







源自:自动化学报
作者:汤健, 郭海涛, 夏恒, 王鼎, 乔俊飞
“人工智能技术与咨询” 发布
摘 要
在面向工业过程的计算机视觉研究中, 智能感知模型能否实际应用取决于其对复杂工业环境的适应能力. 由于可利用的工业图像数据集存在分布不均、多样性不足和干扰严重等问题, 如何生成符合多工况分布的期望训练集是提高感知模型性能的关键. 为解决上述问题, 以城市固废焚烧(Municipal solid wastes incineration, MSWI)过程为背景, 综述目前面向工业过程的图像生成及其应用研究, 为进行面向工业图像的感知建模提供支撑. 首先, 梳理面向工业过程的图像生成定义和流程以及其应用需求; 随后, 分析在工业领域中具有潜在应用价值的图像生成算法; 接着, 从工业过程图像生成、生成图像评估和应用等视角进行现状综述; 然后, 对下一步研究方向进行讨论与分析; 最后, 对全文进行总结并指出未来挑战.
关键词
工业过程 / 视觉感知 / 图像生成 / 生成图像评估与应用 / 城市固废焚烧
工业物联网、大数据、人工智能、云计算等新一代信息技术的发展, 使得工业过程能够在传统的控制与决策基础上融入视觉感知信息[1]. 目前, 计算机视觉模型已能够依据工业图像建立运行工况识别模型、产品质量检测模型和难测参数量化模型[2-4], 这些模型对复杂工业环境适应能力的强弱通常是决定其能否实际应用的关键[5].
基于深度学习(Deep learning, DL)的视觉感知模型已在诸多领域得到广泛应用[6-9], 其具有以下优势: 1)能够自动学习特征; 2)能够获得具有完备性和非冗余性、强于人工获取方式的特征; 3)能够学习复杂问题的非线性可分“分界面”; 4)具有通用的问题解决思路和技术框架. 复杂工业过程中的图像存在可解释性差、干扰性强、标记成本高等问题, 这导致大量数据难以有效使用[10], 使得视觉感知模型在应用中存在识别精度低、鲁棒性差等现状[11]. 以城市固废焚烧(Municipal solid wastes incineration, MSWI)过程[12]为例, 存在的问题包括[13]: 1)燃烧过程中固有的飞灰、高温等因素使得火焰图像清晰度差; 2)在炉排前端和后端进行燃烧的极端异常火焰图像稀缺; 3)物料组分的不可控性和控制参数的波动性导致火焰图像的可解释性差; 4)火焰图像难以标记. 因此, 该领域对视觉信息的处理依然依靠运行专家, 存在难以避免的主观性和随意性[14]. 可见, 因存在异常图像稀缺、图像对比度低和噪声干扰大等问题, 常用视觉模型难以适用于具有强污染、多噪声和图像类别不完备等特性的工业过程. 显然, 实际训练集的分布不符合期望全集分布已成为制约计算机视觉应用和发展的主要因素之一.
如何获取符合期望分布的训练图像集仍是一个开放性的难题. 图像生成[15]是解决该难题的方法之一. 目前, 已有的相关研究包括: 文献[16-17]阐述玻尔兹曼机研究进展, 包括亥姆霍兹机、深度玻尔兹曼机(Deep Boltzmann machines, DBM)和深度置信网络(Deep belief network, DBN)等; 文献[18]梳理传统自编码器(Auto-encoder, AE)模型及其衍生变体模型的研究现状、分析其存在的问题与挑战和展望未来的发展趋势; 文献[19-21]概述生成对抗网络(Generative adversarial networks, GAN)的基本思想、梳理相关理论与应用研究; 文献[22]根据似然函数处理方法对深度生成模型进行分类, 包括基于受限玻尔兹曼机(Restricted Boltzmann machines, RBM)、变分AE (Variational AE, VAE)的近似方法[23]、能够避免求极大似然过程的诸如GAN的隐式方法、对似然函数进行适当变形的流模型和自回归模型; 文献[24]介绍基于去噪扩散概率模型(Denoising diffusion probabilistic models, DDPMs)[25-26]、噪声条件分数网络(Noise conditioned score networks, NCSNs)[27]和随机微分方程(Stochastic differential equations, SDEs)[28] 3种通用扩散模型框架, 并讨论与其他深度生成模型的关系. 但是, 这些文献综述主要聚焦于图像生成在计算机领域的应用, 其核心问题是如何更好地拟合训练集的概率密度分布. 因工业过程具有强污染、多噪声和不确定等特性而使得图像生成更加复杂, 其核心在于: 如何结合过程机理, 借助小样本集“创造”出期望的图像集. 因此, 有必要结合工业过程的实际特性, 针对性地对工业图像生成及其应用研究进行综述.
本文面向实际需求, 对工业过程图像生成、生成图像评估与应用进行综述, 主要贡献包括: 1)梳理面向工业过程的图像生成技术和工业领域潜在图像生成技术; 2)结合图像生成领域的研究成果, 面向实际工业过程需求, 依据流程将现有算法从工业图像生成、生成图像评估和应用3个方面进行综述; 3)提出面向工业过程图像生成及其应用的未来研究方向与挑战.
1. 面向工业过程的图像生成技术
1.1 图像生成的定义与分类
图像生成的目标函数如下
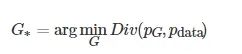
(1)
式中,
![]()
表示生成数据和真实数据的概率分布, Div(⋅) 表示散度.
由式(1)可知, 图像生成的定义为: 寻找生成模型参数, 使生成的数据与真实的数据概率分布的散度最小. 本文给出如图1所示的深度生成模型分类框架.
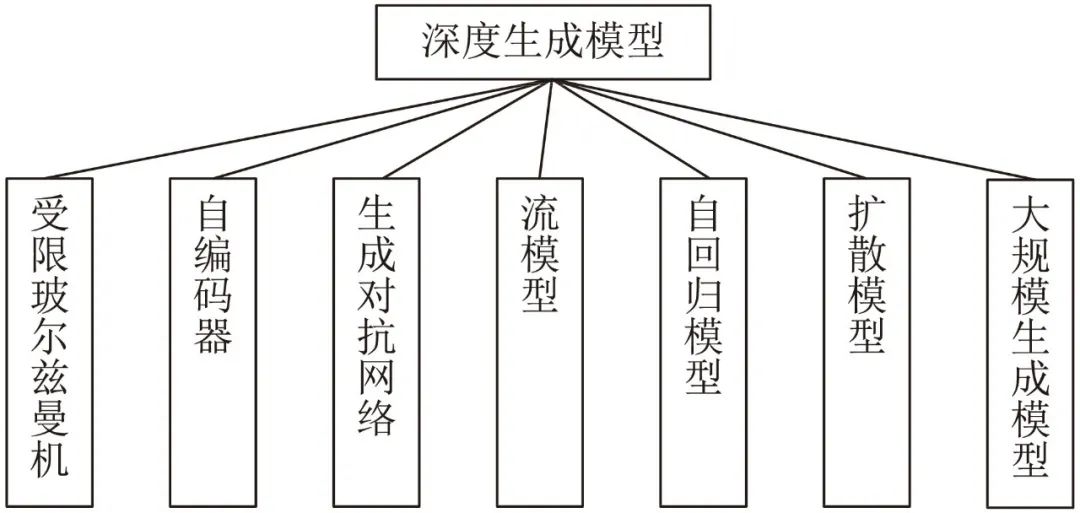
图 1 深度生成模型分类
由图1可知, 深度生成模型包括: 1)受限玻尔兹曼机[29]及以其为基础模块的深度置信网络[30]、深度玻尔兹曼机[31]等模型; 2)自编码器及其改进模型; 3)生成对抗网络[32]以及改进模型; 4)以非线性独立分布估计(Non-linear independent components estimation, NICE)为基础的常规流(Normalizing flow)模型[33]及其改进模型; 5)包括神经自回归密度估计(Neural autoregressive distribution estimation, NADE)[34]、像素循环神经网络(Pixel recurrent neural network, PixelRNN)[35]、掩码AE分布估计(Masked AE for distribution estimation, MADE)[36]以及WaveNet[37]等在内的自回归模型; 6)扩散模型以及其改进模型; 7)以ChatGPT和GPT-4为代表的大规模生成模型.
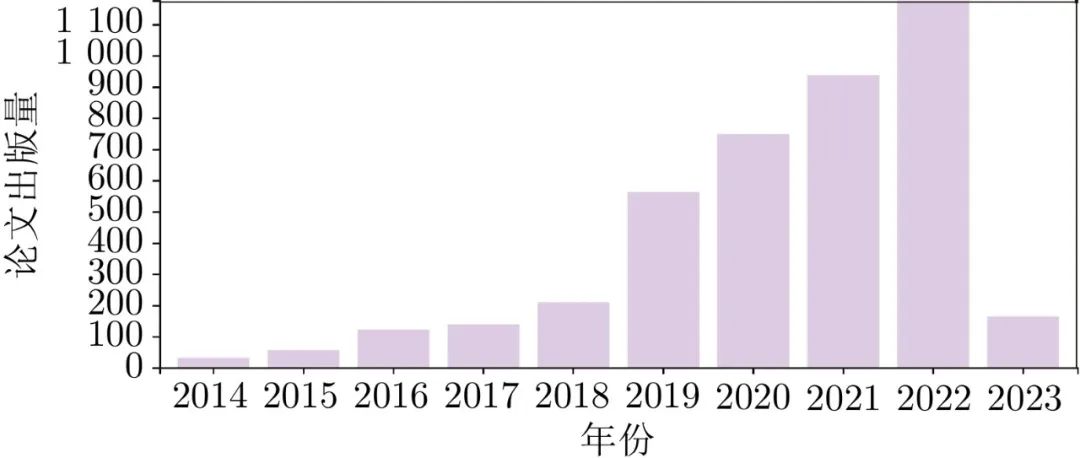
图 3 AE模型论文出版情况
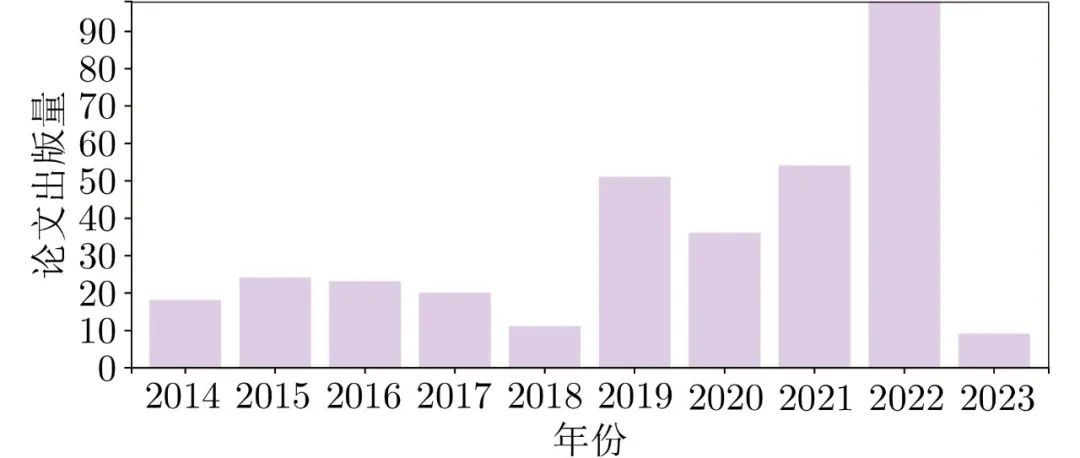
图 4 流模型论文出版情况
在上述模型中, 用于图像生成的GAN、AE、流模型和扩散模型的论文出版情况如图2 ~ 5所示.
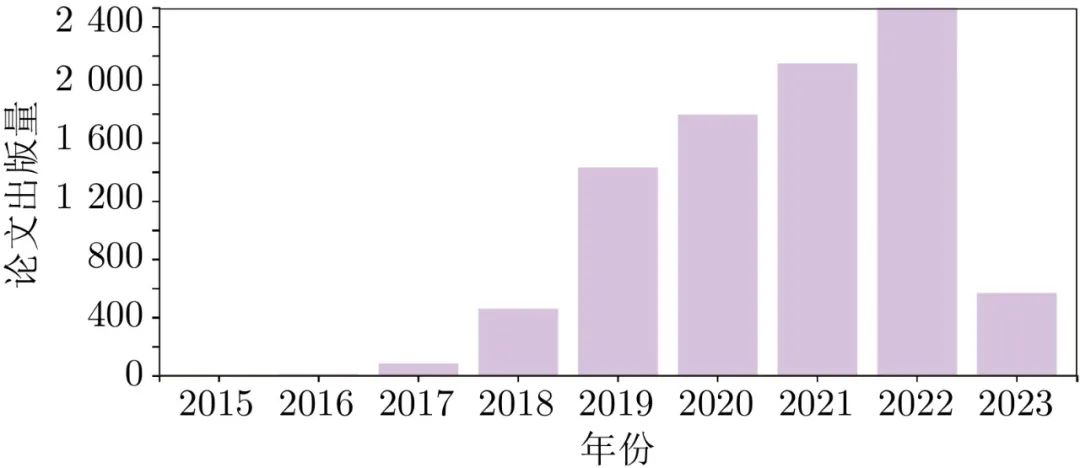
图 2 GAN模型论文出版情况
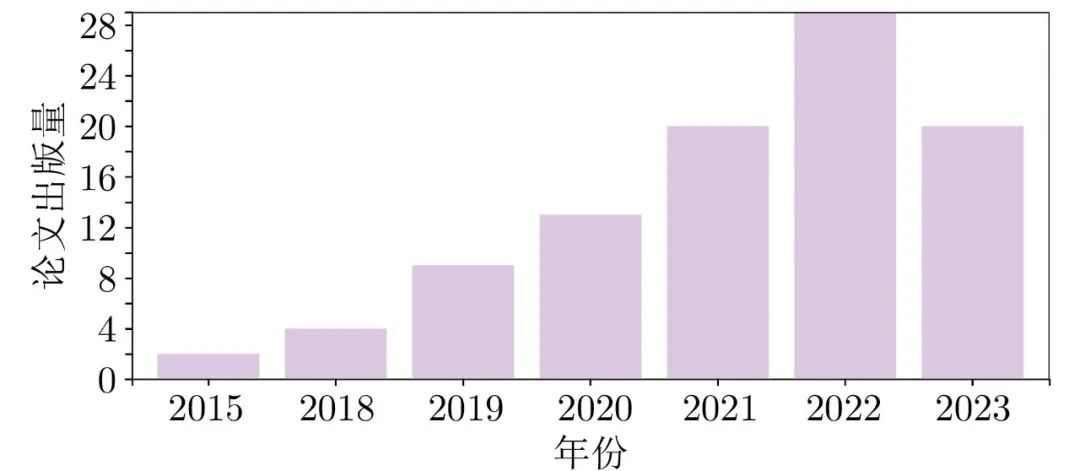
图 5 扩散模型论文出版情况
1.2 面向工业过程的图像生成定义
面向工业过程的图像生成任务可表示为
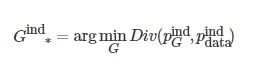
(2)
式中,
![]()
表示最优的生成模型,
![]()
表示工业过程生成数据的概率分布,
![]()
表示真实数据的概率分布.
由式(2)可知, 当训练集足够大时, 从训练集中抽样获取的
![]()
能够近似表征真实数据的分布, 其难点在于如何定义Div(⋅) 能够使模型得到有效的训练. 面向工业过程, 由于样本的稀缺, 除了存在上述问题外, 如何表征
![]()
d也是难以解决的问题, 需要针对性地采用不同的策略予以解决.
1.3 面向工业过程的图像生成及应用流程
面向复杂工业过程的图像生成及其应用流程如图6所示.

图 6 面向工业过程的图像生成及应用流程
由图6可知, 具体流程为: 首先, 构建图像数据集, 主要包括图像采集和基于专家知识的图像标定; 然后, 针对真实图像数据存在的问题, 结合工业机理构建图像生成模型; 接着, 定性或定量评估生成图像的质量和多样性并选择合格图像, 若再次进行图像生成仍不满足要求, 重新通过图像采集和图像标定构建图像数据集; 最后, 构建基于生成和真实图像的数据集以进行生成图像应用.
本文重点关注工业过程图像的生成模型构建、生成图像评估和应用等方面.
1.4 面向工业过程的生成图像评估框架
虽然生成模型, 特别是GAN, 得到了广泛的关注, 但如何对所生成的图像进行评估和选择仍然是待解决的开放性问题. 面向生成图像的评估模型架构[38]如图7所示.

图 7 对生成图像的评估架构
传统生成图像的评估框架为: 先将真实图像集和生成图像集进行特征提取, 再对所提取的特征向量进行度量计算. 该评估框架涉及多种不同的特征提取网络和度量准则. 以真实图像集Xr 、生成图像集Xg 和特征提取器为输入, 以度量准则FID (Fréchet inception distance)值为输出的评估过程为: 首先, 加载特征提取器提取两个图像集的特征矩阵zr 与zg ; 然后, 计算特征矩阵的多元正态分布均值μr 与μg 以及协方差矩阵Covr 与Covg ; 接着, 计算矩阵的迹Tr(⋅) ; 最后, 根据式(3)计算FID值
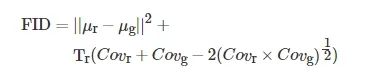
(3)
这类算法旨在度量生成数据集与真实数据集之间的相似度.
1.5 面向工业过程的图像生成应用需求
目前, 卷积神经网络(Convolutional neural network, CNN)是视觉领域的主要研究方向. 例如, 文献[39]结合CNN和图像分割定位变压器内部热缺陷的故障; 文献[40]改进CNN以预测设备部件的坐标、方向角和类别类型; 文献[41]在CNN中引入局部聚集描述符向量以增加特征表示的鲁棒性和增强识别模型的精度. 但是, 以CNN为代表的监督网络模型的准确率常取决于训练样本标签的质量与规模.
工业过程的图像采集设备长期处于强干扰环境中, 这导致图像的获取和标定存在困难[14]; 此外, 数据的不均衡分布也是工业过程中的常见问题[42-43]. 诸多研究表明, 在数据分布不平衡的情况下, 数据增强处理有助于提高模型性能[44-46]. 传统数据增强是通过几何变换(如平移、缩放和旋转)和通道变换合成图像[47], 其局限性在于无法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1658
1658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









