






一下是我对李宏毅老师-自注意力机制的总结
首先看图:

假设我们输入有四个向量,这四个向量是有关系的,而如果我们将self-attention这个模块拿走,那么就相当于是把这四个输入当作毫无关系的向量进行处理然后得到四个输出。所以:self-attention这个模块的作用就是将这四个输入联系起来使我们的输出与这四个输入都有关。假如我们现在要做一个任务输入四张图片:content1,content2,style1,style2,我们想要得到一张包含图片content1,content2的内容同时它又符合图片style1,style2的图片风格的图片,那么我们此时就可以利用注意力机制来对四张图片做一个全方位的考虑,然后再将图片输出(当然,这里说的图片是经过编码后的向量)
明白了注意力机制可以用来做什么,接下来我们来看一看self-attention里具体是如何做的。
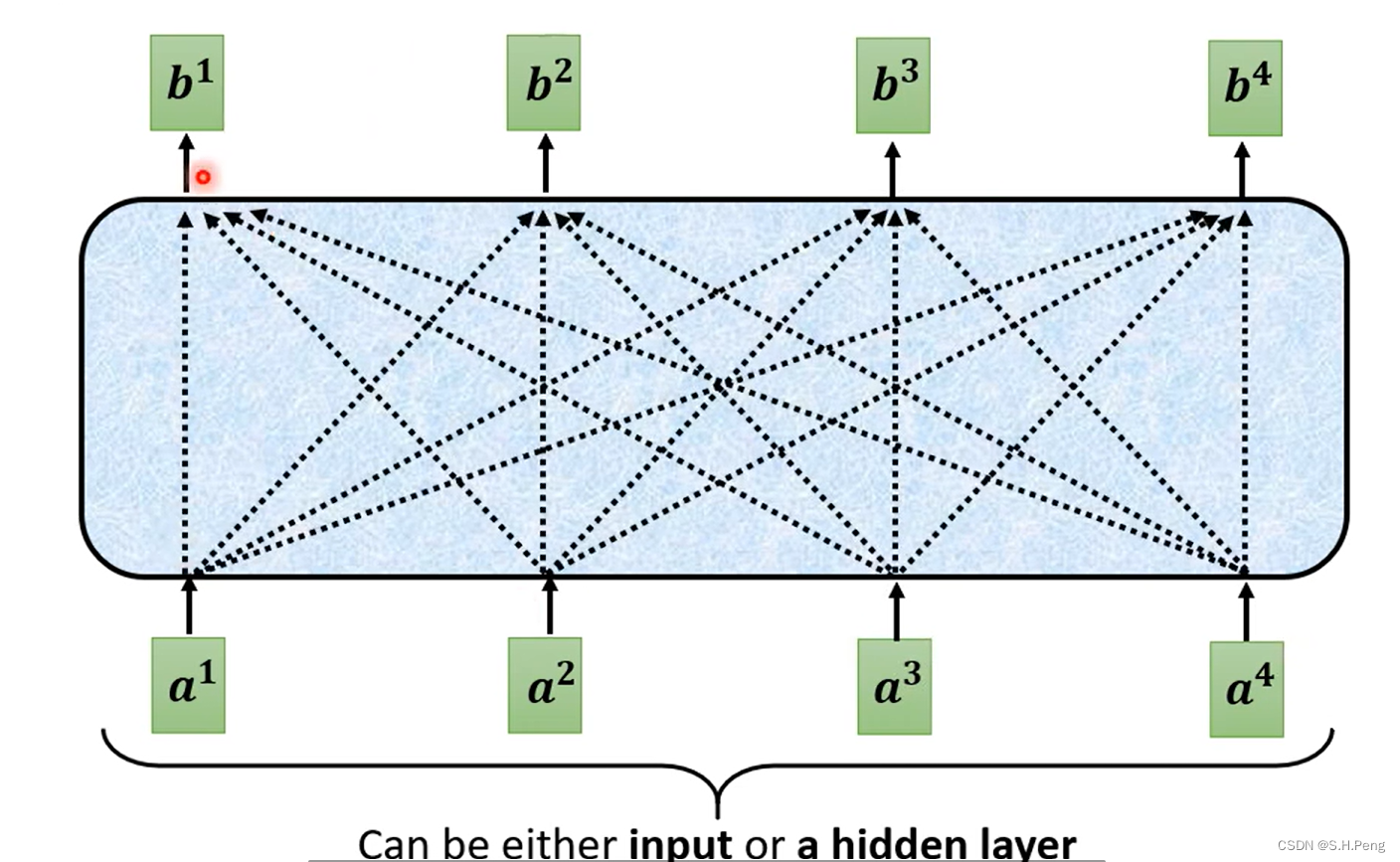
如上图所示,输入出的结果都是充分考虑了四个输入的向量的特征。
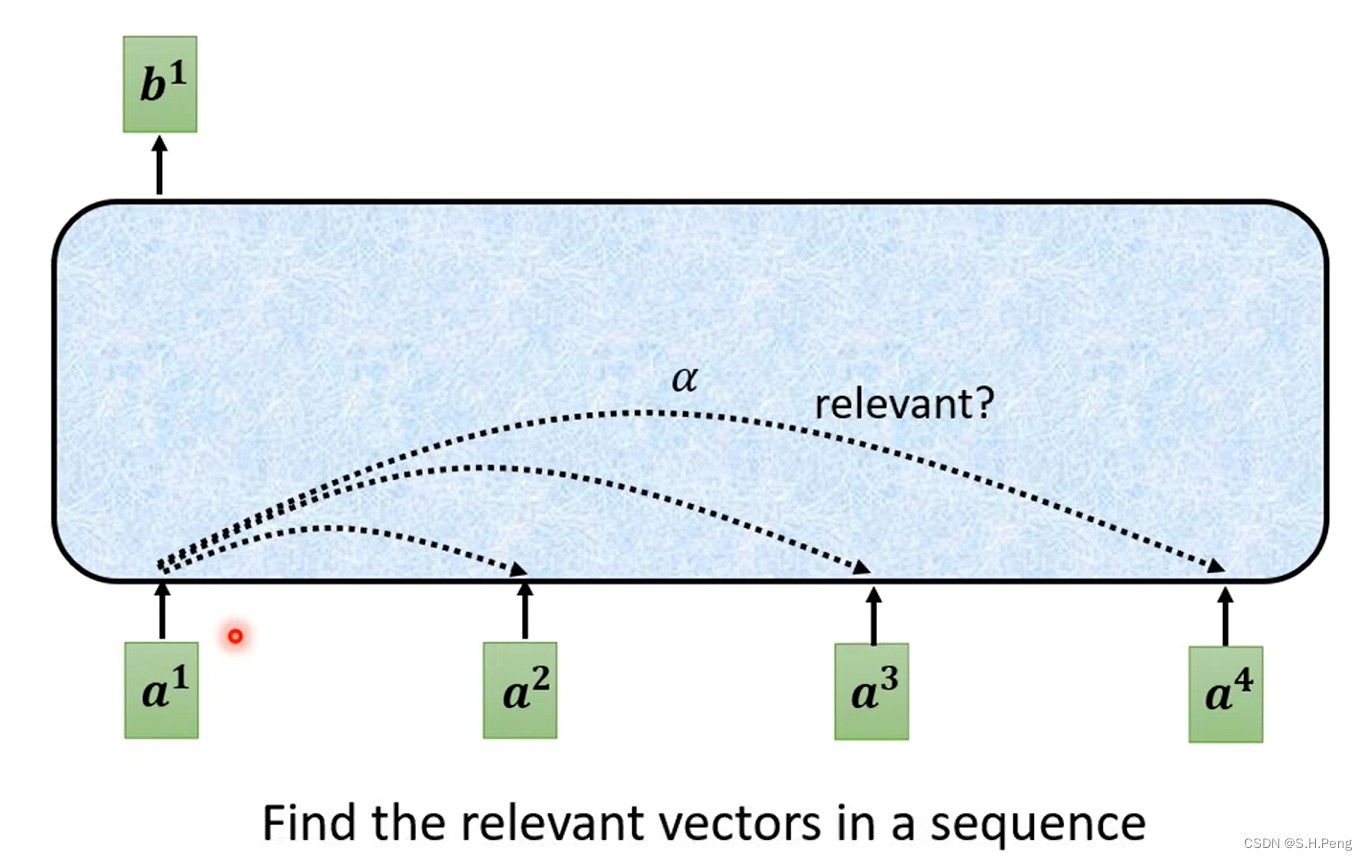
那么接下来我们要知道的是,一个输入是如何与其他输入产生联系的呢?
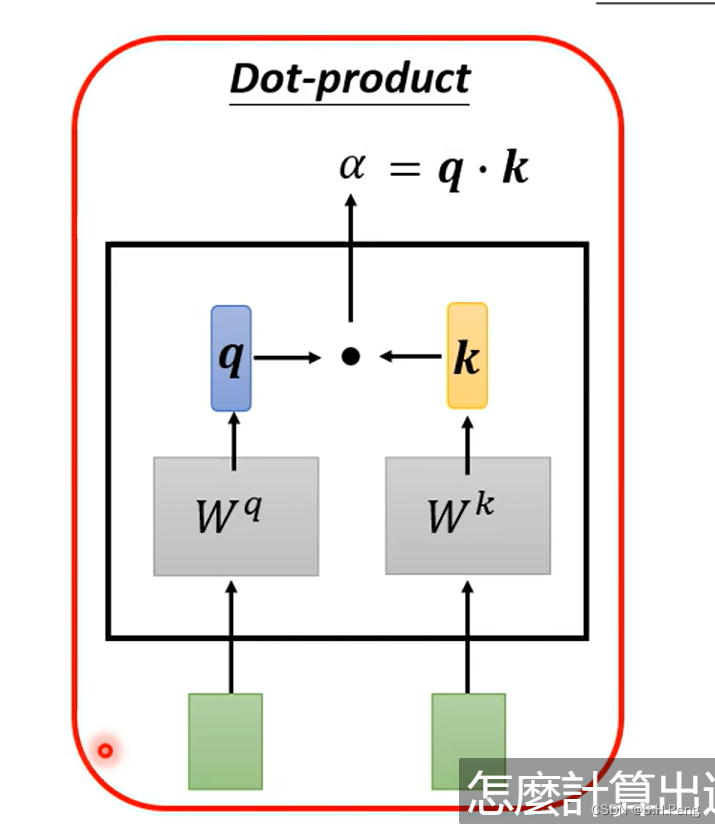
如上图,是一种计算的方法之一,这里我们引入两个可学习的参数矩阵Wq和Wk,经过Wq计算后得到的q相当于是一把钥匙,经过Wk计算后得到的k相当于是一把锁,然后再经过点乘计算出钥匙和锁的适配度也就是当前信息与其他信息的关联程度。

如上图分别计算出当前信息与其他信息的关联程度。

如上图再将算出的关联向量做softmax得到概率密度分布。
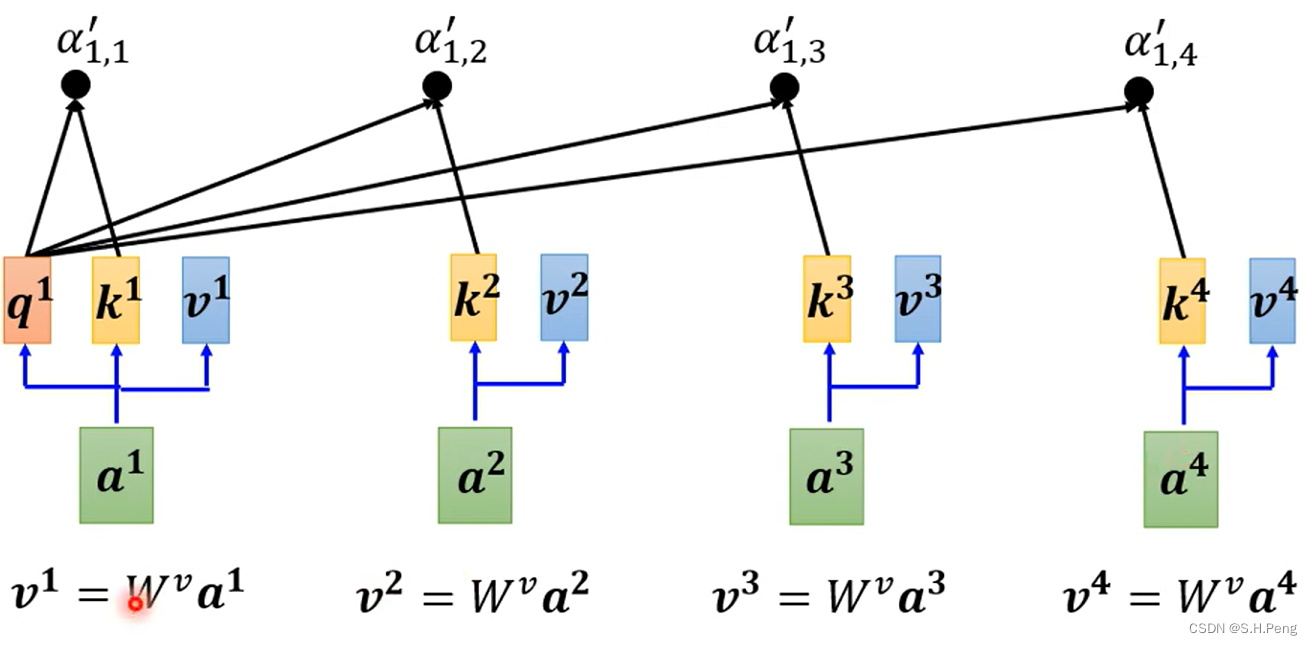
如上图,得到关联程度的概率密度分布后,我们再引入一个参数矩阵Wv来提取重要的信息
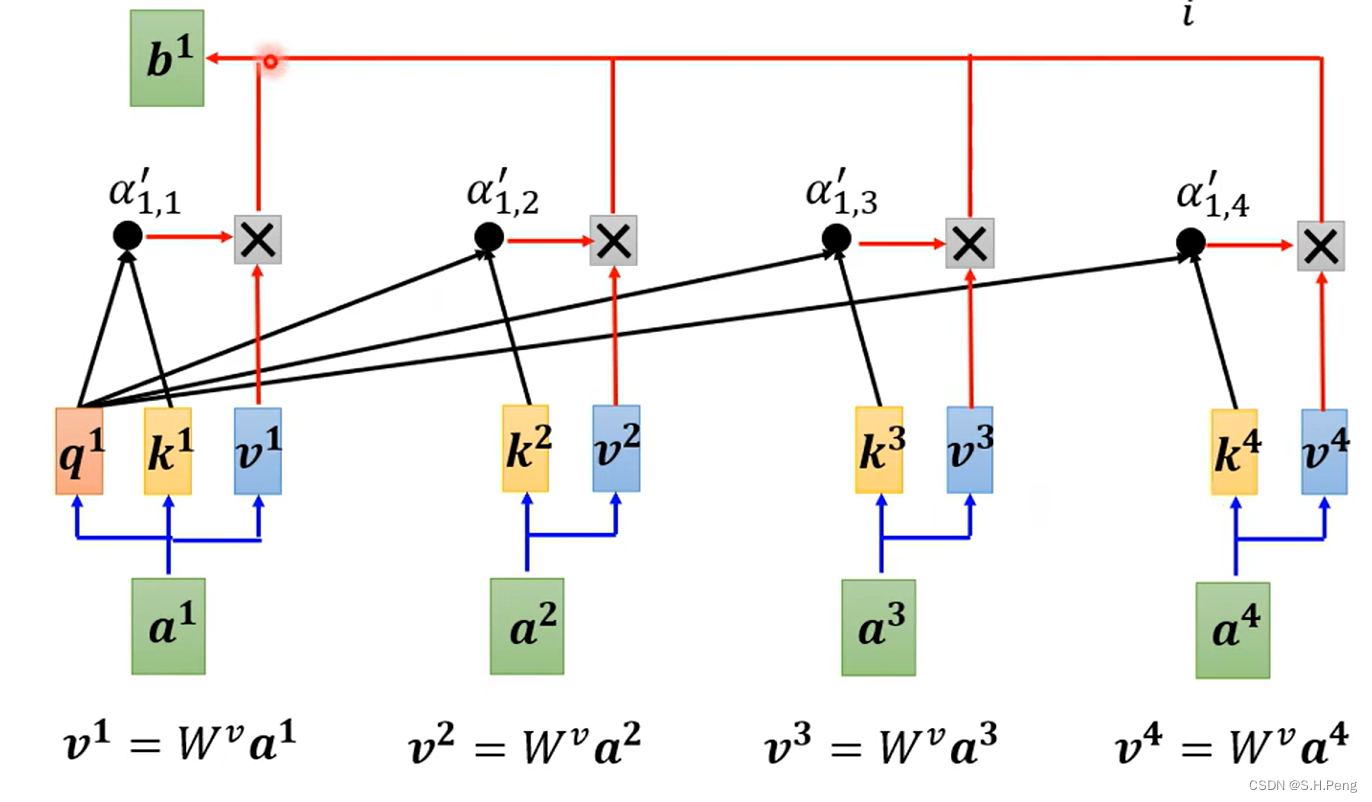
再将计算出的关联程度与提取的信息分别相乘,然后再相加,这样就得到了当前向量对应的输出。(相乘就是把与当前输入关联程度大的信息保留,关联不大的舍去)
注:在这一整个操作中,我们要更新的参数就是Wq,Wk,Wv。
Multi-Head sdlf-attention(多头注意力机制)
普通的注意力机制是指将输入序列中的每个位置作为查询(query),并根据查询与其他位置的关联性(通过计算查询与键(key)之间的相似度)来加权求和其他位置的值(value)。这种方式可以捕捉输入序列内部的依赖关系,但对于长序列或大规模的任务可能存在计算上的困难。
多头注意力机制是对普通注意力机制的扩展,通过同时使用多个独立的注意力头来处理输入序列。每个注意力头都学习自己的查询、键和值的线性变换,然后进行独立的注意力计算。最后,多个注意力头的结果通过线性变换和拼接的方式组合起来得到最终的输出。多头注意力机制可以在保持计算效率的同时,提高模型的表达能力和泛化性能。
与普通注意力机制相比,多头注意力机制具有以下区别和优势:
- 并行计算:多头注意力可以并行地处理不同的注意力头,提高计算效率,特别是在GPU上的并行计算中。
- 组合性:通过线性变换和拼接多个注意力头的结果,模型可以融合多个不同角度的注意力表示,从而提供更丰富的信息。
- 表达能力:多头注意力可以捕捉不同的关注点和特征表示,提供更全面和多样化的模型表达能力。
- 鲁棒性:多头注意力可以减少单个注意力头的过拟合风险,通过多个头的共同学习和组合,提高模型的泛化性能。
综上所述,多头注意力机制通过引入多个独立的注意力头,同时进行并行计算和组合性的操作,提供了更强大的表达能力和泛化性能,适用于处理复杂的序列任务和大规模的数据。
如下是一个两头注意力机制:
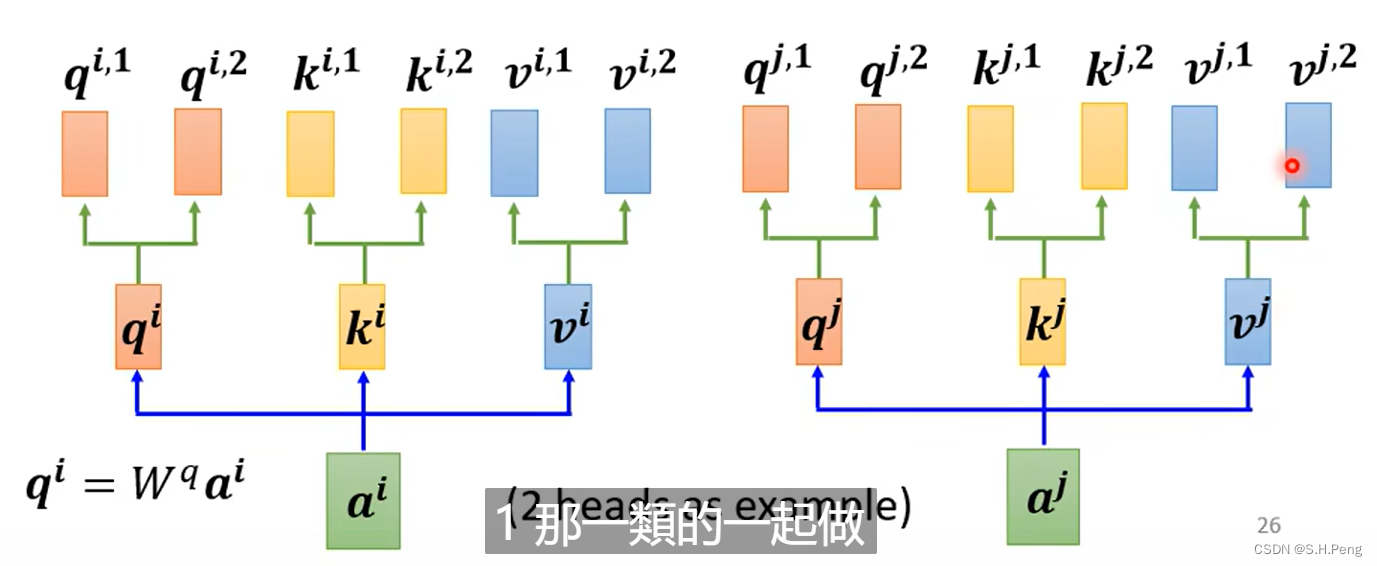
对于两头注意力机制,我们还需要再次引用多个参数矩阵。对计算出的QKV再次进行更深层次的信息提取(提取同一输入中的不同种类的信息)
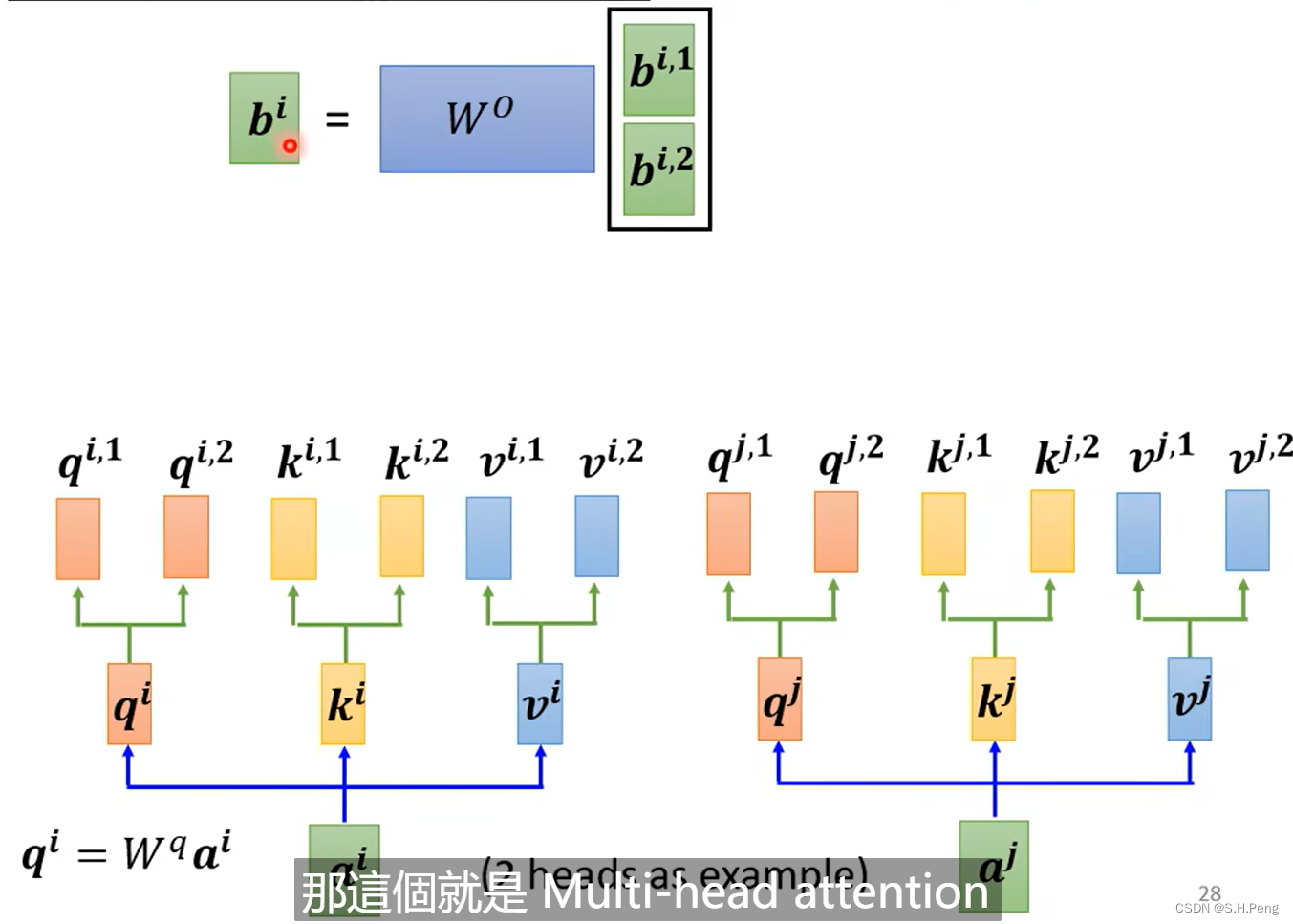
计算出当前输入的两个输出后再经过一个参数矩阵计算出当前输入的最终输出。
注:本文所用图片均来自李宏毅老师的机器学习课程















 4583
4583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









