






源自:系统工程与电子技术
作者:覃润楠 彭晓东 谢文明 惠建江 冯渭春 姜加红
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
摘要
针对航天器试验任务过程监控的在轨故障诊断状态检测、健康状态评估与航天器寿命预测等多个环节中, 海量试验数据在传输、共享、处理、分析、存储等过程中面临的巨大压力, 构建面向航天器多源异构数据管理的分布式大数据发布/订阅系统(big-data publish/subscribe system, BPSS)框架。借助大数据与云平台技术, 设计了一套航天器海量在轨试验数据传输、管理与缓存方案, 对云节点实现主从调控与弹性扩容, 并通过基于消息一致性的动态选举算法完成大规模发布/订阅任务, 保证数据传输的安全性、一致性与计算效率, 具备大数据订阅响应迅速、多源异构数据高吞吐稳定性、分布式组件部署灵活等优点。实地航天器数管实验结果表明, BPSS数据订阅的平均响应时延为0.05 s/GB, 同时在单日吞吐量达到85 GB量级时, 数据丢帧率控制在0.025%、数据破损率控制在0.018%, 与其他开源的发布/订阅系统相比具备一定竞争力。
关键词
云平台 ; 分布式 ; 大数据 ; 航天器在轨试验 ; 发布/订阅系统
引言
航天器在轨运行过程中所处的空间环境复杂多变, 各种粒子辐射、电磁辐射、温度交变等环境效应[1]会对航天器产生干扰影响, 严重的会导致航天器故障, 造成巨大损失, 需采取有效手段准确、直观地展示航天器在轨工况, 及时发现隐患, 进行故障预警, 并在故障发生时快速定位以及实施故障预案, 从而保障航天器长期在轨稳定运行。因此, 开展航天器运行状态综合检测和监视显示技术研究有着迫切的需求[2], 且具有较高的实用价值。
聚焦航天器在轨运行状态监视离不开对航天器遥测参数、数传图像的分析, 航天器试验数据成为地面监视人员了解航天器运行状态的主要依据[3]。随着航天技术的飞速发展, 航天器种类、试验频率、测量站点日益增多, 越来越多的新型载荷得以搭载应用, 导致航天器试验数据数量急剧增加[4]。在航天器在轨状态监视过程中, 如何使用较少数量的服务器高效、可靠地接收、管理并实时统计分析海量试验数据, 从而准确表征航天器的运行情况, 是地面监视人员所关心的热点问题。
分布式云计算的出现和发展, 使得海量数据的耗时处理能够依托于计算能力有限的服务器集群, 通过软硬件资源的共享, 按需分配给计算机和其他设备[5]。Hadoop正是近年来得到广泛应用的开源云计算平台, 由核心组件分布式文件系统(hadoop distributed file system, HDFS)与大数据计算引擎MapReduce, 以及Pig、ZooKeeper、HBase、Hive等多个子项目组成[6]。面对持续增长的海量航天器试验数据, 具备通用性、高可靠性、可伸缩等特性的Hadoop的引入无疑会为分析展示航天器在轨试验过程带来便捷。
然而, Hadoop虽具有高容错性、批处理、PB量级大数据传输等优点, 但无法满足小文件的高效存储、实时的多线程并发数据读写等应用需求, 因此需考虑引入高并发的消息发布/订阅系统。发布/订阅系统的异步通讯范式能够实现大规模分布式通讯传输应用[7]: 数据发送方将消息内容发送至根据主题名称区分的逻辑信道中, 而数据接收方则自由订阅自己感兴趣的主题, 并同步接收所有被发送到这些主题信道下的消息[8], 具有多线程并发、松耦合及高可拓展的特性。当前, 主流的发布/订阅系统有基于主题的Kafka[9]、RabbitMQ[10]、RocketMQ[11]、ActiveMQ[12]等系统, 以及基于内容[13]、基于渠道[14]、基于类型[15]的发布/订阅模型系统。
关于云计算平台与发布/订阅系统的结合方面已有一部分研究工作[16-18], 文献[19]提出了一个整合Hadoop的发布/订阅中间件, 通过基于内容的匹配算法来分析订阅意图, 从而更精准地发布内容给订阅者。然而在实际应用中, 考虑到Hadoop的大规模并行计算依赖于存储在本地磁盘上的离线数据, 无法满足航天器在轨试验数据的实时在线引接与处理分析显示的应用需求, 需通过其他云节点额外进行数据的实时交互处理。然而在云计算平台中, 各云节点的性能差异会导致数据不同步的现象。目前, 已经产生了许多经典的节点选举机制实现各节点的数据同步, 例如Paxos消息一致性算法[20]、Raft优先级选举机制[21]、拜占庭故障容错(practical Byzantine fault tolerance, PBFT)[22]等。但这些算法因各自特性差异皆有不同程度的使用限制, 其中Paxos和Raft共识算法并未考虑系统中的拜占庭节点问题, 而PBFT算法的可扩展性较差等。
本文通过借鉴国内外主流的发布/订阅系统, 综合考虑当前选举同步机制的局限性, 设计了一种面向航天器多源异构试验数据传输、管理、缓存的分布式大数据发布/订阅系统(big-data publish/subscribe system, BPSS), 实现了基于消息一致性的动态选举算法从而保障大数据的传输效率与安全。同时, 在大型航天器数管实验任务中对BPSS的性能进行实验, 验证了其具备数据交互响应迅速、海量多源异构数据高吞吐稳定性等特点, 能够稳定、实时表征航天器运行状态, 便于地面监视人员进行有效的故障处置, 为航天任务保驾护航。
本文按如下结构组织: 第1节介绍当前国内外研究现状, 引出航天器在轨试验数据全生命周期管理过程中所面临的问题; 第2节提出BPSS架构, 并介绍其架构设计; 第3节提出并介绍基于消息一致性的动态选举算法; 第4节依托航天器数管实验任务进行BPSS性能验证, 根据实验数据分析实验结果; 最后给出本文的结论。
1 BPSS系统架构设计
1.1 总体架构设计
BPSS系统为5层分布式架构, 包含控制中心层、数据发布层、数据订阅层、数据处理层、数据缓存层, 总体架构如图 1所示。其中, 控制中心层对云平台的全部云节点实现主从调控, 采用基于消息一致性的动态选举算法推选主控节点, 并通过动态弹性扩容策略增加从节点资源来完成大规模发布/订阅任务。对于任意主从节点均设有以下4层架构: 数据发布层将数据推送至数据映射区, 通过水位线和检查点记录数据偏移量, 保证数据发布顺序性; 数据订阅层根据数据映射区的主题分区拉取数据, 通过订阅偏移量保证数据拉取顺序性, 同时各节点的数据映射区通过消息一致性通讯算法实现与主控节点的数据同步; 数据处理层对数据映射区进行镜像备份, 形成带索引的源数据存储块, 保证数据计算分析效率; 数据缓存层完成数据安全入库存储, 实现内存级高吞吐与强容错性。
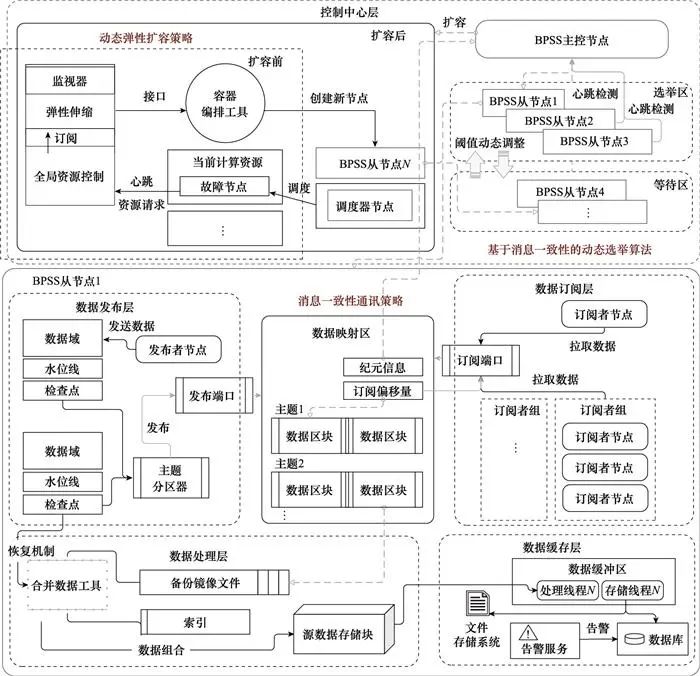
图1 BPSS总体架构设计图
1.2 控制中台架构设计
BPSS系统的控制中心层在云平台上实现控制中台架构, 包含调度器节点、主控节点、多个从节点, 如图 2所示。
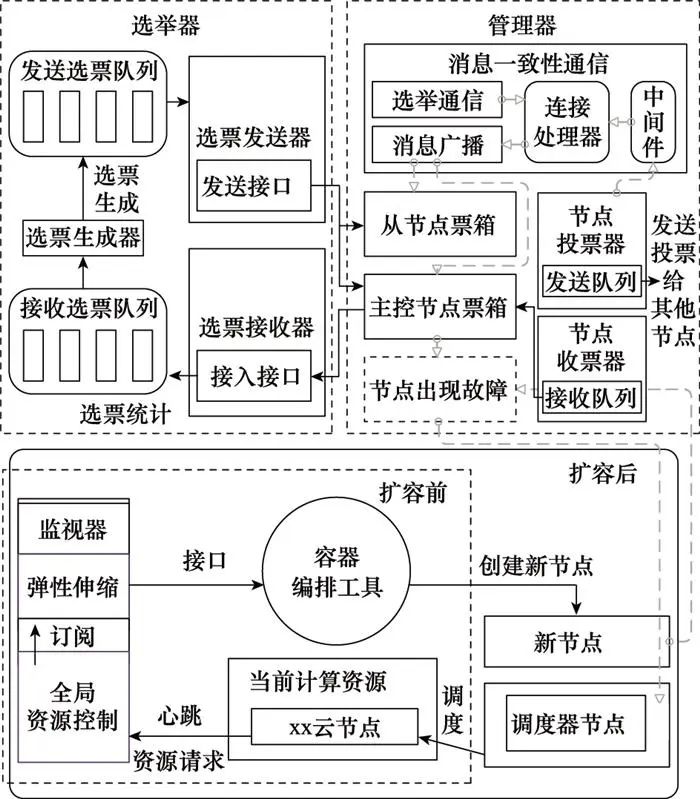
图2 控制中台架构设计图
控制中台通过基于消息一致性的动态选举算法对全部云节点实现主从调控, 在主控节点由于意外进程中断或意外死机停止工作后在选举区中发起选举。整个选举过程主要由选举器和管理器共同完成, 其中选举器负责接收选票和发送选票, 管理器负责主从节点之间的选举通信和从节点票数的传递。如某个从节点票箱中的票数达到半数以上, 则由该从节点接替主控节点工作。
对于故障节点采用动态弹性扩容策略重新赋能, 该节点要求的资源将借助心跳机制传递到全局资源控制模块, 同时监视器通过订阅心跳来监控集群状况, 随后触发纵向扩容, 弹性伸缩模块创建新的资源节点, 并保存至扩容队列。最后, 容器编排工具接收到创建新节点的指令后, 在扩容队列中读取该节点信息并新建节点, 当新节点创建完成后, 则将扩容队列中的相应节点移除。
1.3 发布/订阅架构设计
在BPSS系统的任意主从节点上均实现发布/订阅架构, 包含发布者节点、订阅者节点, 以及数据映射区, 如图 3所示。
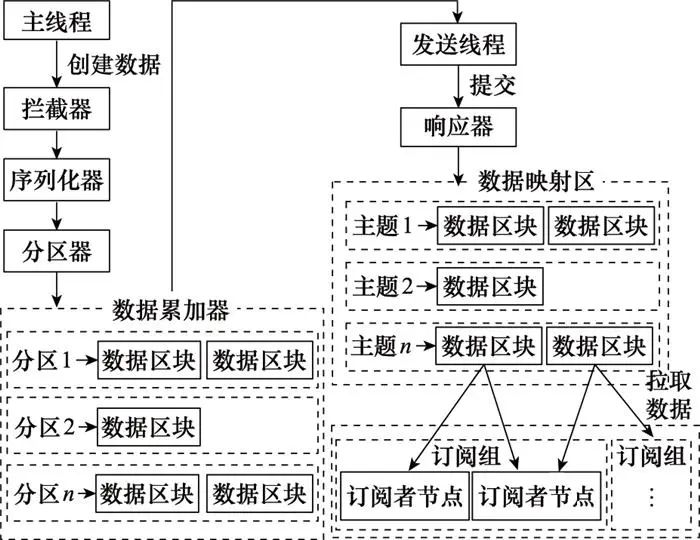
图3 发布/订阅架构设计图
发布者节点的设计由主线程和发送线程两个线程协调组成。在主线程中由用户创建数据, 之后通过拦截器、序列化器和分区器将数据缓存到数据累加器的队列尾部, 以便发送线程可以批量发送, 进而减少网络传输的资源消耗以提升性能。发送线程负责从数据累加器的双端队列头部获取消息, 并通过响应器将其发送到数据映射区。
订阅者节点能够加入订阅组, 负责根据水位线订阅数据映射区中的数据主题, 拉取数据后保存订阅偏移量, 如图 4所示。其中, 水位线用于定义数据可见性, 即用来标识哪些数据能够被订阅者节点拉取。订阅偏移量是订阅者节点拉取下一条数据的位移值, 因此介于水位线和订阅偏移量之间的数据就属于可以被拉取的数据内容。
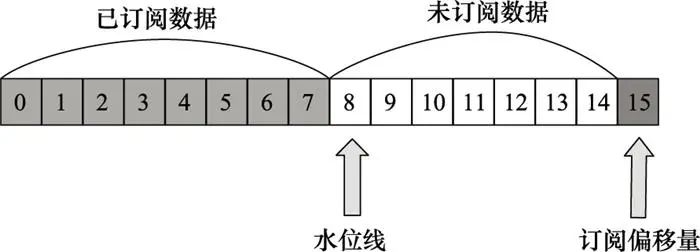
图4 订阅偏移量示意图
此外, 为保证数据映射区的数据安全与处理实时性, BPSS在数据处理层实现基于检查点的数据镜像备份, 整体设计思路如图 5所示。其中, 检查点的含义是当某次镜像备份完成后, 缓存当前的备份进度。因此, 当批量数据写入时, 遇到检查点后将重新建立新的镜像文件, 同时会在这个镜像文件文件头中添加索引, 并合并为带索引的源数据存储块, 既可以保证缓存效率, 同时也能在系统故障或服务器断电时快速恢复数据。
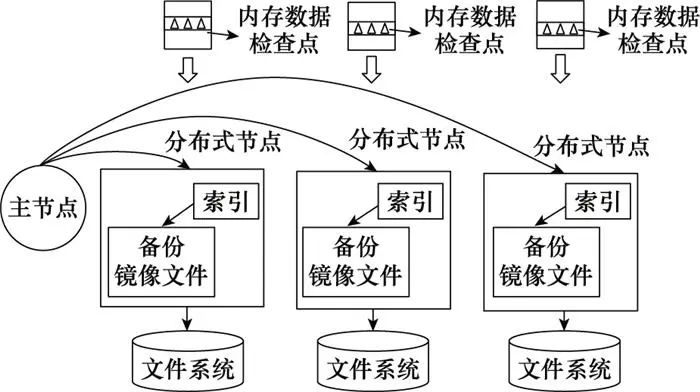
图5 数据镜像备份模式设计图
2 基于消息一致性的动态选举算法
2.1 算法总体描述
BPSS的控制中台为同步云节点之间的数据状态, 引入心跳检测机制周期性地检测各节点的工作情况。当前心跳检测协议有很多种, 例如加速心跳协议[23]、多机系统心跳检测机制[24]、自适应心跳检测[25]等, 但心跳检测协议大多都存在节点异常后的不可恢复性, 以及主控节点单点失效导致恢复延误的问题[26]。常见的解决节点异常的方法是双机容错技术[27], 在主控节点故障时用备份机对故障主控节点的工作进行平滑接管, 但降低了分布式系统的灵活性, 于是针对双机容错技术的缺陷产生了选举机制[28-30]。当某个从节点检测到主控节点故障时, 该从节点需发起一个选举过程, 并要求其他从节点全部参加, 共同选举出一个新的从节点接替主控节点工作。
然而, 在实际工程应用中发现了选举机制的诸多问题, 例如云节点越多, 选举机制的执行时间就越长, 以及有新节点频繁加入集群后可能重新引起一次选举, 导致主控节点不断变换, 系统可用性大幅降低。同时, 由于各节点间的性能差异, 数据同步程度不一致, 选举后会出现数据丢失的现象。为改进上述问题, 本文设计了一种基于消息一致性的动态选举算法, 能够对参加选举的节点数量进行动态调控, 通过动态弹性扩容策略为故障节点再次赋能, 同时基于消息一致性通讯策略同步各节点数据状态, 其伪代码如算法1所示。

由算法1可知, 基于消息一致性的动态选举算法首先将所有节点进行优先级排列, 并根据当前集群规模进行阈值设置, 阈值之上划分为选举区, 阈值之下划分为等待区。只有位于选举区的从节点才有资格参加主控节点的选举, 选举结束后参加过选举的从节点其优先级会进一步调高, 尽可能保证主控节点性能为集群中的最优节点。同时,阈值也会根据实际情况动态调整: 当选举区的从节点数量过多时将选举区内优先级最低的节点下放至等待区, 同样当等待区从节点数量过多时,将等待区内优先级最高的从节点升级至选举区。此外, 对于故障节点通过动态扩容将其替换为新创建的节点, 针对新加入集群的节点或故障恢复节点直接将其置为等待区, 降低节点加入集群时进行选举的次数。在主控节点由于意外进程中断或意外死机停止工作后在选举区中发起选举, 如某个从节点中的票数达到半数以上, 则由该从节点接替主控节点工作, 并进行各节点间消息一致性判读。
2.2 消息一致性通讯策略
基于消息一致性的动态选举算法中的消息一致性策略伪代码如算法2所示, 每个节点中需记录主控节点变更次数的纪元信息, 纪元信息初始值为0, 每当主控节点变更一次, 纪元信息值就会加1, 即增设版本号,下标m表示主控节点。同时, 每个节点中需记录消息偏移量, 用于同步当前纪元信息下写入第一条消息时的偏移坐标。从节点以固定频率向主控节点请求数据同步, 并当节点状态更替时比对各自节点消息偏移量的位置进行数据截断或补齐操作, 以此保护各节点的数据完整性。

2.3 动态弹性扩容策略
基于消息一致性的动态选举算法中的动态弹性扩容策略伪代码如算法3所示, 设置扩容队列暂存当前故障节点, 根据每一个故障节点的故障类型设定节点类型type, 如果扩容队列中包含该节点类型, 则继续迭代查找下一个故障节点, 否则将该节点类型加入至扩容队列中。通过扩容队列的设置, 降低新节点的创建时间, 同时防止为同一个故障节点创建过多新节点。

3 实验与结果
3.1 实验环境准备
BPSS在大型航天器数管实验任务中进行了实地测试, 其硬件部署图如图 6所示。采用云平台虚拟节点集群、分布式云存储设备, 以及国产操作系统与数据库搭建大容量数据交换环境。
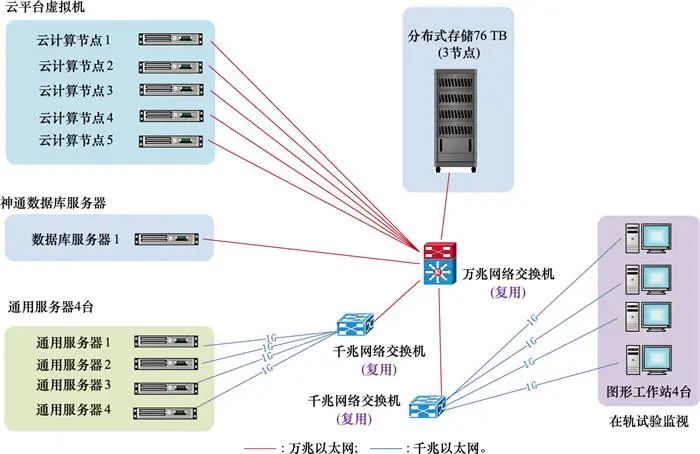
图6 硬件环境部署
3.2 实验结果分析
面向航天器在轨运行监视中测控遥测、数传遥测、数传图像、遥控指令等多源数据传输、交互、显示需求, 设计了大数据订阅吞吐性能、大数据传输性能两类实验, 共同验证BPSS的实际性能。
3.2.1 大数据订阅吞吐性能实验
首先采用不同量级的航天器在轨传输数据包进行数据发布(单体为1 M), 对比BPSS与当前国内外主流开源发布/订阅系统(例如Kafka、ActiveMQ、RabbitMQ、RocketMQ)的消息订阅响应时延。数据内容包括星地与星间通信的测控遥测、数传遥测、数传图像、操控指令等, 数据类型包括json、txt、jpeg、xml等。
消息订阅响应时延指数数据发布后直到订阅获得全部数据所消耗的时间, 如下所示:
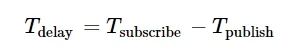
(1)
式中:Tdelay为消息订阅响应时延; Tsubscribe表示数据订阅时间戳; Tpublish为数据发布时间戳。
实验结果如表 1所示, 可知在不同量级的数据传输过程中, 数据订阅响应时延与订阅数据量呈现正相关关系。BPSS消息订阅平均响应时延为0.05 s, 其他发布/订阅系统如Kafka、ActiveMQ、RabbitMQ、RocketMQ的消息订阅平均响应时延分别为28.64 s、0.07 s、0.14 s、0.11 s, 相比而言BPSS具有更快的消息订阅响应速率。
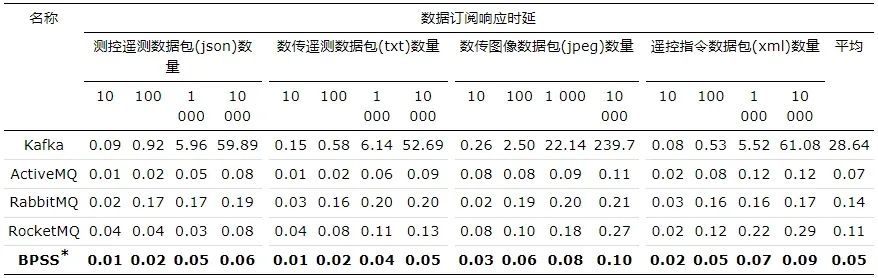
表1 不同发布/订阅系统响应时延对比
之后分别采用单体大小为1 M、10 M、100 M的航天器在轨传输数据包, 测试数据单体大小以及数据类型是否会对发布/订阅系统的订阅速率产生影响, 实验结果如图 7所示。分析可知, 在发布/订阅系统中, 数据订阅响应时延与订阅数据的单体大小呈正相关关系。同时, 相较于其他数据类型, 各发布/订阅系统对于jpeg图像类型数据的订阅响应时延都是最长的。但相比于其他的发布/订阅系统, BPSS对各类多源异构数据的响应速率差异化最小。

图7 不同数据包下各发布/订阅系统的响应时延
最后, 对系统的数据吞吐能力进行分析, 定义系统数据吞吐能力计算如下所示:
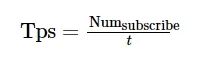
(2)
式中: Numsubscribe表示在数据持续发布的条件下订阅到的数据量统计; t表示订阅这些数据所花费的时间, 单位为s。
实验采用单体为1 M的航天器在轨传输数据包, 按照1 000包/秒的固有数据发送频率持续发布5 min, 测试BPSS与Kafka、ActiveMQ、RabbitMQ等发布/订阅系统的吞吐性能, 相关实验结果如图 8所示。可知, 吞吐能力越高Tps值越大, 且曲线走势越平稳, 因此BPSS在各发布/订阅系统中具备较好的吞吐性能。同时结合表 1分析可知, 消息订阅响应时延与发布/订阅系统的大数据吞吐性能成反比, 消息订阅响应时延越长其系统吞吐性能越差。
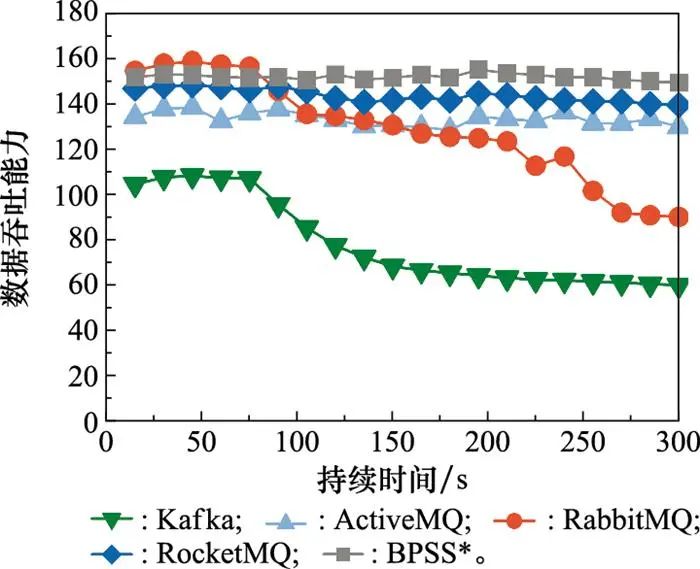
图8 不同发布/订阅系统吞吐性能比对
3.2.2 大数据传输安全性能实验
首先, 对比BPSS中基于消息一致性的动态选举算法与当前国内外主流选举算法(例如Paxos、Raft、PBFT等算法)的性能差异。在5个云节点分别采用不同算法进行100次主控节点选举并统计结果分布, 实验结果如图 9所示。
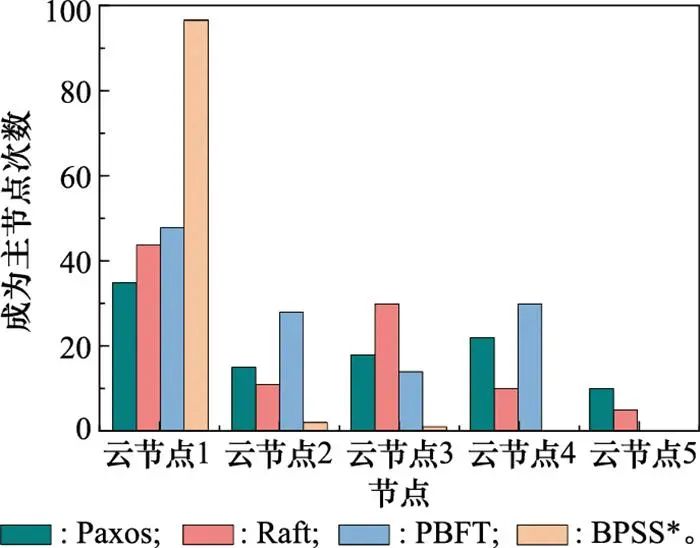
图9 不同主控节点选举机制性能比对
分析可知Paxos、Raft、PBFT等算法选举出来的主控节点在各个节点上都有所分布, 即集群中的任意节点都有机会当选为领导者节点。而BPSS中基于消息一致性的动态选举算法使得优先级最高的节点(云节点1)大概率保持为主控节点, 能够有效减少选举次数并提高选举效率, 同时避免集群节点数量变更引起网络拓扑结构频繁变化进而导致系统可用性降低的问题。
之后采用单体为1 M的航天器在轨传输数据包, 并对每包数据进行自增编号后按照1包/秒的频率进行发布, 分别统计持续订阅1 h、6 h、12 h、24 h(平均每小时传输数据量为3.52 GB)不同时长下的订阅数据编号缺失情况与数据内容完整度, 测试发布/订阅系统数据传输性能。
实验指标采取数据传输丢帧率Rf与数据破损率Rd,指标定义如下所示:
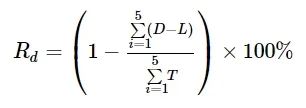
(4)
式中:T表示向各云节点发布的数据量;L表示各云节点订阅后丢失的数据量;D表示各云节点订阅到的数据量。实验结果如表 5所示。
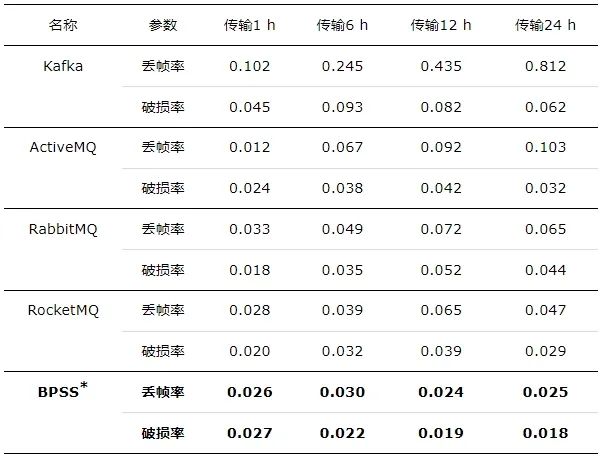
表5 不同发布/订阅系统传输数据完整性比对
结果表明, 单日吞吐量达到80 GB左右的量级时, BPSS数据传输丢帧率控制在0.025%, 数据破损率控制在0.018%, 且在单日各时刻内BPSS对于数据传输的丢帧与破损情况基本保持稳定, 具备大数据稳定性传输优势。
4 结束语
本文设计了一种面向航天器多源异构试验数据传输、管理的BPSS, 对云节点实现主从调控与弹性扩容, 并通过基于消息一致性的动态选举算法完成大规模发布/订阅任务, 实现高效、安全的航天器试验数据传输通信, 为航天器试验任务全生命周期实时监测、运行工况健康检测提供重要支撑。实验围绕大型航天器数管实验任务中高吞吐量的数据收发处理任务, 结果表明BPSS有效优化了数据发布/订阅响应速度, 尤其提升海量数据传输安全性与存储一致性, 具备数据响应迅速、高吞吐稳定性高等优势。未来工作中, 作者将进一步优化BPSS在云环境下更长周期的稳定处理性能。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现无法显示完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









