






一、案例引入
(一)问题提出
回访问卷是一种常用的、用于评估客户质量的手段,基于回访问卷所得数据,我们一定程度上能够推断具有什么样特征的用户可能更具有产品依赖性。
因此,基于某车险回访问卷,我们利用sklearn库中各类模型对其进行预测,并展示此案例中各模型预测的表现情况。
(二)原始数据
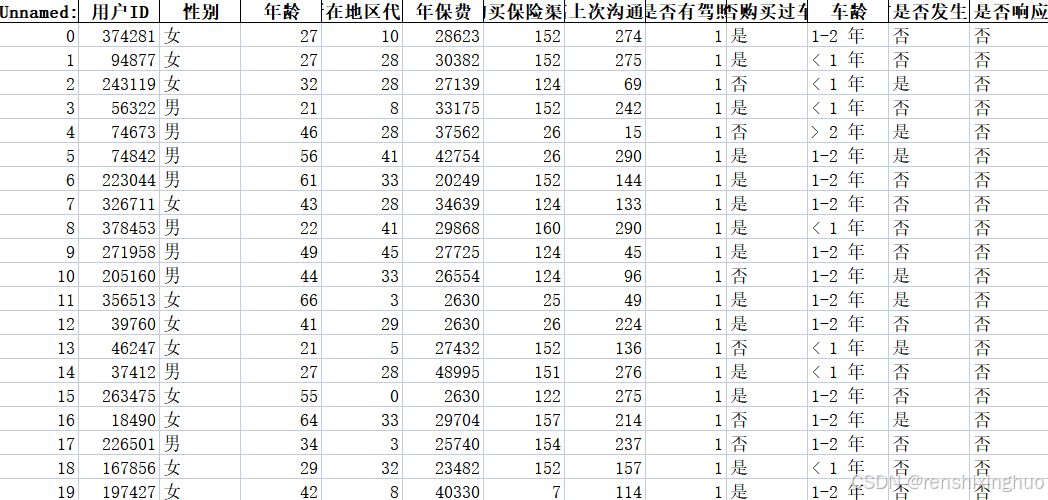
原始数据包含用户ID、性别、年龄、所在地区代码、年保费、沟通渠道、是否有驾照、是否购买过车辆、车龄、是否发生过车祸、是否响应,共计十一个信息维度。
二、数据处理、模型调用
(一)解决中文乱码、导入数据
import pandas as pd
import pylab as mpl
#正常显示中文字符
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
#读取车险数据
df=pd.read_excel('数据.xlsx')(二)变量处理、转化为数值型
#分割被预测变量,转换为数值型
y=pd.DataFrame()
#建立转换字典
d={'是':1,'否':0}
y['是否响应']=df['是否响应'].map(d)
#观察预测变量列表,用户ID可能与被预测变量无关,因而不考虑用户ID,处理其余变量
X=pd.DataFrame()
sex={'女':1,'男':0}
X['性别']=df['性别'].map(sex)
X['年龄']=pd.qcut(df['年龄'],5,labels=False)#年龄按比例划分为5档
X['地区']=df['所在地区代码']
X['年保费']=pd.qcut(df['年保费'],5,labels=False)#年保费按比例划分为5档
X['购买渠道']=df['购买保险渠道']
X['距离上次沟通时间']=pd.qcut(df['距离上次沟通时间'],5,labels=False)
X['是否有驾照']=df['是否有驾照'].map(d)
X['是否购买车险']=df['是否购买过车险'].map(d)
carage={'< 1 年':0,'1-2 年':1,'> 2 年':2}
X['车龄']=df['车龄'].map(carage)
X['是否发生过事故']=df['此前是否发生事故'].map(d)(三)导入模型,进行预测
#调用模型,进行预测
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
models=[]
#添加模型
models.append(LinearDiscriminantAnalysis())#线性判别分析
models.append(KNeighborsClassifier())#K最近邻
models.append(DecisionTreeClassifier())#决策树
models.append(GaussianNB())#高斯朴素贝叶斯
models.append(GradientBoostingClassifier())#梯度提升树
models.append(RandomForestClassifier())#随机森林
单次预测
accuracies=[]
model_names=[]
#切分训练集和预测集,比例为7:3
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42)
for model in models:
model.fit(X_train, y_train)
y_pred=model.predict(X_test)
accuracy=accuracy_score(y_test,y_pred)
accuracies.append(accuracy)
model_names.append(model.__class__.__name__)
#输出各个模型的准确率
for name, accuracy in zip(model_names, accuracies):
print(f'{name}: {accuracy:.2f}')多次预测
切分训练集和预测集,比例为7:3,重复100次
for model in models:
model_names.append(model.__class__.__name__)
for i in range(100):
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=i)
for model in models:
model.fit(X_train, y_train)
y_pred=model.predict(X_test)
accuracy=accuracy_score(y_test,y_pred)
accuracies.append(accuracy)
#将所得到精确值每六个分为一组
accuracy_data=[accuracies[i:i+6] for i in range(0,len(accuracies),6)]
data=pd.DataFrame(accuracy_data,columns=model_names)(四)模型预测精确值结果展示
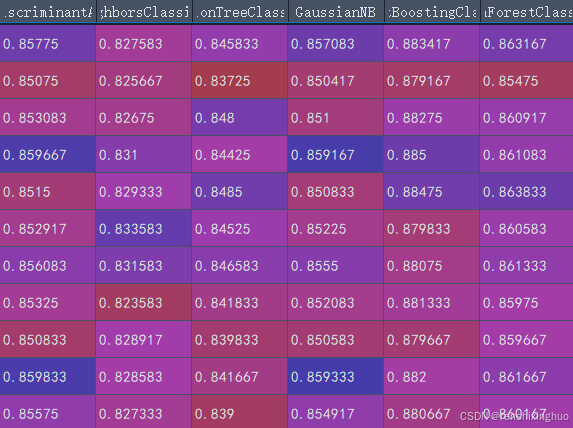
结果只展示前十条
三、模型预测结果对比
(一)箱线图绘制
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
# 绘制箱线图
boxplot=plt.boxplot(
x=data,
vert=True, # 垂直排列
widths=0.3,
labels=model_names, # 箱形图的标签
patch_artist=True, # 为箱子填充颜色
medianprops={'linestyle': '-', 'color': 'black', 'linewidth': 1.2},
showfliers=False, # 不显示异常值
whiskerprops={ 'linestyle': '--', 'linewidth': 1, 'color': 'black'},
capprops={'linestyle': '-', 'linewidth': 1.5, 'color': 'black' })
plt.xticks(rotation=10)#横坐标倾斜10°
box_colors = ['LightSteelBlue','lightblue','LightSkyBlue','SkyBlue','CornflowerBlue','RoyalBlue']#填充颜色
for patch, color in zip(boxplot['boxes'], box_colors):
patch.set_facecolor(color)
plt.title("模型精确度箱形图")
plt.show()(二)结果展示
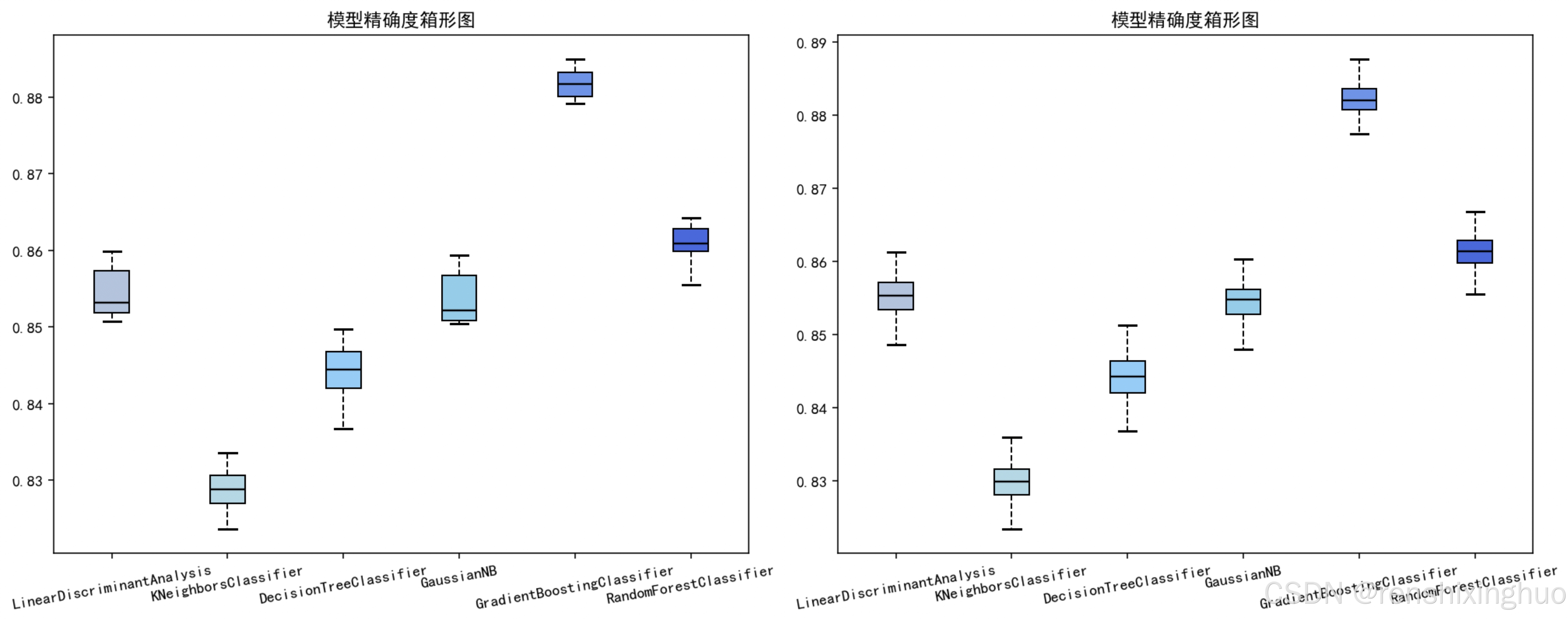 左图为十次预测结果、右图为百次预测结果。
左图为十次预测结果、右图为百次预测结果。
(三)结果分析
可以看到,针对此案例,GradientBoostingClassifier即梯度提升树模型表现最为良好,稳定性也较高,KNeighborsClassifier即K最近邻分类表现不佳,但在十次预测中,稳定性良好。
四、完整代码展示
import pandas as pd
import pylab as mpl
#正常显示中文字符
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
#读取车险数据
df=pd.read_excel('数据.xlsx')
#分割被预测变量,转换为数值型
y=pd.DataFrame()
#建立转换字典
d={'是':1,'否':0}
y['是否响应']=df['是否响应'].map(d)
#观察预测变量列表,用户ID可能与被预测变量无关,因而不考虑用户ID,处理其余变量
X=pd.DataFrame()
sex={'女':1,'男':0}
X['性别']=df['性别'].map(sex)
X['年龄']=pd.qcut(df['年龄'],5,labels=False)#年龄按比例划分为5档
X['地区']=df['所在地区代码']
X['年保费']=pd.qcut(df['年保费'],5,labels=False)#年保费按比例划分为5档
X['购买渠道']=df['购买保险渠道']
X['距离上次沟通时间']=pd.qcut(df['距离上次沟通时间'],5,labels=False)
X['是否有驾照']=df['是否有驾照'].map(d)
X['是否购买车险']=df['是否购买过车险'].map(d)
carage={'< 1 年':0,'1-2 年':1,'> 2 年':2}
X['车龄']=df['车龄'].map(carage)
X['是否发生过事故']=df['此前是否发生事故'].map(d)
#共计十个维度
#调用模型,进行预测
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
models=[]
#添加模型
models.append(LinearDiscriminantAnalysis())#线性判别分析
models.append(KNeighborsClassifier())#K最近邻
models.append(DecisionTreeClassifier())#决策树
models.append(GaussianNB())#高斯朴素贝叶斯
models.append(GradientBoostingClassifier())#梯度提升树
models.append(RandomForestClassifier())#随机森林
accuracies=[]
model_names=[]
#切分训练集和预测集,比例为7:3,重复100次
for model in models:
model_names.append(model.__class__.__name__)
for i in range(10):
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=i)
for model in models:
model.fit(X_train, y_train)
y_pred=model.predict(X_test)
accuracy=accuracy_score(y_test,y_pred)
accuracies.append(accuracy)
#将所得到精确值每六个分为一组
accuracy_data=[accuracies[i:i+6] for i in range(0,len(accuracies),6)]
data=pd.DataFrame(accuracy_data,columns=model_names)
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
# 绘制箱线图
boxplot=plt.boxplot(
x=data,
vert=True, # 垂直排列
widths=0.3,
labels=model_names, # 箱形图的标签
patch_artist=True, # 为箱子填充颜色
medianprops={'linestyle': '-', 'color': 'black', 'linewidth': 1.2},
showfliers=False, # 不显示异常值
whiskerprops={ 'linestyle': '--', 'linewidth': 1, 'color': 'black'},
capprops={'linestyle': '-', 'linewidth': 1.5, 'color': 'black' })
plt.xticks(rotation=10)#横坐标倾斜10°
box_colors = ['LightSteelBlue','lightblue','LightSkyBlue','SkyBlue','CornflowerBlue','RoyalBlue']#填充颜色
for patch, color in zip(boxplot['boxes'], box_colors):
patch.set_facecolor(color)
plt.title("模型精确度箱形图")
plt.show()
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









