







《2025年人工智能指数报告》(Artificial Intelligence Index Report 2025),由李飞飞联合领导的斯坦福大学以人为本人工智能研究所(Stanford HAI)发布,这已是他们发布的第8份AI Index报告。(文末附免费下载链接)

在官网上,Stanford HAI写到“AI对社会的影响从未如此明显......2025年指数是我们迄今为止最全面、也是在最重要时刻发布的报告。”
还强调:“人工智能不再只是一个关于可能性的故事,而是一个关于现在正在发生的事情,以及我们如何共同塑造人类未来的故事。”
报告指出,中国顶尖AI模型的数量和质量不断提升,中美AI模型性能近乎持平。不仅如此,中国在AI领域的论文数量和专利数量上还保持领先地位。
整个报告长达456页,深入剖析了2024年全球人工智能行业的发展态势,总结出12点。
-
1)AI基准测试表现不断提升
-
2)AI正越来越多地融入我们的生活
-
3)企业All in AI,投资和应用创新高
-
4)中美AI差距加速缩小,接近相等
-
5)负责任的AI生态系统不断发展,但不均衡
-
6)全球AI乐观情绪上升,但地域差距较大
-
7)AI变得更高效、经济和便捷
-
8)各国正加强对AI的监管和投资
-
9)AI和计算机科学教育正在扩大,但普及仍然不够
-
10)行业主导AI研究
-
11)AI斩获多个科学大奖
-
12)复杂推理仍是挑战
报告全文很长,含金量也很高,推荐大家去看看。今天,我想重点给大家介绍的,是它的1.3 Notable AI Models部分(P47-68 )。
Notable AI Models,指的是指2024年值得关注的重要模型,共55个。
其中,中国以15款重要模型排名全球第二,仅次于美国。
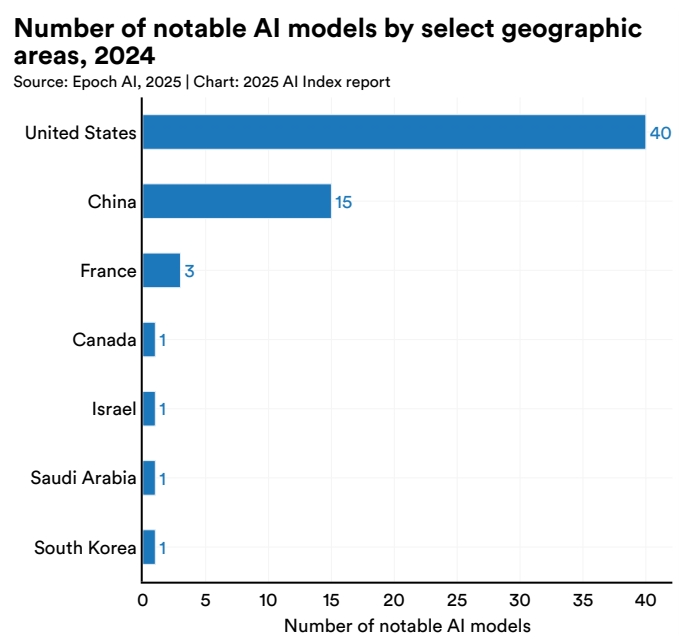
在全球重要模型公司中,中国有5家。其中,阿里AI以6个重要模型位列全球第三,仅次于Google和OpenAI,是中国AI公司中的No.1。
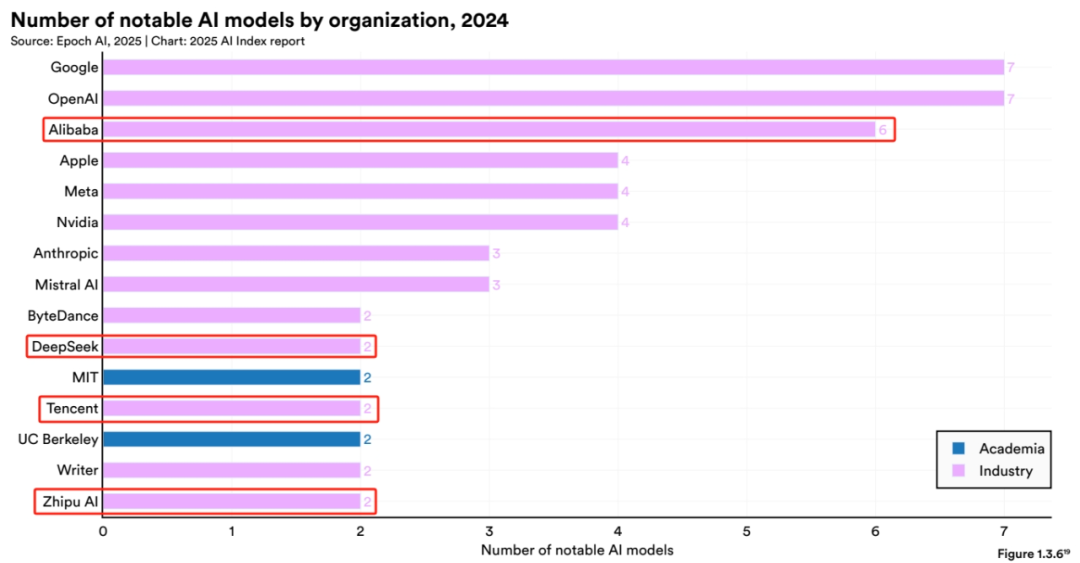
6个模型分别是:Qwen-72B、Qwen1.5-72B、Qwen2-72B、Qwen2.5-72B、Qwen2.5-32B、QwQ-32B。
因为他们,让世界AI版图多了一抹中国红。
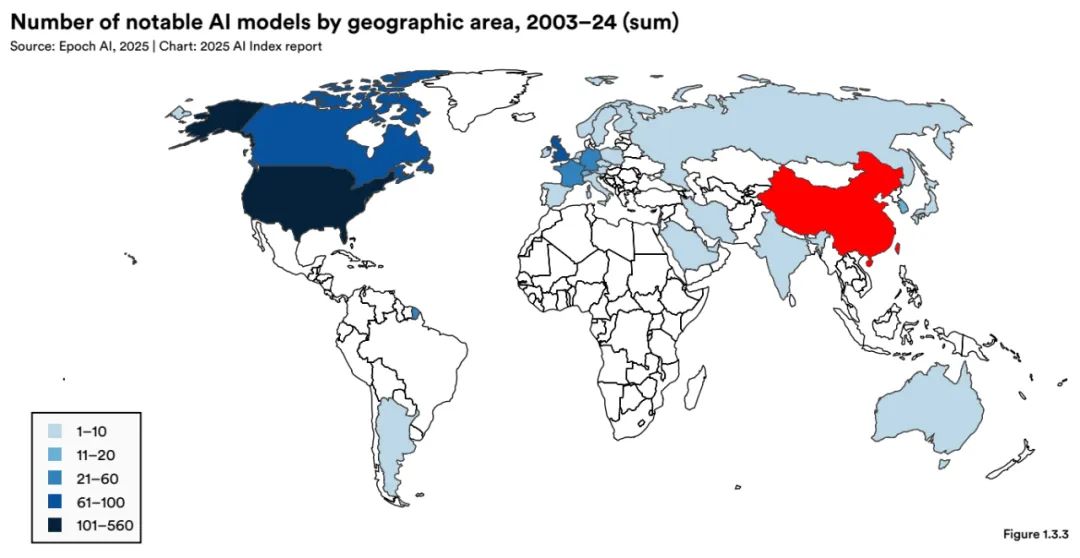
注:红色为手工添加,报告统计了自2003年以来的重要模型总和,中国在Top1级。
而至于模型定价,DeepSeek-R1:不好意思,美国没一个能打的。
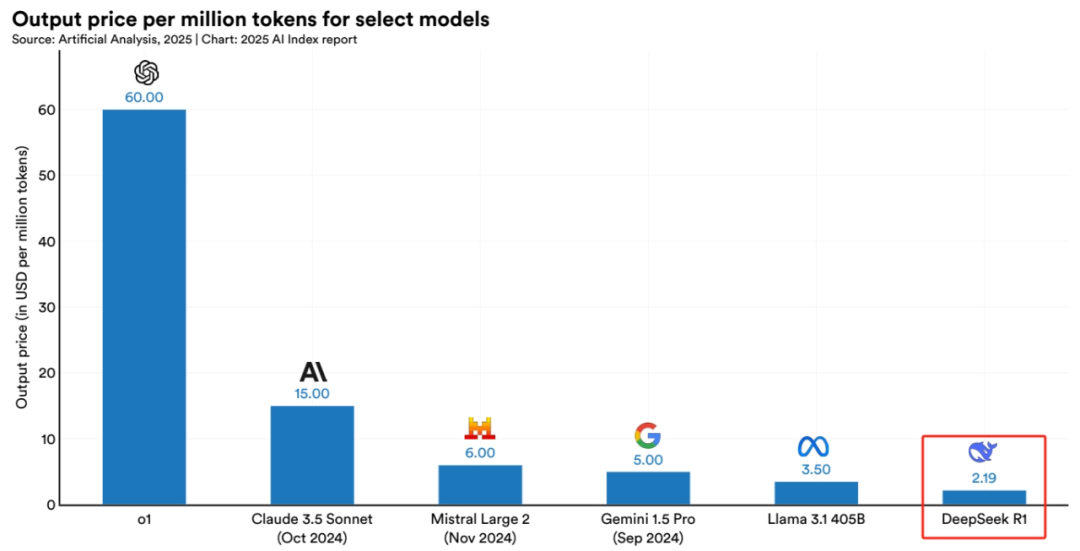
所以,你看:只有China AI在做技术平权的事情。
所有国家和地区不分政治立场,所有公司无论规模大小,所有AI爱好者不惧显卡门槛,大家都能够用得上、也用得起来自神秘东方的AI。
报告还指出,中美顶级大模型的性能差距正在急剧缩小,已缩窄至0.3%,接近抹平。要知道,2023年这一差距可是高达17.5%。

从现在起,我们可以毫不犹豫地说:
世界前五模型,我们有二:Qwen和DeepSeek。

所以,你看,我们真的不是在卷AI,而是在抗AI,扛起中国AI乃至世界AI的高度。
在过去,恐惧源于火力不足。
而现在,我们自己成了恐惧本身。
这一次,中国大模型不再是自己说强,而是世界说你强。我们有这个底气,也应该有这个自信。
以阿里Qwen举例。
1月发布Qwen2.5-Max,大幅赶超GPT-4o、Claude-3.5和Llama-3.1等一干基座模型。
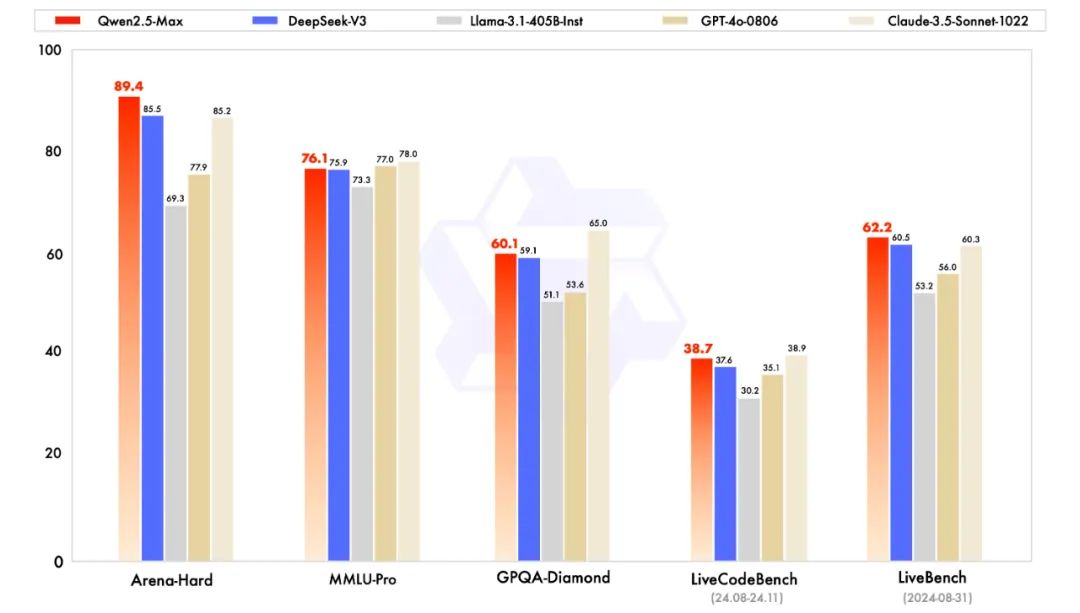
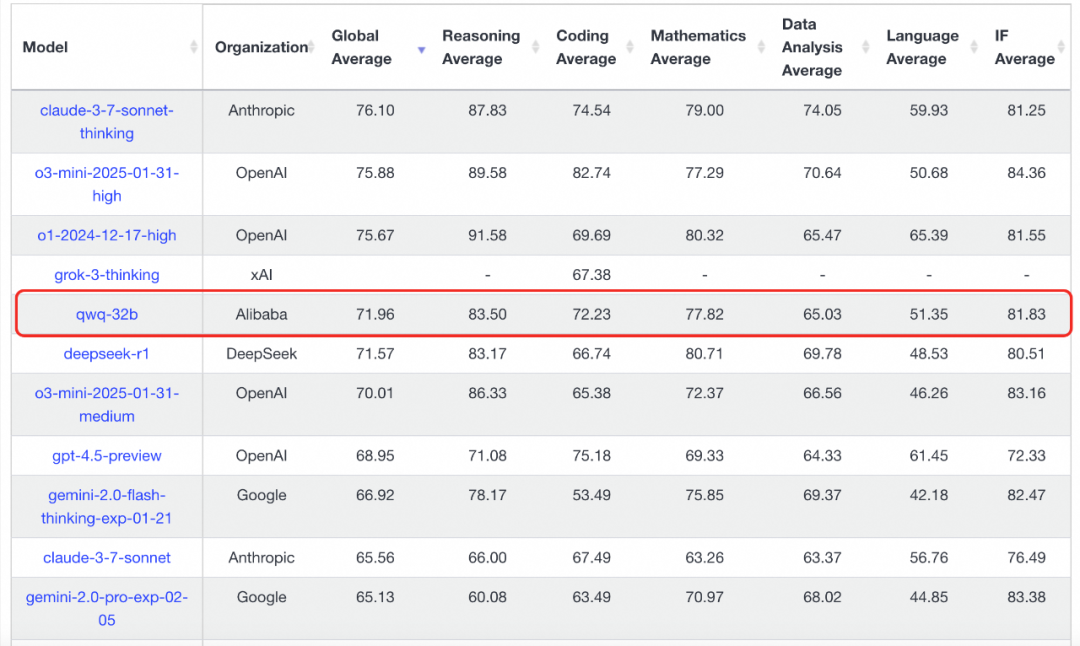
3月发布QwQ-32B,32B实现了671B R1的效果,在LiveBench榜单上刷新开源模型记录。
截至目前,Qwen的衍生模型已经突破了10w,超越Llama成为全球第一大开源模型家族。在过去2年里,阿里通义实验室累计开源了200多款模型。
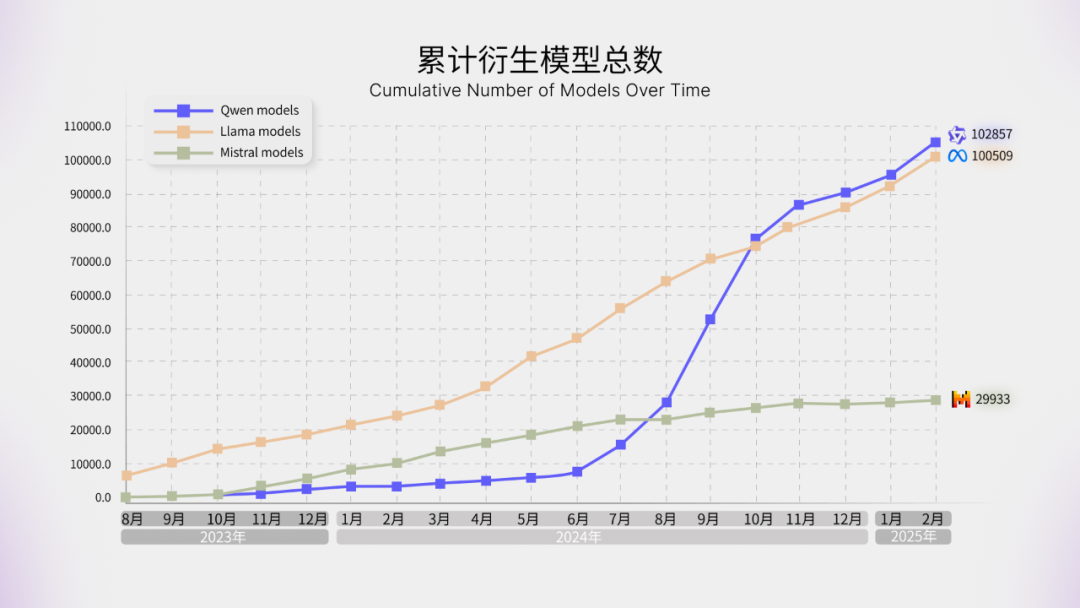
这,才是真正的“源神”吧。
面对严苛的环境与荒诞的世界,Qwen等中国模型已然站在世界的最前排。
阿里AI贡献全球第三,靠的不是PPT,不是PR,更不是demo和邀请码,而是性能、开源和模型应用的硬实力。这背后,是阿里无数研发团队花了无数时间的无数辛劳成果。
今天,China AI成为世界级的“主力选手”。面对“特不靠谱”的逆史流,有人选择跪着kiss my ass,但我们选择站着活个明白。
我用夸克网盘分享了「2025年人工智能指数报告.pdf」,点击链接即可保存。打开「夸克APP」在线查看,支持多种文档格式转换。
链接:https://pan.quark.cn/s/8bc24a9928b7


















 5094
5094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











