU(),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(128, 64, (3, 3)),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='nearest'),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(64, 64, (3, 3)),
nn.ReLU(),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(64, 3, (3, 3)),
)
vgg = nn.Sequential(
nn.Conv2d(3, 3, (1, 1)),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(3, 64, (3, 3)),
nn.ReLU(), # relu1-1
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(64, 64, (3, 3)),
nn.ReLU(), # relu1-2
nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(64, 128, (3, 3)),
nn.ReLU(), # relu2-1
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(128, 128, (3, 3)),
nn.ReLU(), # relu2-2
nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(128, 256, (3, 3)),
nn.ReLU(), # relu3-1
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 256, (3, 3)),
nn.ReLU(), # relu3-2
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 256, (3, 3)),
nn.ReLU(), # relu3-3
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 256, (3, 3)),
nn.ReLU(), # relu3-4
nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(256, 512, (3, 3)),
nn.ReLU(), # relu4-1, this is the last layer used
#(batch_size, 512, 224, 224)
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 512, (3, 3)),
nn.ReLU(), # relu4-2
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 512, (3, 3)),
nn.ReLU(), # relu4-3
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 512, (3, 3)),
nn.ReLU(), # relu4-4
nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True),
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 512, (3, 3)),
nn.ReLU(), # relu5-1
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 512, (3, 3)),
nn.ReLU(), # relu5-2
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 512, (3, 3)),
nn.ReLU(), # relu5-3
nn.ReflectionPad2d((1, 1, 1, 1)),
nn.Conv2d(512, 512, (3, 3)),
nn.ReLU() # relu5-4
)这里我们定义了一个编码器和一个解码器,其中编码器采用的是VGG19的网络,这其中我们用到的就是relu1-->relu4的结构,用以获取图片的特征图谱。解码器采用了一个与编码器对称的网络结构.
2.定义函数获取不同relu层输出的特征图谱
def __init__(self, encoder, decoder):
super(Net, self).__init__()
enc_layers = list(encoder.children())
self.enc_1 = nn.Sequential(*enc_layers[:4]) # input -> relu1_1
self.enc_2 = nn.Sequential(*enc_layers[4:11]) # relu1_1 -> relu2_1
self.enc_3 = nn.Sequential(*enc_layers[11:18]) # relu2_1 -> relu3_1
self.enc_4 = nn.Sequential(*enc_layers[18:31]) # relu3_1 -> relu4_1
self.decoder = decoder
self.mse_loss = nn.MSELoss()
# fix the encoder
for name in ['enc_1', 'enc_2', 'enc_3', 'enc_4']:
for param in getattr(self, name).parameters():
param.requires_grad = False可以看到,我们的编码器网络参数不参与更新。
3.定义获取特征图谱的函数
# extract relu1_1, relu2_1, relu3_1, relu4_1 from input image
def encode_with_intermediate(self, input):
results = [input]
for i in range(4):
func = getattr(self, 'enc_{:d}'.format(i + 1))
results.append(func(results[-1]))
return results[1:]
# extract relu4_1 from input image
def encode(self, input):
for i in range(4):
input = getattr(self, 'enc_{:d}'.format(i + 1))(input)
return input4.定义两个损失函数
def calc_content_loss(self, input, target):
assert (input.size() == target.size())
assert (target.requires_grad is False)
return self.mse_loss(input, target)
def calc_style_loss(self, input, target):
assert (input.size() == target.size())
assert (target.requires_grad is False)
input_mean, input_std = calc_mean_std(input)
target_mean, target_std = calc_mean_std(target)
'''对每个图片进行通道上的均值和方差的计算'''
return self.mse_loss(input_mean, target_mean) + \
self.mse_loss(input_std, target_std)损失函数分别是内容损失和风格损失,这里的风格损失的另一种算法我记得需要算出两个图片的Gram矩阵,然后用MSE计算损失。
5.定义计算图像均值和方差的损失
def calc_mean_std(feat, eps=1e-5):
# eps is a small value added to the variance to avoid divide-by-zero.
size = feat.size()
assert (len(size) == 4)
N, C = size[:2]
feat_var = feat.view(N, C, -1).var(dim=2) + eps #对输入的图片的每个通道计算标准差
feat_std = feat_var.sqrt().view(N, C, 1, 1) #标准差的平方得到方差
feat_mean = feat.view(N, C, -1).mean(dim=2).view(N, C, 1, 1)
return feat_mean, feat_std这里计算的维度是按照RGB三通道的维度来计算的。
6.定义AdaIN函数
def adaptive_instance_normalization(content_feat, style_feat):
assert (content_feat.size()[:2] == style_feat.size()[:2])
size = content_feat.size()
# [batch,channel,H,W]
style_mean, style_std = calc_mean_std(style_feat)
content_mean, content_std = calc_mean_std(content_feat)
normalized_feat = (content_feat - content_mean.expand(
size)) / content_std.expand(size)
return normalized_feat * style_std.expand(size) + style_mean.expand(size)对应的计算公式:
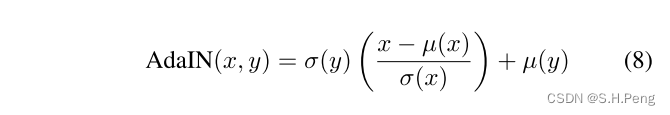
这些计算都是在分别在RGB三个通道里完成的。
自适应主要体现在计算y的均值和方差,它会根据输入不同风格的图片产生不同的均值和方差,相当于是会根据输入的图片改变对应的仿射参数。
由于我对读论文的需求仅仅是想了解AdaIN,所以就不对论文的其他部分进行讲解了。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









