






源自:系统仿真学报
作者:康来 张亚坤
注:若出现显示不完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习
摘 要
基于视觉的手势识别是虚拟现实、游戏仿真等领域常用的人机交互手段。在实际应用中,手势动作快速变化将导致传统RGB相机或深度相机成像模糊,给手势识别带来巨大挑战。针对上述问题,利用动态视觉传感器捕捉高速手势运动信息,提出一种基于多维投影时空事件帧(spatiotemporal event frame, STEF)的动态视觉数据手势识别方法。将时空信息嵌入到数据投影面融合形成多维投影时空事件帧,克服现有动态视觉信息事件帧表达方法时域信息丢失的局限性,提升动态视觉传感数据的特征表达能力。在此基础上,采用先进的脉冲神经网络对时空事件帧进行分类实现手势识别。在公开数据集上的识别精度达到96.67%,性能优于同类方法,表明该方法可显著提升动态视觉传感数据手势识别准确率。
关键词
动态视觉传感器, 手势识别, 多维投影, 时空事件帧, 脉冲神经网络
引言
传统相机传感器(如:CMOS、CCD)以特定频率拍摄获取图像帧,每秒钟拍摄的图像数量称为帧率。普通消费级相机的帧率通常为30~60帧/s,由于曝光需要一定时间,成像通常存在数十毫秒甚至更大的延时。如果曝光期间物体高速运动,则会产生成像模糊。此外,传统相机的动态范围较低(约60 dB),在光线极暗或者亮度极高的环境下,均无法获取足够的信息。上述问题限制了传统相机在快速运动或对实时性要求极高的场景中的应用。
事件相机(event camera)是一种生物启发(bio-inspired)的神经拟态(neuromorphic)新型视觉传感相机,能够响应局部亮度变化,也称作动态视觉传感器(dynamic vision sensor, DVS)[1]。与传统相机使用快门捕获图像不同,DVS中的每个像素都独立、异步地运行,仅在亮度变化(变亮或变暗)达到一定阈值时才输出一个事件(event),这些事件称为动态视觉传感数据。与传统相机相比,DVS具有诸多优势。首先,DVS的延迟极低(通常为微秒级),可以更快地捕捉到亮度的变化,且不会像传统相机那样产生运动模糊。其次,由于动态视觉传感器异步监测每个像素,只有当强度变化超过阈值时才会产生事件,在没有变化的情况下始终处于静默状态,因此具有更低的能耗。此外,DVS的动态范围远高于传统相机,通常可超过140 dB。目前,DVS技术在学术界逐渐引起了较大关注,相关研究已经拓展到目标跟踪[2]、目标识别[3]、手势识别[1]、结构光三维扫描[4]、光流估计[5]、高动态范围(high dynamic ranging, HDR)图像重建[6]、即时定位和建图(simultaneous localization and mapping, SLAM)[7-8]等领域。
由于DVS的工作模式及其数据形态均与传统相机完全不同,为了更好的发挥DVS的固有优势,需要设计全新的数据表达和数据处理方法[9]。在DVS数据表达方面,需针对特定应用将事件数据转换为其他表达形式,以便提取出有用信息和特征。常见的数据表达形式包括事件帧(event frame)、时间表面(time surface)、体素网格(voxel grid)、三维点集(3D point set)等形式[9]。其中,事件帧将一组事件数据转换为一幅图像,该表达形式在文献中占据重要地位[10-11],其主要原因是它可通过简单的变换(比如:统计各像素位置的事件数量[12])将事件数据转换为标准、易于处理的二维图像数据。事件帧保留了丰富的场景边界信息,而且可以利用现有基于图像的计算机视觉算法对其进行处理。事件帧方法的不足是抛弃了事件数据的稀疏性[13],且丢失了时域信息。时间表面也将事件数据转换为二维图像,但各像素记录的是相应位置上事件发生的最近时刻[14]。时间表面图本质上反映了各像素位置的历史变化情况,值越大说明该位置发生变化的时间越近。时间表面法通常结合归一化处理不同的变化速度[15],采用滤波方法减少噪声的影响[16]。三维点集表达将事件数据视为几何数据,3个维度分别对应于二维像素坐标和事件时刻[17]。DVS数据处理方式很大程度上取决于数据表达方式。对于原始事件数据,通常采用卡尔曼滤波和粒子滤波等概率滤波器(贝叶斯方法)进行处理。滤波器能够自然的处理异步数据,具有较低的时延,而且能够融合多个传感器的数据[18]。另一类主流处理方法是基于人工神经网络(artificial neural network, ANN)的方法,包括卷积神经网络(convolutional neural network, CNN)[1,17]和脉冲神经网络(spiking neural network, SNN)[19-20]。DVS数据表达和处理方法目前尚没有统一的标准和框架,DVS技术及相关应用仍处于快速发展阶段,相关探索具有巨大的研究价值和空间,相关综述可参考文献[9]和[21]。
本文关注基于动态视觉传感数据的手势识别问题。手势识别是一种重要的人机交互手段,被广泛应用于虚拟现实、游戏仿真等领域[17]。由于普通消费级RGB相机或深度相机曝光通常需要数十毫秒时间,手势动作快速变化时,曝光期间场景动态变化导致成像模糊。本文采用动态视觉传感器可以获得微秒级极低延迟事件数据,从根本上避免成像模糊问题,并设计新的数据处理和识别方法实现手势识别。本文提出一种基于多维投影时空事件帧(spatiotemporal event frame, STEF)的动态视觉数据手势识别方法,将时间信息嵌入到数据投影面,与原单通道空间事件帧进行融合,增强动态视觉传感数据的特征表达能力,然后采用先进的脉冲神经网络结合自动精度混合模式实现动态视觉数据手势识别。最后,在公开数据集上对本文方法进行测试评估。
1 本文方法
事件相机与传统相机相比具有诸多优点,但由于动态视觉传感器事件流数据与传统RGB图像数据形态之间巨大差异,传统的图像处理算法均无法直接对动态视觉传感数据进行处理,因此需要对事件流数据进行某种形式的转换和表达。本文动态视觉传感数据手势识别基本流程如图 1所示。
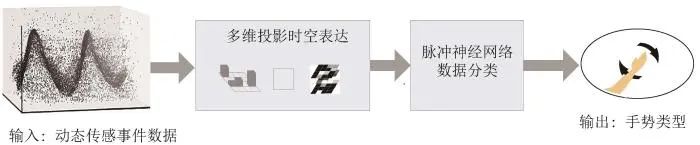
图 1 动态传感数据手势识别基本流程
1.1 事件相机成像模型
传统相机拍摄获取的图像记录的是某一时刻场景的明暗颜色信息,图像所有像素均在相同的时刻记录。根据硬件性能不同,传统RGB相机图像分辨率一般在百万至千万像素级别,每秒可以拍摄的图像数量在几十帧到几千帧。因此,传统相机在空间上具有高分辨率,而在时域上分辨率较低。
事件相机记录场景位置亮度的变化情况,只有当亮度变化值超过一定阈值才会触发一个事件。随着场景变化,事件源源不断的产生输出事件流。每个像素是相互独立的,数据处理异步执行,事件刷新延时通常为微秒级。因此,事件相机的时域分辨率远高于传统RGB相机,可以捕捉到快速变化的细节信息。每个事件表示为
![]()
(1)
式中:x、y为二维图像平面内像素的横、纵坐标;t为事件发生的时刻;p∈{+1,−1}为事件的极性。记ek=(x,y,tk,pk)为tk时刻像素位置(x,y) 发生的事件,I(x,y,t) 为t 时刻像素位置(x,y) 的图像亮度,Δt 为t 时刻之后逝去时间,C>0 为时序亮度阈值,一旦像素亮度满足:
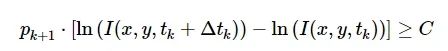
(2)
则将触发产生一个新的事件:
![]()
(3)
从上述模型原理可以看出,事件相机仅记录场景的变化,因此又称为动态视觉传感器。
事件相机成像基本原理示意图和相机数据示例如图2所示。
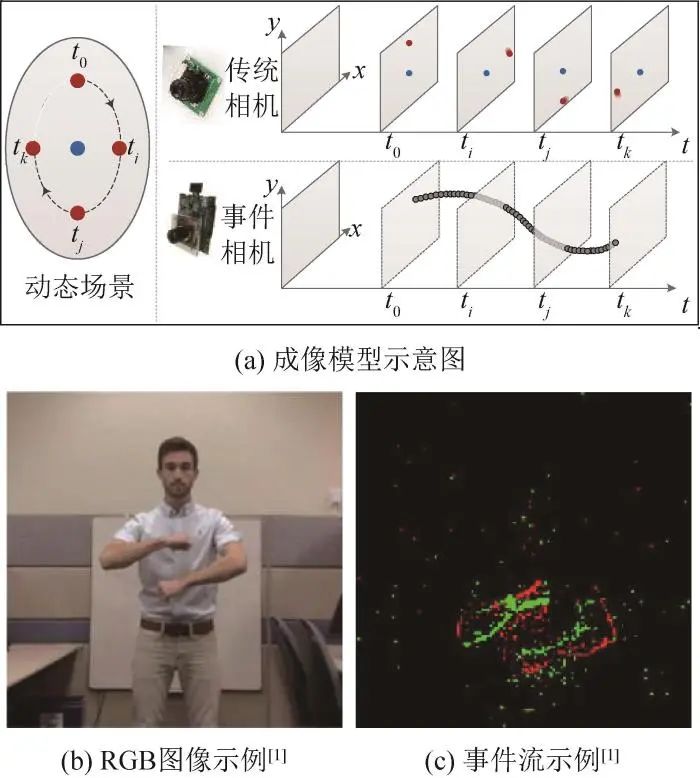
图 2 相机成像模型及图像示例
图2(a)中展示的动态场景包含2个圆点,外侧圆点以内部圆点为中心顺时针高速旋转,动态场景中标记了t0,ti,tj,tk 4个时刻圆点所在位置。传统相机在t0,ti,tj,tk 4个时刻分别对上述动态场景进行拍摄获得的4幅图像如图2(a)右上子图所示,各图像中内部圆点清晰,而外侧圆点由于快门速度不够出现“拖尾”现象。利用动态视觉传感器拍摄上述场景产生的事件流如图2(a)右下子图所示,每个灰色圆点代表一个事件,包含了像素坐标、事件时刻(注意,图中未区分事件的极性)。从图2(a)可以看出,动态视觉传感器产生的事件流数据和传统RGB相机的二维图像数据形态有本质区别。为了进一步直观地理解动态视觉传感数据流形态,图2(b)和(c)分别展示了两类相机拍摄DVS128 Gesture数据集中“arm roll”手势场景获取的数据示例[1]。其中,图 2(c)包含了某个5 ms时间范围内的所有事件,采用红(正极,即p=1)、绿(负极,即p=-1)两种颜色区分事件极性,从图中可以看出运动区域的边界信息,但也包含明显的背景噪声。
1.2 多维投影事件数据表达
本文提出基于多维投影的动态传感数据时空事件帧STEF表达,可以有效克服传统积分帧抽取导致的时域信息丢失问题,提高数据的表达能力,进而达到提升手势识别性能的目的。
1.2.1 归一化积分事件帧抽取方法
积分帧的基本思想是将某段时空邻域中的所有事件进行累加获得各像素位置的事件数量(区分不同极性),并将结果转化为二维图像。其优点是转化为数据积分帧后可以直接采用现有图像处理算法对其进行处理,既保持了动态视觉传感器的高动态性,又极大的简化了数据处理流程。
事件流数据积分帧抽取过程示意图如图 3所示。记积分帧为
![]()
,它包含两幅尺寸为W×H 像素的图像,分别对应于正、负极性事件积分帧。积分帧特定像素位置(x,y) 的像素值记为ℱt(x,y,p) 。其中,p 与式(1)中的含义相同,均表示事件的极性,这里也用于区分正、负极事件积分帧。则事件集合为
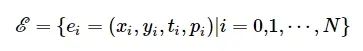
(4)
式中:N为事件的数量。
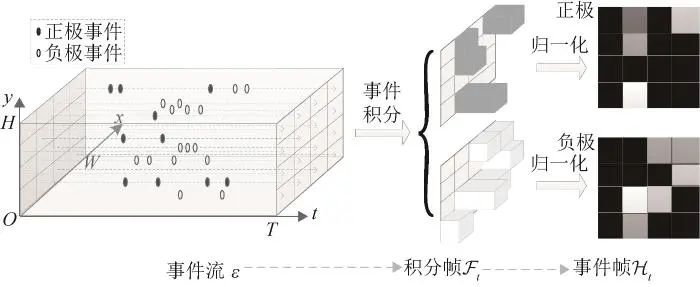
图 3 事件流数据积分帧提取过程示意图
对应的事件流数据积分帧Ft 各像素数值的计算公式为
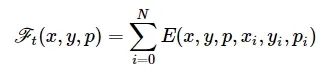
(5)
其中,
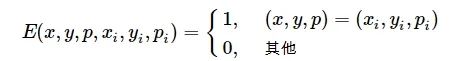
(6)
图3中,由于数据积分帧
![]()
各像素的值取决于该像素位置事件的数量和极性,因此各积分帧
![]()
的像素取值范围存在差异,甚至可能超出RGB通道的最大值255。为了对事件流积分数据帧进行规范化统一描述,将积分帧Fℱ进行归一化处理,事件集合转换为两幅尺寸为W×H 像素的灰度图事件帧
![]()
,其像素值的取值范围为
![]()
。
1.2.2 多维投影时空事件帧抽取方法
如图3所示,归一化积分事件帧ℱt 的提取过程本质上是沿时间轴t 方向投影。由于积分帧抽取过程中事件的顺序无法保持,因此归一化积分事件帧不可避免的丢失了时域信息,削弱了动态视觉传感器对场景的描述能力。为了弥补上述缺陷,本文提出基于多维投影的时空事件帧STEF数据表达方式。
采用类似于获取ℱt 的计算过程,沿动态视觉传感器坐标系x 轴方向投影获取积分帧
![]()
。Fx 包含两幅尺寸为T×H 像素的图像,分别对应于t−y 平面正、负极性事件积分帧。Fx 包含了事件的y 坐标信息和时间信息t ,因此对仅包含x,y 坐标信息的积分帧ℱt 是一种有效的增强和补充。更进一步,可沿y 轴方向投影获取积分帧
![]()
。将Ft 、Fx 和Fy 进行对齐、融合以及归一化处理,可获得包含6幅灰度图(尺寸为W×H 像素)的时空事件帧
![]()
。这里,对齐操作主要是对Fxℱ 和Fy 进行重采样,使其各通道图像尺寸分别由T×H 、T×W 统一转换为W×H 。时空事件帧Hℋ各通道图像承载了事件数据在时间和纵、横图像空间3个维度的信息,能够有效提升事件帧表达能力。
1.2.3 时空事件帧集合构建方法
将事件集合
![]()
={ei|i=0,1,⋯,N}按照时间戳均匀划分为Q 个事件子集
![]()
(s=0,1,⋯,Q−1) 。事件集合
![]()
中事件的起始时间戳为t0 ,结束事件戳为tN ,各事件子集
![]()
的划分起始时刻和结束时刻为
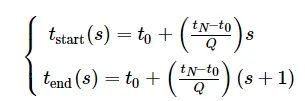
(7)
记Nstart(s) 和Nend(s) 分别为满足式(8)所示不等式条件的最小整数:
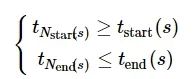
(8)
则事件子集
![]()
可以显式地表示为
![]()
(9)
在此基础上,按照第1.2.2所述方法对
![]()
进行多维时空投影处理,最终将事件集合
![]()
转换为Q个时空事件帧集合:
![]()
1.3 基于脉冲神经网络的手势识别方法
多维投影时空事件帧STEF与传统多通道图像表达形式一致,可以采用经典深度神经网络CNN进行训练和分类[1,17],也可采用功耗更低、类生物结构合理性的新型脉冲神经网络SNN对上述数据进行处理。本文采用文献[20]提出的脉冲神经网络架构对时空事件帧集{Hs}ℋ进行分类实现手势识别,该网络的基本架构如图4所示。在训练过程中,同时训练SNN模型突触权重和膜电位时间参数,降低初值的敏感性及加速训练过程。
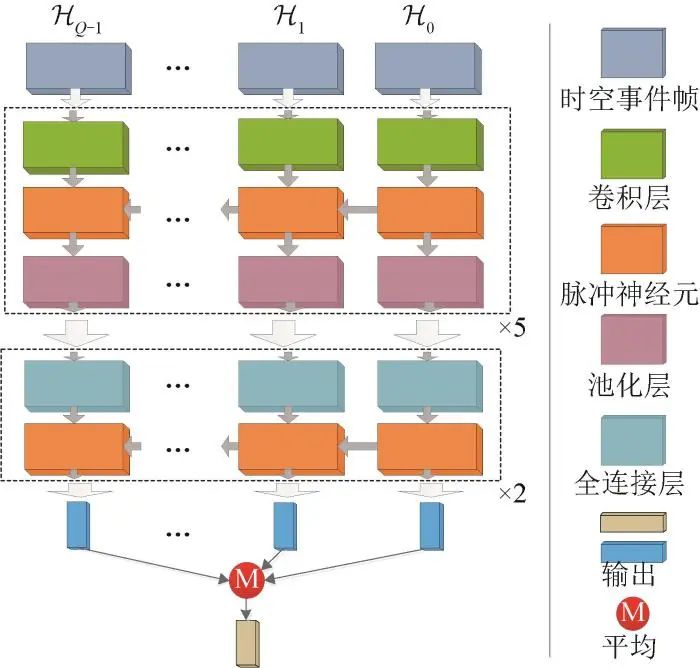
图 4 基于脉冲神经网络的手势识别网络架构
2 实验验证
为了验证本文方法的有效性,实现了相关算法并在公开数据集上对其性能进行评估。其中,深度学习训练和推理硬件为NVIDIA RTX 3090显卡,显存大小为24 GB,通用并行计算架构为NVIDIA CUDA平台,深度学习模型训练及推理基于SpikingJelly实现。其中,SpikingJelly是一个基于PyTorch的开源脉冲神经网络深度学习框架[20]。
2.1 数据集
本文使用的数据集为DVS128 Gesture公开数据集[1]。该数据集由iniLabs DVS128相机拍摄,图像空间分辨率为128×128像素,事件时间戳粒度为微秒刻度(即时域刷新频率为每秒100万帧)。该数据集包括29名对象在不同照明条件下(自然光、荧光灯和LED灯)的动作数据片段,23名对象数据为训练集、其余6名对象数据片段为测试集。手部和手臂动作姿势类型共11类(划分表如表 1所示)。其中,第11类是除去前10类动作以外的其他动作类型,由于该类型手势数据不确定性更大,容易造成训练以及测试的不稳定性,对手势识别提出了更大的挑战。

表 1 DVS128 Gesture手势类型划分
DVS128 Gesture数据集数据样例如图5所示。为了便于展示事件数据,图5中各图展示了5 ms时间范围内的所有事件,并且采用红、绿两种颜色区分事件极性。图5第1行为“hand clap”动作5个顺序时间段的事件数据,由于硬件性能和环境条件影响背景中产生一定量的噪声,人眼可大致分辨该动作类型。图5第2、3行分别展示了其他10种手势动作的事件数据。
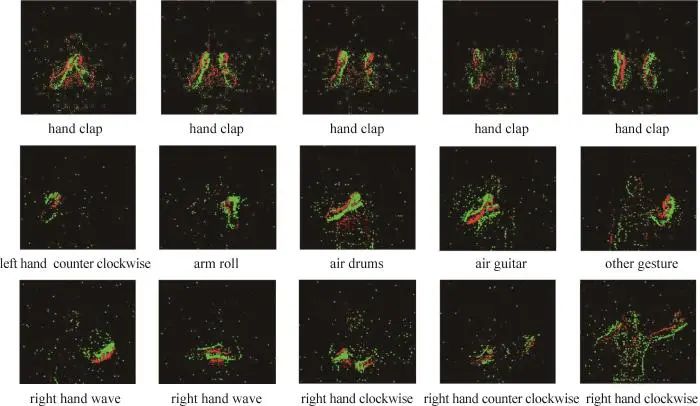
图 5 DVS128 Gesture数据集示例
2.2 实验设置
本文所有实验均采用统一的超参数设置,具体如下。训练轮数(epochs)为256,批大小(batchsize)为16。初始学习率(learning rate)为0.001,并采用余弦退火策略动态调整学习率[22]。在神经网络推理过程中,通过开启自动混合精度(automatic mixed precision, AMP),对不同的网络层采用不同的数据精度进行计算,实现节省显存和加快训练速度的目的。此外,通过CuPy实现Numpy数组的并行加速运算。
2.3 结果与分析
本文脉冲神经网络训练过程如图6所示。事件帧方法指的是采用归一化积分事件帧对事件数据进行处理(见第1.2.1节),然后采用脉冲神经网络进行手势识别。从图6展示的训练过程可视化中可以看出,2种方法具有相似的训练特性,本文方法的训练收敛速度略快,说明了本文方法引入的时空事件帧的有效性。在运算效率方面,本文实验使用NVIDIA 3090显卡进行训练,在未设置Cupy与自动混合精度运算时每轮训练耗时约39 s,设置Cupy与自动混合精度,并对数据结构进行优化后,最终每轮训练耗时约12 s,大幅降低了时间开销。
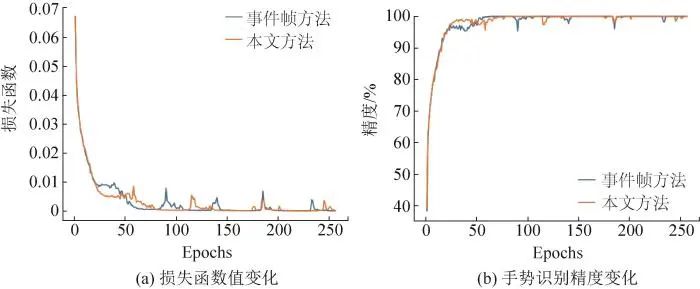
图 6 脉冲神经网络训练过程
利用本文第1.2.3节所述方法为DVS128 Gesture数据集每个事件数据片段创建一个包含16个时空事件帧的时空事件帧集合。时空事件帧创建示例如图7所示(注意:本图仅展示正极性事件)。

图 7 本文时空事件帧创建示例
其中,图7(a)为沿时间轴t投影获得的x−y平面内的事件帧,图7(b)为沿y轴投影获得的t−x平面内的事件帧,图7(c)为t−x平面事件帧归一化处理结果,图7(d)为沿x轴投影获得的t−y平面内的事件帧、图7(e)为t−y平面事件帧归一化处理结果。将各投影维度事件帧融合后可获得包含6个通道的时空事件帧。图7(f)展示了图7(a)、(c)、(e)的融合结果。为便于观察,图7(f)仅展示正极性事件,并将t、y、x轴对应的事件帧作为颜色通道进行映射,实际计算过程种无需生成RGB图像。
图8为不同方法在DVS128 Gesture测试集上的手势识别精度对比结果。其中,Low power方法将动态视觉数据转换为传统空间事件帧,然后采用传统CNN模型进行识别,其识别精度为94.59%。Event cloud方法将事件数据作为点云进行处理和识别,其识别精度为95.32%。其余方法均基于传统空间事件帧数据表达,采用SNN进行识别,精度在92.10%~96.18%之间。SpikingJelly(AMP)为文献[20]所述方法在开启自动混合精度且每个手势片段划分为16的实验结果,在相同的参数设置下,本文方法的识别精度达到了96.67%。上述实验结果表明,本文方法可以显著提升动态视觉传感数据手势识别的准确率,性能优于同类方法。与SNN传统方法实验相比,本文方法的优势主要体现在对随机手势(表1中的动作类型11)这类较困难的手势具有更好的识别效果,而误识别主要集中在多种光源条件下更具挑战的复杂情形。
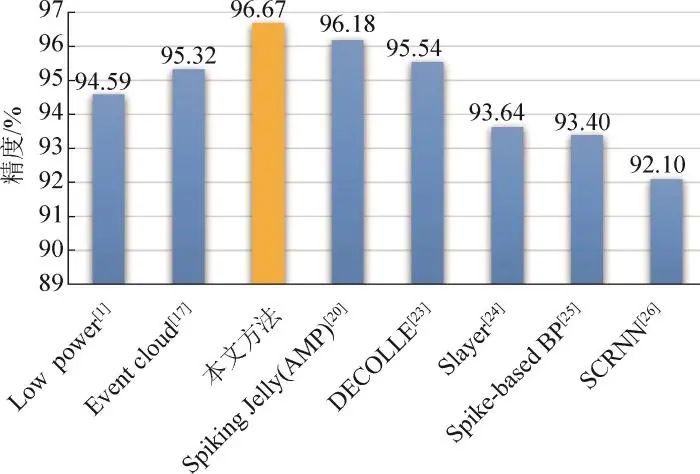
图 8 手势识别精度比较
3 结论
本文提出一种基于多维投影时空事件帧的动态视觉数据手势识别方法,将时间信息嵌入到数据投影面,与原单通道空间事件帧进行融合,有利于增强动态视觉传感数据的特征表达能力,采用先进的脉冲神经网络结合自动精度混合模式实现动态视觉数据手势识别。在公开数据集上的测试表明,本文方法的性能优于同类算法。后续研究拟尝试多种神经网络模型以验证本文STEF方法的适应性与普遍性,并针对多种光源条件引起的误识别情况,采用滤波方式降低背景噪声对识别性能的影响。从而进一步发挥动态视觉传感器高动态、低冗余、低消耗以及不受光照条件影响的优势,为虚拟仿真、智能驾驶、互动游戏等应用提供人机交互支持。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
注:若出现显示不完全的情况,可 V 搜索“人工智能技术与咨询”查看完整文章
人工智能、大数据、多模态大模型、计算机视觉、自然语言处理、数字孪生、深度强化学习······ 课程也可加V“人工智能技术与咨询”报名参加学习















 3049
3049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









