







本文大量参考雪伦大佬的博客 以及wepon大佬的ppt,在此表示感谢!
目标函数
XGBoost目标函数的定义:
由于上式包含函数作为参数,不能用欧式空间中传统的优化方法进行求解,所以XGBoost采用一种累加的方式作为训练方法,在统计学习中这种方法称为“前向分步算法”。在这种方法下,目标函数变为:
其中, y^(t)i 为第 i 个样例在第
XGBoost利用泰勒展开三项,做一个近似,我们可以很清晰地看到,最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。
泰勒展开:
目标函数展开为:
去除常数项后:
其中,
y^i=ϕ(xi)=∑tn=1fn(xi)
,
t
为树的棵数,
对于
f
的定义做一下细化,把树拆分成结构部分
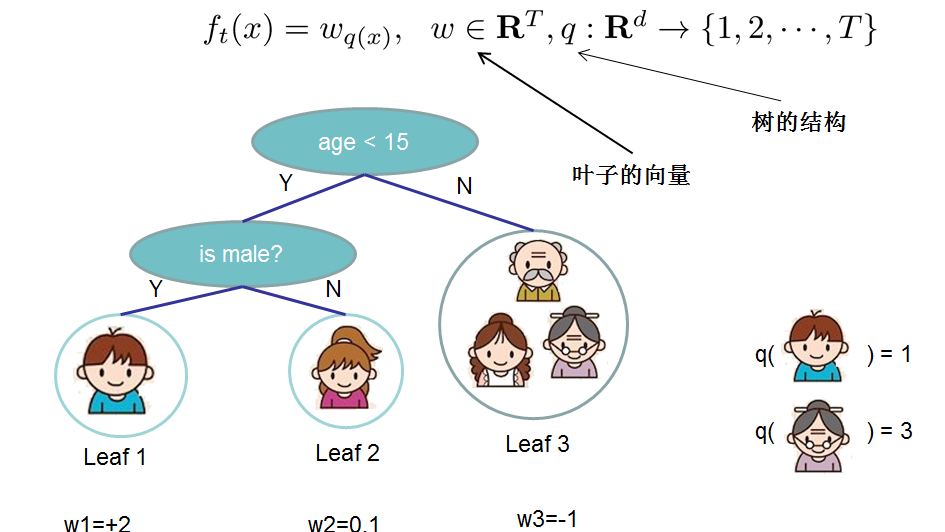
复杂度
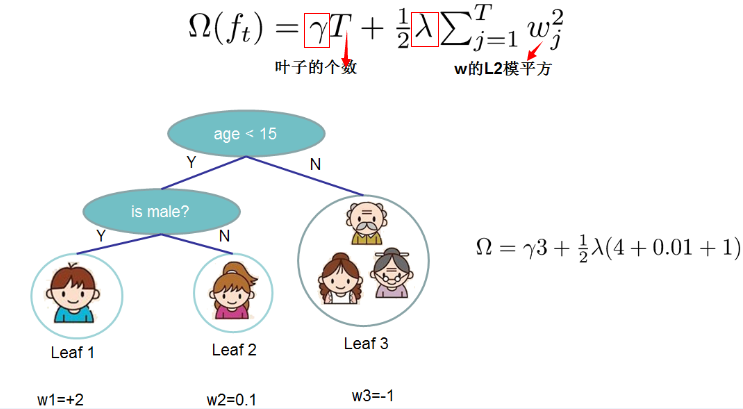
在这种新的定义下,我们可以把目标函数进行如下改写,其中
I
被定义为每个叶子上面样本集合
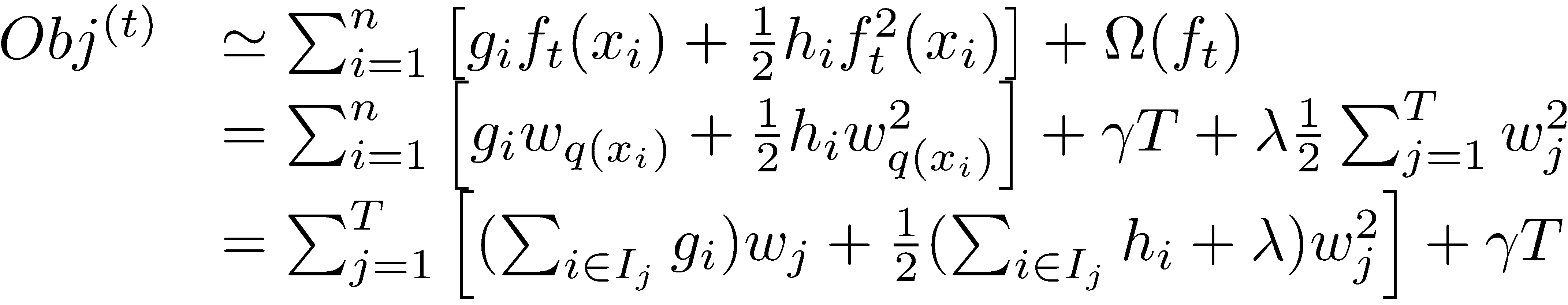
定义: Gj=∑i∈Ijgi , Hj=∑i∈Ijhi
通过对 wj 求导等于0,可以得到
带回原式可得:
这里注意, −12∑j=1TG2jHj+λ 实际上相当于各个叶结点对总体损失的贡献之和, −12G2jHj+λ 代表了第 j 个叶结点对总体损失的贡献。
- 打分函数计算示例
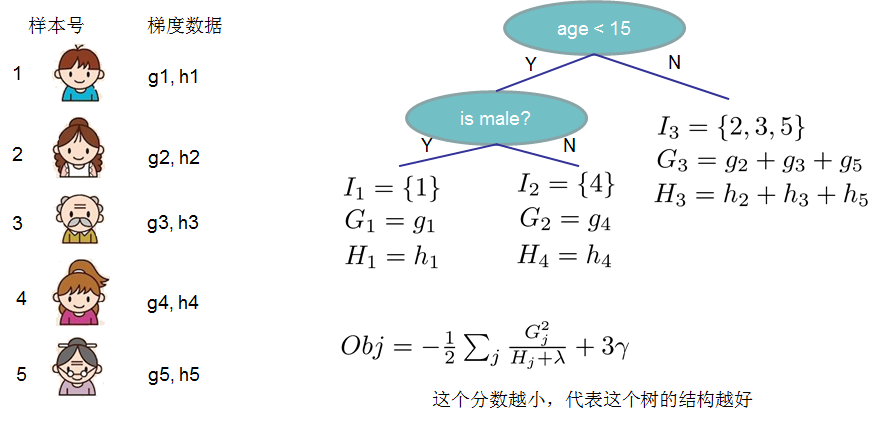
分裂节点
贪心算法
- 暴力枚举
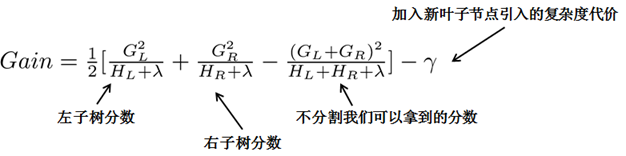
其中, GL=∑i∈ILgi , GR=∑i∈IRgi , HL=∑i∈ILhi , HR=∑i∈IRhi 。 IL 和 IR 分别是分裂后左子节点和右子节点所包含的样例集合, IL∪IR=I 。
可以看到,分裂后 Gain 的值越大,代表分裂后总体损失 Obj 减小的越多,所以当对一个叶节点分割时,计算所有候选 (feature,value) 对应的 Gain ,选取 Gain 最大的进行分割。
观察这个目标函数,第二个值得注意的事情就是引入分割不一定会使得情况变好,因为我们有一个引入新叶子的惩罚项(因为叶子节点的数量增加了一个)。优化这个目标对应了树的剪枝, 当引入的分割带来的增益小于一个阀值( γ )的时候,我们可以剪掉当前树上这个分割,并以该分割为基础开始构建下一棵树。
贪心法遍历所有特征的所有可能的分裂方式,计算复杂度大。为了提高速度,XGBoost分别对数据的所有特征依照特征值的大小进行排序,按照排序之后的顺序对特征进行访问。下面是一个例子:
假设我们要枚举所有
x<a
这样的条件,对于某个特定的分割
a
我们要计算
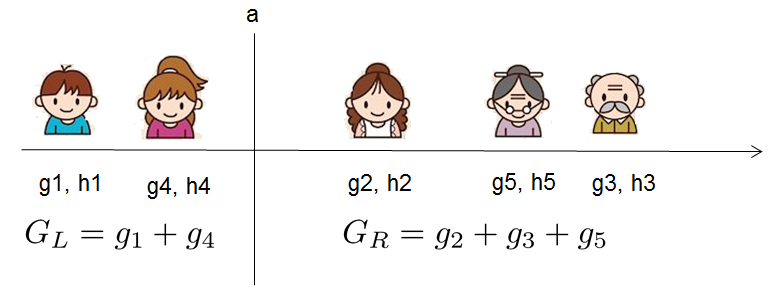
我们可以发现对于所有的
a
,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和
下面是论文中的算法:

其中,
m
为特征的数量,即数据样例的维度,
近似算法
- 对于每个特征,只考察分位点, 减少计算复杂度
- 近似算法有两种模式,Global和Local
- Global:学习每棵树前,提出候选切分点,在学习过程中切分点不变
Local:每次分裂前,重新提出候选切分点
Global模式的优点:相比于Local,需要的操作步数较少
- Global模式的缺点:由于在树的学习过程中不变,需要更多的切分点来满足不同情况下的需求
- Local模式的优点:每次分裂前,重新提出候选切分点,每一次需要的分位点数量较少且能够更好地适应较深的树
Local模式的缺点:相比于Global,需要的操作步数较多

上图是Global和Local两种模式的对比。其中
eps 是一个参数,分位数将特征分为大概 1/eps 这么多段。(个人理解)- 由图中可见,在具有相同数量的分位点时,Local模式明显优于Global模式
- 通过增加分位点数目,Global模式可以取得和Local相近的效果
- 通过调整分位点数目,Local和Global模式都可以取得和贪心算法相近的结果,且相比于贪心算法计算复杂度更低
近似方法举例:三分位数

- 实际上XGBoost不是简单地按照样本个数进行分位,而是以二阶导数值作为权重(论文中的Weighted Quantile Sketch),比如:

- 为什么用 hi 加权?对目标函数进行如下整理,可以看出 hi 有对loss加权的作用
目标函数:
L(t)=∑i=1n[gift(xi)+12hif2t(xi)]+Ω(ft)
整理后:∑i=1n12hi(ft(xi)−gi/hi)2+Ω(ft)+constant缺失值处理
缺失值产生的原因(广义):
- 数据本身存在缺失值(missing value)
- 用统计参数作为特征时,出现频率为0的现象
- 特征工程造成的伪影(如独热编码等)在XGBoost中,其在每一个节点设置一个默认的分裂方向,遇到缺失值就将其所对应的实例分到默认的分裂方向上,这个默认的分裂方向是学习出来的。


防止过拟合
- shrinkage:类似于学习率。Shrinkage scales newly added weights by a factor η after each step of tree boosting.减少了单独一棵树的影响。
- column (feature) subsampling:特征子采样。Using column sub-sampling prevents over-fitting even more so than the traditional row sub-sampling.提升计算速度。
数据格式
前面提到,为了提高速度,XGBoost分别对数据的所有特征依照特征值的大小进行排序,按照排序之后的顺序对特征进行访问。为了减少排序所需的时间,XGBoost提出了一种名为block的数据存储结构,将数据存储在内存单元,并对每一种特征进行排序。block中的数据以CSC格式存储(关于CSC见这里),目的是为了压缩矩阵,减少矩阵存储所占用的空间。block的构建仅需要在训练之前进行一次,并在之后的迭代中可以重复使用。
对于基于贪心算法的分裂方法,XGBoost将整个数据集存储为一个block,其过程如下图所示:

对于基于近似算法的分裂方法,XGBoost将整个数据集存储为多个block,不同的block可以在多机间进行部署,最终的结果通过累加不同机器上的结果所构成的直方图得到(map-reduce思想),其过程如下图所示:

时间复杂度分析
设 d 为树的最大深度,
K 为树的总数目。对于基于贪心算法的分裂方式,采用原始算法的时间复杂度为 O(Kd||X||0logn) ,其中 ||X||0 代表不存在数据缺失现象的训练数据的数量。
可以这样理解,普通决策树的时间复杂度为 O(dnlogn) ,而XGBoost可以处理存在缺失值的情况并且共有
$K$棵树,所以时间复杂度为 O(Kd||X||0logn) 。而基于block的算法的时间复杂度为 O(Kd||X||0+||X||0logn) 。可以这样理解,由于只需要进行一次排序,且之后的操作都是线性的时间复杂度,所以总体时间复杂度为 O(Kd||X||0+||X||0logn) 。
对于基于近似算法的分裂方式,采用原始算法的时间复杂度为 O(Kd||X||0logq) 。其中 q 为数据集被分位数切分的份数。
而基于block的算法的时间复杂度为
O(Kd||X||0+||X||0logB) 。其中 B 为每一个block中数据行数的最大值(这里不太懂)。Cache-aware Access
上述的优化导致每个样本的梯度信息在内存中不连续,直接累加有可能会导致cache-miss(什么是catch-miss),所以对于基于贪心算法的分裂方法,XGBoost先将样本的统计信息取到线程的内部buffer,然后再进行小批量的累加;而对于基于近似算法的分裂方法,XGBoost通过选择适当的block size来解决小样本量带来的资源浪费以及大样本量带来的cache-miss之间的权衡问题。XGBoost选择的block size为
216 。Out-of-core Computation
什么是Out-of-core Computation
维基百科上面的解释是:
Out-of-core or external memory algorithms are algorithms that are designed to process data that is too large to fit into a computer’s main memory at one time. Such algorithms must be optimized to efficiently fetch and access data stored in slow bulk memory (auxiliary memory) such as hard drives or tape drives.
简而言之就是针对数据量过大无法全部读入内存的情况,优化在读取存储在硬盘上的数据的一系列算法。
Blocks for Out-of-core Computation
XGBoost中的Out-of-core Computation是基于block的,在一定程度上解决了在硬盘上读取数据耗时过长,吞吐量不足的问题,主要有两种技术:
Block Compression
这种方法利用压缩算法将硬盘中的数据进行压缩,在读取数据进内存的过程中利用一个独立的线程对数据进行解压缩。将disk reading cost转换为解压缩所消耗的计算资源。
Block Sharding
这种方法将数据部署在多块硬盘上,为每一块硬盘分配一个pre-fetcher线程,将数据fetche到一个in-memory buffer中。训练线程直接在每一个buffer中读取数据,相当于提升了硬盘总体的吞吐量。
参考文献
(1)XGBoost: Reliable Large-scale Tree Boosting System
(2)XGBoost: A Scalable Tree Boosting System
(3)雪伦大佬的博客
(4)wepon大佬的ppt
















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









