







 本文介绍了从单层感知机到深度学习中的关键网络结构,包括多层感知机、DNN、CNN和RNN。讨论了深度学习中遇到的梯度消失问题以及解决方案,如ReLU、ResNet和LSTM。LSTM通过门控机制解决了RNN的长时间依赖问题,增强了对时间序列的建模能力。
本文介绍了从单层感知机到深度学习中的关键网络结构,包括多层感知机、DNN、CNN和RNN。讨论了深度学习中遇到的梯度消失问题以及解决方案,如ReLU、ResNet和LSTM。LSTM通过门控机制解决了RNN的长时间依赖问题,增强了对时间序列的建模能力。
单层感知机
拥有输入层、隐含层、输出层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。只能处理很简单的函数。
多层感知机(现在叫神经网络NN)
特点:包含多个隐含层;
使用sigmoid和tanh等连续函数模拟神经元对激励的响应;
使用反向传播BP算法来训练;
摆脱了早起离散传输函数的束缚。
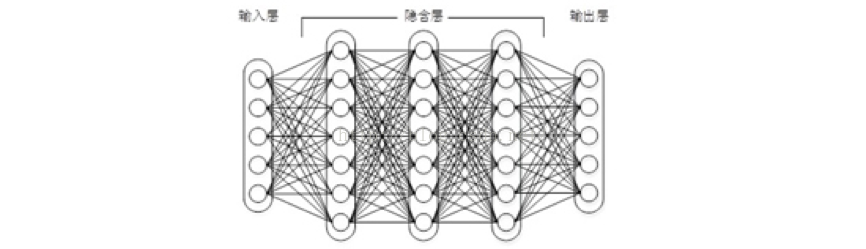
图1上下层神经元全部相连的神经网络——多层感知机
神经网络的层数直接决定了它对现实的刻画能力——利用每层更少的神经元拟合更加复杂的函数。
层数增加带来的问题:
优化函数容易陷入局部最优,偏离真正的全局最优;
性能下降;
“梯度消失”现象严重。
2006年,Hinton利用预训练方法缓解了局部最优解问题,将隐含层推动到了7层。
DNN深度神经网络
克服梯度措施:用ReLU、maxout等传输函数代替了sigmoid,形成了如今DNN的基本形式。单从结构上来说,全连接的DNN和图1的多层感知机没有任何区别。
后来的高速公路网络(highway network)和深度残差学习(deep residual learning)进一步避免了梯度消失,网络层数达到了前所未有的一百多层(深度残差学习:152层)
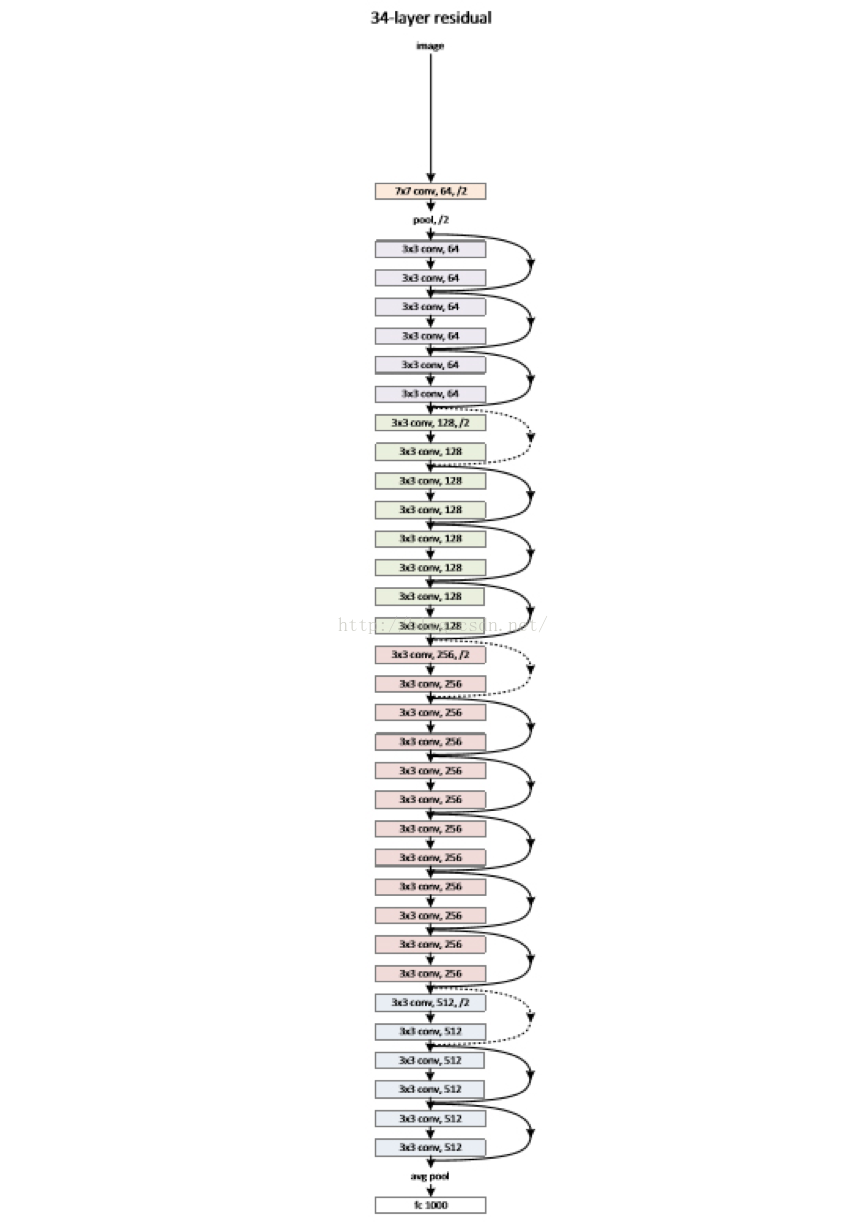
图2缩减版的深度残差学习网络,仅有34层,终极版有152层
全连接DNN潜在问题:参数数量的膨胀。这不仅容易过拟合,而且极容易陷入局部最优。另外,图像中有固有的局部模式可以利用,应该将图像处理中的概念和神经网络技术相结合。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









