






目录
四:如何理解浅层隐藏层学习底层特征、深层卷积层学习高层特征?
一、深度学习的目的及直观原理理解
我们构建模型的目的其实是为了让他们学习到特征。假如我们Fisher判别函数的角度去理解。假设一个二维平面的二分类问题。
理想情况:若存在一个决定性特征(如染色体决定性别的场景),模型只需学习单一权重 U1 即可完美分类。
有时我们样本可能具有P个特征。因此我们可能需要学习到p个特征的p个权重Ui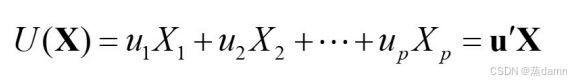
二、为什么要用深度学习:
想象一下我们人脑在识别一个物体的过程。比如我们对猫狗进行分类。我们可以从p个人类可以很好理解的特征来进行识别:比如:耳朵、鼻子、眼睛性状.......等p个具有明显区分度的特征来识别。(机器学习)
因此我们在一些场景可以根据物体特别有区分度的、肤浅的特征来进行判别。但实际上、有些物品乃至我们想要进行的非具象的物品是很难以从直观的角度进行判别的。
现实挑战:数据往往具有高维冗余性和非线性可分性。例如猫狗分类需要综合耳朵形状、瞳孔纹理、毛发分布等、及无数个隐式特征,这些特征既无法被人工显式定义,也难以通过线性组合直接分离。
深度学习中神经网络可以通过每一层学习到不同的特征。这些特征不需要我们具体去指出来到底是什么、不依赖于人的直观判断。而是通过尝试(前向传播和反向传播)来在每一层具体学习到不同特征。
假设每一层能学习到一种维度的隐式特征,我们期望通过更多的复杂变换(比如增加网络层数)来实现更多隐式特征的学习、期望通过这种方式来提高模型的预测能力。

物体检测分类:每一层学习特征可视化
三、以手写数字识别为例: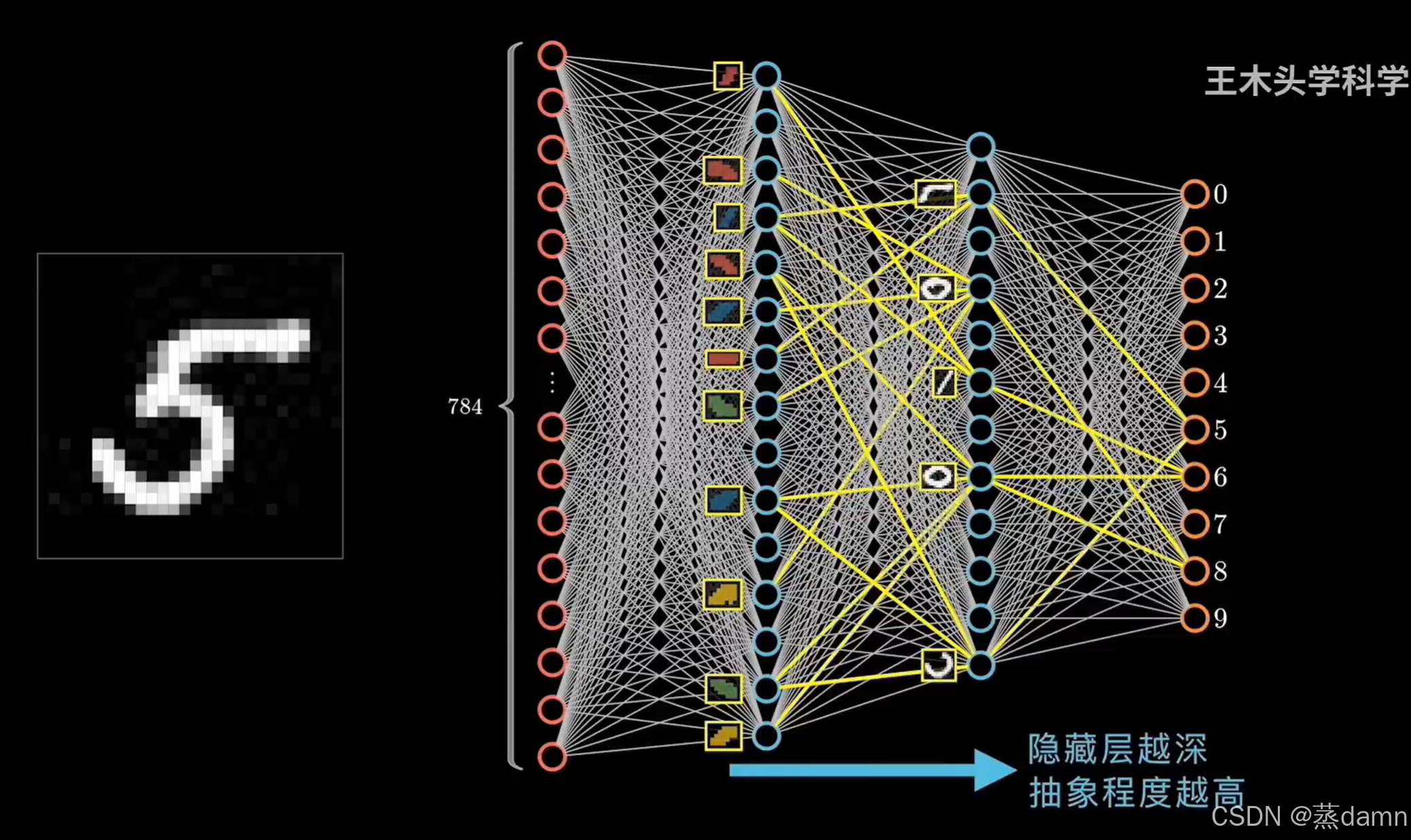
可视化来源:b站up 王木头学科学从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)_哔哩哔哩_bilibili
整体概述:
输入:图像 ——>浅层隐藏层:底层特征:比如1/4圆的性状 ——> 深层隐藏层:浅层隐藏层的组合,比如一整个圆 ——>输出:预测类别的概率 ——>预测:选取最大类别的概率:MAX{不同类别的概率} 及其对应标签。
具体而言
1. 输入:图像 → 像素矩阵
-
计算机看到的不是“数字”,而是一个由像素组成的矩阵(如 28×28=784 个像素点)。
-
每个像素的值在 0(黑)到 255(白)之间,代表灰度深浅。
-
输入层:784 个神经元,每个对应一个像素值,直接传递数据。
2. 隐藏层:从简单特征到复杂特征
-
浅层隐藏层:提取基础特征(如短边、小弯角、斜线),类似看数字的“笔画片段”。
-
深层隐藏层:组合浅层特征,识别更复杂的结构(如完整的圆、交叉线),类似拼出数字的“整体形状”。
-
权重调整:每个神经元通过权重决定前一层特征的重要性,训练时不断优化这些权重。
3. 输出层:概率与预测
-
输出层:10 个神经元,对应数字 0~9,每个输出一个概率值(如“80% 是 5,5% 是 6”)。
-
最终预测:选择概率最高的神经元对应的数字(
MAX{概率}),比如输出[0.1, 0, 0.8, ...]→ 预测为“2”。
4. 训练过程:学习与纠错
-
前向传播:输入图像,逐层计算,得到预测结果。
-
计算损失:对比预测值和真实标签,用损失函数(如交叉熵)量化误差。
-
反向传播:从输出层回溯,调整各层权重以减少误差(类似“错题订正”)。
-
重复迭代:通过大量数据反复训练,让网络越来越准。
三、工程实现:
为了方便理解 我们以卷积神经网络讲解:
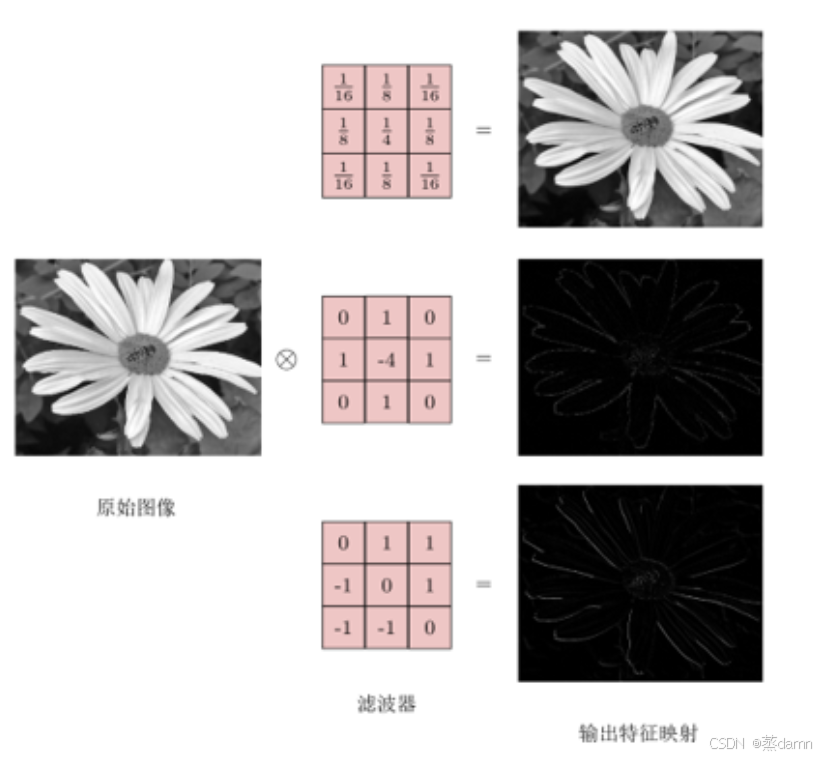
在传统数字图像处理中、我们会通过算子(卷积核)来提取图像某种特征。通过设计不同的卷积核可以实现不同的特征提取效果
-
浅层卷积核:直接操作像素,提取低层特征(边缘、纹理),类似“局部滤波器”。
-
深层卷积核:操作前一层特征图,提取高层特征(形状、结构),类似“模式组合器”。
四:如何理解浅层隐藏层学习底层特征、深层卷积层学习高层特征?
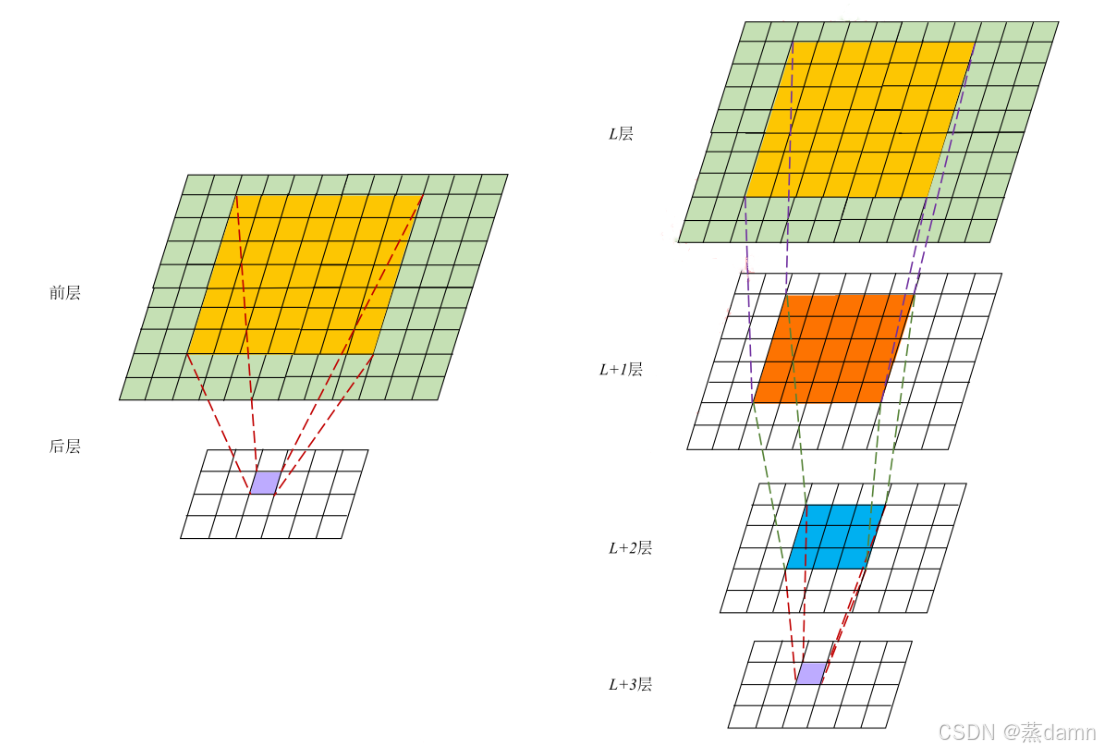
感受野:
以盲人摸象比喻
回忆一下盲人摸象的故事,所有人(卷积核)在自己的维度上智能感受到自己触及的大象的特征、因此他们无法判别到底触摸的是什么生物。但是旁观者能从看到大象的整体、因此他们指导这是大象。
也就是说所有盲人其实感受到的局部特点都是正确的、但是没能将这些特征组合到一起。
我们假设:
-
浅层卷积核(盲人):
每个盲人只能触摸到大象的局部(如耳朵、腿、尾巴),对应CNN中:-
小感受野(如3×3卷积核)只能看到图像的局部像素。
-
提取的特征是底层、局部的(如边缘、颜色块、纹理)。
-
-
深层卷积核(旁观者):
旁观者能看到所有盲人触摸的部分组合成的整体,对应CNN中:-
深层卷积核的感受野通过逐层累积变得更大(如堆叠3层3×3卷积后,感受野可达7×7)。
-
能结合浅层特征,识别高层、全局的模式(如“耳朵+长鼻+粗腿”→大象)
-
可视化直观感受
让我们来直观感受一下:我们在打开一张图片,将其放大 。每一层感受野都是3*3大小


第1层感受野 第5层感受野 第14层感受野
也就是说即便是人以肉眼识别数字也需要从高维去把握整体。但是整体的识别来自于每一个浅层特征的识别。
因此我们可以直观看到随着层数的加深、在深层网络上单个像素点可以表达浅层网络上更大范围的的信息。
总结:
因此理论上网络层数的加深可以学习到更为更为丰富的特征、再通过网络的传递、组合、复用来把握整体。因此深度学习的作用就是通过更为丰富的非线性变换得到隐式得、人类无法直接定义的特征(形状、相关性等等)。比如人脸情绪识别中、可能学习到脸部每一个局部特征并学习该特征与情绪的相关性最终来通过表情预测情绪。
但实际工程实现会遇到一系列的问题限制我们网络加深:比如梯度消失、梯度爆炸、网络退化等等。实际应用中我们通过一系列数学操作、提出模型架构来解决。经典的ResNet网络是很好的一个例子。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









