







内容来自Andrew老师课程Machine Learning的第十一章Application: Photo OCR。
最后一章内容,主要是OCR的实例,很多都是和经验或者实际应用有关,这里记录的就只有一个知识点,善始善终,继续加油!!
一、图像识别(店名识别)的步骤:
Image --> Text detection --> Character segmentation --> Character recognition
二、人工合成数据集(这里主要指字母识别中的数据集)的两种方法:
1、没有已有样本:通常有很多字体库,我们可以采集同一个字符的不同种类字体,然后将这些字符加上不同的随机背景。
2、少量已有样本:使用已有的样本,选取一个真实的样本,然后添加将此样本扭曲、旋转(人工变形)的数据,以此来扩大数据集。
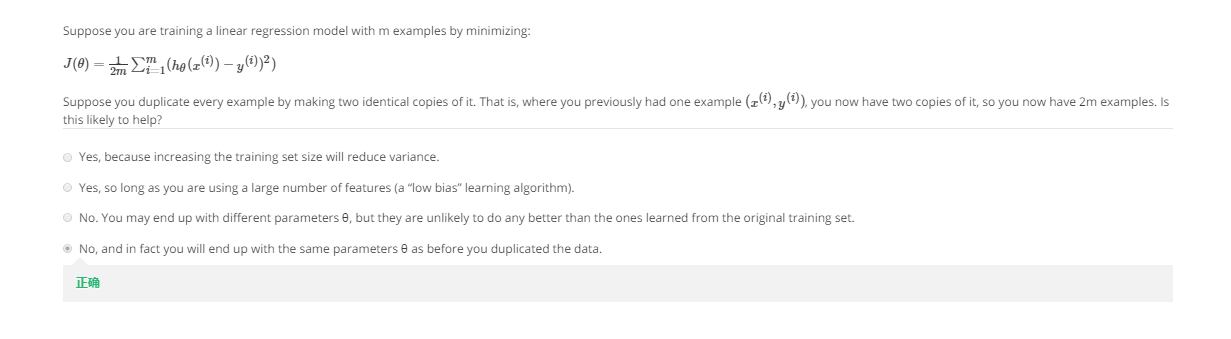
下面是一个题目:
三、在决定扩大数据集之前需要考虑的问题:
1、需要先有一个低偏差的分类器,如果没有,可以通过增大特征数或者在神经网络中增大隐藏层单元数来解决
2、首先估计增加样本需要的工作量
四、上限分析
即通过人工干预,使某一个component的准确率人工达到100%,再使用这些数据训练,如果这一component的变化导致整体系统的系统变得很好,那么说明这个component值得花时间优化。反之,我们将某一component达到100%,系统性能仍没有提升很多,则说明这一component不值得我们花费精力改进。















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









