






源文件
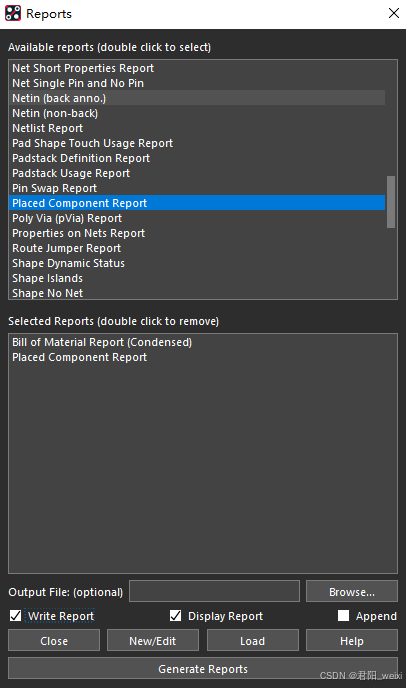

程序
import pandas as pd
import os
current_file_path = os.path.abspath(__file__)
current_dir = os.path.dirname(current_file_path)
os.chdir(current_dir)
file_bom = "cbm_rep.rpt"
file_coor = "pcp_rep.rpt"
# 检查文件是否存在
if not os.path.exists(file_bom):
print("文件不存在,请检查路径是否正确!")
exit()
if not os.path.exists(file_coor):
print("文件不存在,请检查路径是否正确!")
exit()
# 读取 .rpt 文件内容,跳过前四行
with open(file_bom, 'r', encoding='utf-8') as file:
lines = file.readlines()[4:] # 跳过前四行
# 提取表格内容
table_data = []
for line in lines:
# 使用逗号作为分隔符
if line.strip(): # 跳过空行
row = line.strip().split(',') # 按逗号分割
table_data.append(row)
# 将表格数据转换为 DataFrame
df = pd.DataFrame(table_data)
# 删除 B 列、D 列和 E 列(列索引从 0 开始)
df = df.drop(columns=[1, 3, 4, 5]) # B 列是索引 1,D 列是索引 3,E 列是索引 4, F 5
# 修改第一行的前三个单元格
df.columns = ['Designator', 'FootPrint', 'Comment'] # 只修改前三列
# 合并第一列中部分行是上一行继续的情况
rows_to_drop = [] # 用于记录需要删除的行索引
for i in range(1, len(df)):
# 判断当前行是否只有第一列有数据(其他列为空)
if pd.isna(df.iloc[i, 1]) and pd.isna(df.iloc[i, 2]): # 只检查第二列和第三列是否为空
# 将当前行的第一列数据追加到前一行的第一列数据中
df.iloc[i - 1, 0] += " " + str(df.iloc[i, 0])
rows_to_drop.append(i) # 记录需要删除的行索引
# 删除被合并的行
df = df.drop(rows_to_drop).reset_index(drop=True)
# 调整列顺序:Comment 为第一列,Designator 为第二列,FootPrint 为第三列
df = df[['Comment', 'Designator', 'FootPrint']]
# 保存为 .xlsx 文件
output_file_path = os.path.splitext(file_bom)[0] + '.xlsx' # 将后缀改为 .xlsx
df.to_excel(output_file_path, index=False)
print("表格内容已提取并保存为:", output_file_path)
# 读取 .rpt 文件内容,跳过前四行
with open(file_coor, 'r', encoding='utf-8') as file:
lines = file.readlines()[4:] # 跳过前四行
# 提取表格内容
table_data = []
for line in lines:
# 使用逗号作为分隔符
if line.strip(): # 跳过空行
row = line.strip().split(',') # 按逗号分割
table_data.append(row)
# 将表格数据转换为 DataFrame
df = pd.DataFrame(table_data)
# 修改列名
df.columns = [ # 假设原始列名为 A, B, C, D, E, F, G, H, I
'Designator', # A 列
'B', # B 列(将被删除)
'C', # C 列(将被删除)
'D', # D 列(将被删除)
'E', # E 列(将被删除)
'Mid X', # F 列
'Mid Y', # G 列
'Rotation', # H 列
'Layer' # I 列
]
# 修改 Layer 列的值:NO -> T, YES -> B
df['Layer'] = df['Layer'].replace({'NO': 'T', 'YES': 'B'})
# 只保留需要的列
df = df[['Designator', 'Mid X', 'Mid Y', 'Layer', 'Rotation']]
# 保存修改后的 Excel 文件
output_file_path = os.path.splitext(file_coor)[0] + '.xlsx' # 将后缀改为 .xlsx
df.to_excel(output_file_path, index=False)
print("表格内容已提取并保存为:", output_file_path)
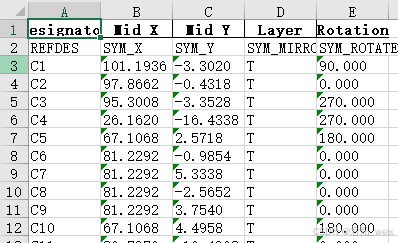
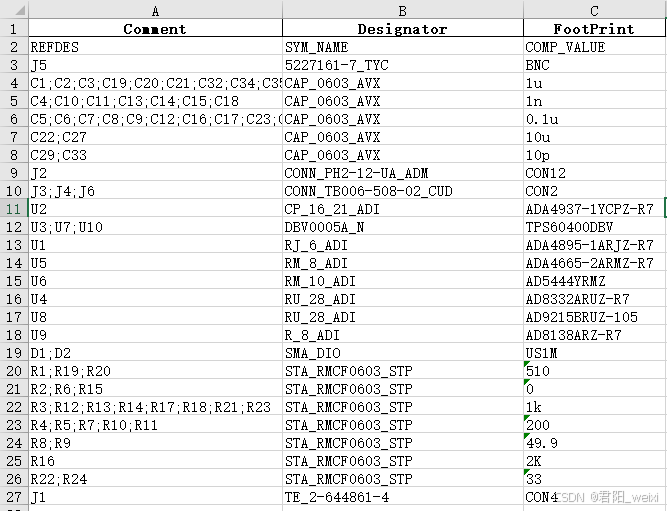
效果


















 3230
3230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









