







前言
学习地址
- http://discussion.coggle.club/t/topic/222
内容介绍
本月竞赛学习将以对话意图识别展开,意图识别是指分析用户的核心需求,错误的识别几乎可以确定找不到能满足用户需求的内容,导致产生非常差的用户体验。在对话过程中要准确理解对方所想表达的意思,这是具有很大挑战性的任务。在本次学习中我们将学习:
- 自然语言处理基础
- 文本分类路线:正则表达式、TFIDF、FastText、BERT、T5、Prompt、GPT
- 大模型分类路线:提示词、思维链、高效微调
意图识别
Intent Recognition 是指通过自然语言文本来自动识别出用户的意图或目的的意向技术任务。
- 在人机交互、语音识别、自然语言处理等领域中,意图识别扮演着至关重要的角色。
- 意图识别有很多用途,例如在搜索引擎中分析用户的核心搜索需求,在对话系统中了解用户想要什么业务或者闲聊,在身份识别中判断用户的身份信息等等。
- 意图识别可以提高用户体验的服务质量。
任务1 数据读取与分析
- 需要使用的包
import pandas as pd
from wordcloud import WordCloud # 词云
import matplotlib.pyplot as plt
import jieba # 结巴
步骤1 下载意图识别数据集
- 该数据集是一个多分类任务,目标是根据用户的输入文本判断用户的意图
- 分为两个csv文件,即
train.csv和test.csv
步骤2 使用 Pandas 库读取数据集
- Pandas 是一个用于数据分析和处理的 Python库,可以方便地读取、操作和保存各种格式的数据文件。使用 Pandas 的
read_csv函数可以读取csv格式的数据文件,并返回一个DataFrame对象。
data_dir = ' '
train_data = pd.read_csv(data_dir + '/train.csv', sep='\t', header=None)
test_data = pd.read_csv(data_dir + '/test.csv', sep='\t', header=None)
步骤3 统计训练集和测试集的类别分布、文本长度等基本信息,以了解数据集的特征和维度
- 使用
DataFrame对象的value_counts函数可以统计每个类别出现的次数和比例,使用apply函数和len函数可以统计每个文本的长度。
步骤4
1. 数据集的文本长度一致吗?
- 不一致
2. 数据集中的文本是长文本还是短文本?根据统计结果,查看每个文本的长度分布情况,如文本长度的中位数。
-
可以看到文本统计中,所有字符 12100 个,文本长度最少4个,最多54个,平均15个,应该属于是短文本、
-
文本类别统计

任务2 正则关键词与文本分类
正则表达式 regular expressions 是一种用于字符串搜索和操作的强大工具。
它使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
- 步骤如下:
- 定义规则:根据分类需求,定义一组正则表达式规则;
- 预处理文本: 对输入文本进行清洗,如去除标点符号、转换为小写等;
- 模式匹配:使用正则表达式在文本中搜索定义的模式;
- 分类决策:根据匹配结果,将文本分配到相应的类别;
- 使用正则表达式进行文本分类时,确定关键词是一个关键步骤,因为它直接影响到分类的准确性和效率。
任务3 TFIDF 提取与文本分类
-
TFIDF(词频-逆文档频率)是一种常见的文本表示方法,可以用于文本分类任务。
-
TFIDF 将文本表示为词项的权重向量,其中每个词项的权重由其在文本中出现的频率和在整个语料库中出现的频率共同决定。
-
TFIDF 可以反映出词项在文本中的重要程度,越是常见的词项权重越低,越是稀有的词项权重越高。
-
需要使用到的包
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import LinearSVC
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
import pandas as pd
import jieba
步骤1:使用sklearn中的TfidfVectorizer类提取训练集和测试集的特征
# 实例化tfidfVectorizer类
tfidf = TfidfVectorizer(
# 使用结巴分词
tokenizer=jieba.lcut,
# 使用百度停用词库
stop_words = list(cn_stopwords)
)
# 计算训练集和测试集的tfidf矩阵
train_tfidf = tfidf.fit_transform(train_data[0])
test_tfidf = tfidf.transform(test_data[0])
# 查看训练集和测试集的tfidf矩阵
print(train_tfidf.shape, test_tfidf)
print("=======================================")
print(test_tfidf.shape, test_tfidf)

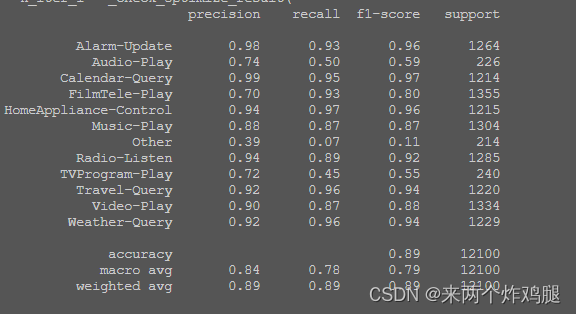
步骤2:使用KNN/LR/SVM等分类器对训练集进行训练,并对验证集和测试集进行预测,评估模型的性能。
- Logistic Regression
# 使用逻辑回归进行交叉验证预测
cv_pred = cross_val_predict(
LogisticRegression(),
train_tfidf,
train_data[1]
)
# classification_report生成分类报告
# 将train_data[1]作为真实值,cv_pred作为预测值,
# 可以得到准确率、召回率、F1值等评估指标
print(classification_report(train_data[1], cv_pred))
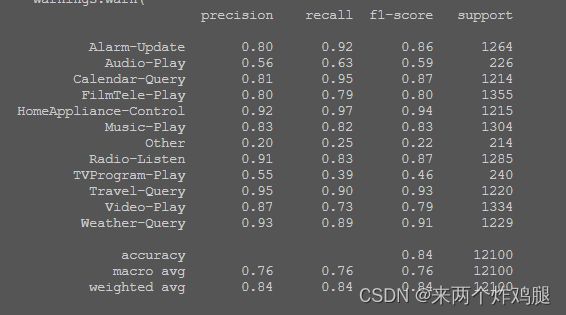
- K-Nearest Neighbors
# 使用KNN进行交叉验证预测
cv_pred = cross_val_predict(
# 使用KNN
KNeighborsClassifier(),
train_tfidf,
train_data[1]
)
print(classification_report(train_data[1], cv_pred))
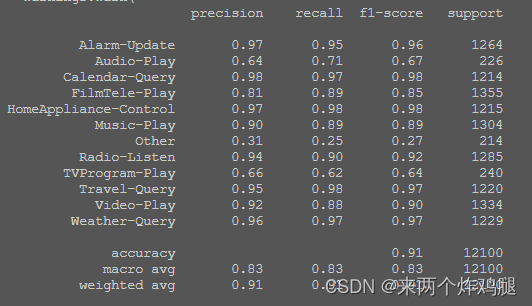
- Support Vector Machine - 线性支持向量机
# 使用线性支持向量机进行交叉验证预测
# model = LinearSVC()
# model.fit(train_tfidf, train_data[1])
cv_pred = cross_val_predict(
LinearSVC(),
train_tfidf,
train_data[1]
)
print(classification_report(train_data[1], cv_pred))
步骤3:通过上述步骤,请回答下面问题
TFIDF中可以设置哪些参数,如何影响到提取的特征?
- TfidfVectorizer类中可以设置以下参数:
- max_df: 用于过滤掉高频词项,在[0.0, 1.0]之间表示比例;
- min_df: 用于过滤掉低频词项,在[0.0, 1.0]之间表示比例;
- max_features: 用于限制提取特征的数量,默认为None。
- ngram_range: 用于指定提取n元语法特征时n值范围,默认为(1, 1),即只提取单个词项。
- stop_words: 用于指定停用词列表,默认为None。
- norm: 用于指定归一化方法,默认为’l2’范数。
- use_idf: 是否使用逆文档频率计算权重,默认为True。
- smooth_idf: 是否平滑逆文档频率计算,默认为True
KNN/LR/SVM的精度对比:根据实验结果,比较三种分类器在验证集和测试集上预测正确率、召回率、F1值等指标,并分析各自优缺点。
任务4 词向量训练与使用
词向量是一种将单词转化为向量表示的技术。
通过将单词映射到一个低维向量空间中,词向量可以在一定程度上铺捉到单词的语义信息和关联关系。
步骤1:使用结巴对文本进行分词
- 结巴是一个基于Python的中文分词工具,并支持自定义字典和停用词。
# 使用结巴分词
train_data[0] = train_data[0].apply(jieba.lcut)
test_data[0] = test_data[0].apply(jieba.lcut)
步骤2:使用gensim训练词向量,也可以考虑加载已有的预训练词向量。
- gensim是一个基于Python的自然语言处理库,可以方便地训练或加载词向量,并进行相似度计算、最近邻查询等操作。
# 使用 gensim的word2vec模型
model = Word2Vec(
sentences=list(train_data[0].values[:]) + list(test_data[0].values[:])
vector_size=50, # 词向量维度
#sg=0, # 训练算法,0表示CBOW 默认,1表示skip-gram
window=5, # 一句话中当前和预测单词之间的最大距离
min_count=1, # 词频最小值,低于它的词频将被丢弃
workers=4 # 并行训练
)
步骤3:使用词向量对单词进行编码,然后计算句子向量(可以直接求词向量均值)。
- 将每个单词替换为其对应的词向量后,得到一个由多个向量组成的矩阵。为了简化计算和降低维度,可以对矩阵按行求均值,得到一个代表句子含义的句子向量。
# 计算句子向量,这里直接求词向量均值
train_w2v = train_data[0].apply(lambda x: model.wv[x].mean(0))
test_w2v = test_data[0].apply(lambda x: model.wv[x].mean(0))
步骤4:使用LR、SVM和决策树对句子向量进行训练,验证和预测。
-
LR(逻辑回归)、SVM(支持向量机)和决策树都是常用的机器学习分类算法,可以使用sklearn库中提供的相关函数来实现。
-
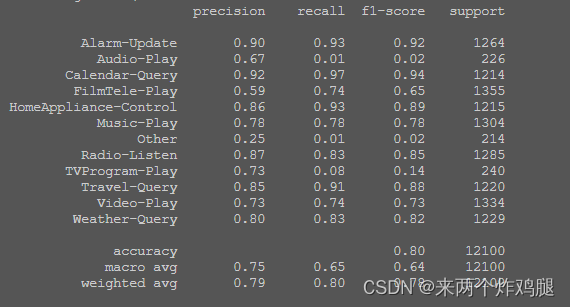
使用 LR
# 使用LR
cv_pred = cross_val_predict(
LogisticRegression(),
train_w2v,
train_data[1]
)
print(classification_report(train_data[1], cv_pred))
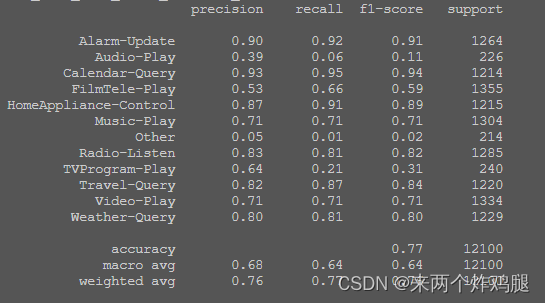
- 使用决策树
# 使用决策树
cv_pred = cross_val_predict(
DecisionTreeClassifier(),
train_w2v,
train_data[1]
)
print(classification_report(train_data[1], cv_pred))
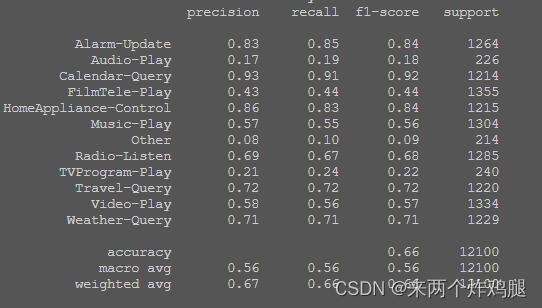
- 使用线性支持向量 LinearSVC
cv_pred = cross_val_predict(
LinearSVC(),
train_w2v,
train_data[1]
)
print(classification_report(train_data[1], cv_pred))
步骤5:通过上述步骤,请回答下面问题
词向量的维度会影响到模型精度吗?
- 一般来说,词向量的维度越高,则表示单词语义信息和关联关系的能力越强;但同时也会增加计算复杂度和过拟合风险。
- 而且词向量的维度越高,也意味着需要数据集更大,带来的训练时间的增加,需要引入优化算法
词向量编码后使用树模型和LR,谁的精度高,为什么?
- 取决于多种因素,包括数据集的特性、任务类型、模型的超参数设置以及特征工程的质量等。















 4009
4009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









