







前言
目前网上的一些博客讲解的太笼统了,没有讲解原理,让人一头雾气。梯度下降法其实还是比较简单的下降法,因为还有其他下降法,这些都是在数值分析课程中讲解的,悔恨啊,数值分析上过两次课,还是没听懂,现在才知道原来在机器学习中这么常用,本文从多个角度来讲解梯度下降法,帮助大家理解
简单的一元函数
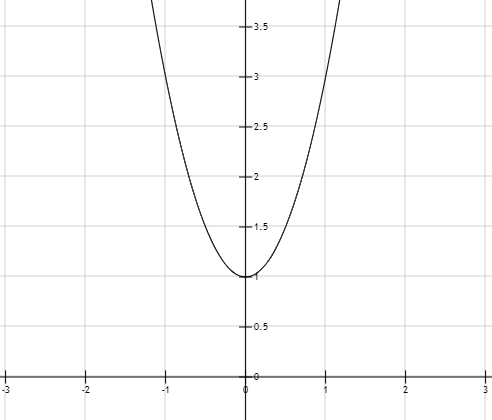
所有的问题都是从简单到复杂,一步一步来解决复杂问题的,我们首先看下一元函数的情况,这个一元函数是专门为了讲解知识而构造的一个,没有其他含义,我们假设有一个函数 y = 2 x 2 + 2 y=2x^2+2 y=2x2+2,求解这个函数的最小值,如何求解?首先看下这个图像
第一种方式:求极值
求极值使我们通用的方式,极值点可能是最小值点,所以,我们可以通过求解该函数的所有极值点,比较极值点的 y y y来得到最小值点,于是求解过程如下:
- 先求导数: y ′ = 4 x y^{'}= 4x y′=4x
- 令导数等于0,及 y ′ = 4 x = 0 y^{'}= 4x=0 y′=4x=0 得出 x = 0 x=0 x=0
- 第二步中我们得到了极值点, x = 0 x=0 x=0就一个极小值点,所以这个点是一个最小值点
这样做可以直接求出最小值,也就自然可以知道对应 x x x,我们可以看下另一个角度下的问题。
另一个角度
如果导数=0求解比较复杂,也就是难以直接求解出
x
x
x,我们采取另一种方式,对于一元函数来讲,对于某个坐标点的导数是确定的,比如上述导数
y
′
=
4
x
y^{'}= 4x
y′=4x,在x=1这个点,导数就等于4,而且导数是有方向性的:
y
=
{
越
小
y‘<0,x越大
越
大
y‘>0,x越大
y = \begin{cases} 越小 & \text{y`<0,x越大}\\ 越大& \text{y`>0,x越大} \end{cases}
y={越小越大y‘<0,x越大y‘>0,x越大
利用这个性质,我们可以来改变x的值,使它不停的向极值点靠近,我们希望它向极小值点靠近,这样就可以使y有一个极小值,如何操作:
- 1、设定一个初始化的x的值和步长 α \alpha α
- 2、求得导数 y ′ y^{'} y′
- 3、更新x, x = x − α y ′ ( x ) x=x-\alpha y^{'}(x) x=x−αy′(x) ,y^{’}(x)表示导数在x处的具体值,
- 4、用更新后的 x x x来计算 y y y值,
- 5、比较y跟之前的y值大小关系,如果更新后的 y y y更小,重复3、4、5步骤,否则停止。
经过上述步骤后,我们最终可以得到一个极小值,但极小值不一定是最小值。严谨一点的算法步骤总结如下:
- 1、设定一个初始化的 x 1 x_1 x1、 y 1 y_1 y1、步长 α \alpha α、判断条件 θ \theta θ
- 2、更新 x x x, x i + 1 = x i − α y ′ ( x i ) x_{i+1}=x_i-\alpha y^{'}(x_i) xi+1=xi−αy′(xi) ,y^{’}(x_i)表示导数在 x i x_i xi处的具体值,初始时 i = 1 i=1 i=1
- 3、用更新后的 x i + 1 x_{i+1} xi+1来计算 y i + 1 y_{i+1} yi+1值
- 4、比较 y i + 1 y_{i+1} yi+1跟之前的 y i y_{i} yi值大小关系,如果更新后的 y y y更小,重复3、4、5步骤,否则停止
{
y
i
−
y
i
>
θ
重复步骤2、3、4
y
i
−
y
i
<
=
θ
终止
\begin{cases} y_{i}-y_i>\theta & \text{重复步骤2、3、4}\\ \\ y_{i}-y_i<=\theta & \text{终止} \end{cases}
⎩⎪⎨⎪⎧yi−yi>θyi−yi<=θ重复步骤2、3、4终止
因为有可能
x
x
x收敛到一定的地步后,y也取到了最小值,有时候并不追求过分的最小值,所以我们可以通过
θ
\theta
θ来控制,只要与上一次的y值比较,他们之间的差小于
θ
\theta
θ,就说明已经很接近最小值了,收敛已经非常慢了,一般
θ
\theta
θ 也是非常小的。步长
α
\alpha
α也是一个用来控制收敛速度的参数,这个一般是
α
=
0.01
\alpha=0.01
α=0.01,也是非常小的,大一些也没有问题,收敛速度会非常快,但是很大的时候没有什么好的作用,反而不会收敛,待会会讲到这个问题。
泰勒公式角度
首先要明确一个概念,就是所有的函数都可以被泰勒展开式代替,所以:
f
(
x
)
=
f
(
x
0
)
+
f
′
(
x
0
)
1
!
(
x
−
x
0
)
+
f
′
′
(
x
0
)
2
!
(
x
−
x
0
)
2
+
f
′
′
′
(
x
0
)
3
!
(
x
−
x
0
)
3
+
.
.
.
f(x)=f(x_0)+\frac{f^{'}(x_0)}{1!}(x-x_0)+\frac{f^{''}(x_0)}{2!}(x-x_0)^2+\frac{f^{'''}(x_0)}{3!}(x-x_0)^3+...
f(x)=f(x0)+1!f′(x0)(x−x0)+2!f′′(x0)(x−x0)2+3!f′′′(x0)(x−x0)3+...
你一直计算到n阶,这个泰勒公式的精确度越高,我们这里取一阶,也就是:
f
(
x
)
=
f
(
x
0
)
+
f
′
(
x
0
)
1
!
(
x
−
x
0
)
=
f
(
x
0
)
+
f
′
(
x
0
)
(
x
−
x
0
)
f(x)=f(x_0)+\frac{f^{'}(x_0)}{1!}(x-x_0) = f(x_0)+f^{'}(x_0)(x-x_0)
f(x)=f(x0)+1!f′(x0)(x−x0)=f(x0)+f′(x0)(x−x0)
我们的目标是希望迭代过程中函数值会逐渐减小,通过不断的更新
x
i
x_i
xi值,使得
f
(
x
i
)
f(x_i)
f(xi)越来越小,最终收敛到一个范围内。所以假设:
Δ
x
=
x
−
x
0
=
−
f
′
(
x
0
)
f
(
x
)
=
f
(
x
0
)
−
f
′
(
x
0
)
2
\Delta{x} =x-x_0 =-f^{'}(x_0) \\ f(x)=f(x_0)-f^{'}(x_0)^2
Δx=x−x0=−f′(x0)f(x)=f(x0)−f′(x0)2
这样
f
(
x
)
f(x)
f(x)就不断的变小,所以
x
−
x
0
=
−
f
′
(
x
0
)
x
=
x
0
+
−
f
′
(
x
0
)
x-x_0 =-f^{'}(x_0) \\ x=x_0+-f^{'}(x_0)
x−x0=−f′(x0)x=x0+−f′(x0)
所以可以通过不断的更新
x
x
x值来得到最终符合条件的
f
(
x
)
f(x)
f(x)。算法步骤类似于上一节的内容,这里就不赘述了.















 8363
8363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









