






模型的训练参数,到底应该怎么调?这应该是我听过最多的问题了,不如说。我最开始研究训练的时候也特别在乎参数到底应该怎么搭配?这样调是不是不够好?那样改是不是发挥不出模型本身的能力?这么多的参数都是什么意思?我有选择困难症,到底应该怎么做?
我在这里先直接说我的观点好了,调参是一个非常复杂的东西。但是确确实实是有效果的,只不过需要你有相当大的耐心,因为这个是和经验主义绑定的相当夸张的。我们调参的目的是激发你数据集里最大的潜力,就好比你本来可以考90分,但是你不会学,乱学一通。最后只考了70分。我们的目的就是通过调参。让模型无限接近最为优秀的分数。
调参就是需要实实在在上手的东西。就是因为不同参数之间的搭配太多了。实在太复杂了,所以基本没什么可以套的“模版”。即便有一个模版,但是换了另一种数据集,可能完完全全又是另一种调参方式了。
我想这是很多新入门的同学特别头疼的一件事。如果你也处于这种对参数无法理解,半懂不懂,甚至完全不了解的情况下,那么就由我带领你把“参数”这块内容给捋清楚吧。
我会首先介绍训练参数的各个含义,以及他们的使用方法。
首先,为了让大家可以实际用到我说的参数,我将直接基于llama-factory这个项目中基于它的界面介绍,且只讲关键的。
第一个:learning_rate
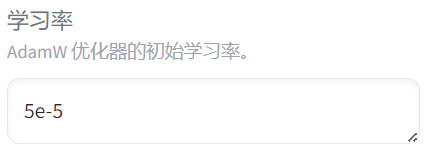
一般简写为lr
它是学习率的意思。这是一个很重要的超参数。可以直接影响你模型的最终效果。其中'e' 的意思是"10的次方"。
比如说:
5e5指的是:前面的5 乘以后面的 10 的 5 次方 ,也就是500000
这只是举例,我们不可能用5e5的学习率,所以我们会加上“-”负号
也就是5e-5 前面的5 乘以后面的 -10 的 5 次方 ,就是0.00005
为什么要这样计数呢?想象一下,如果一个数是 0.00000005,这样写很容易数错零对吧?但如果写成 5e-8,就简单多了。所以,'e' 就是个小技巧,也更省力。
那学习率有什么用呢?问的好!理论上来说,学习率越大,模型学的速度也就越快,但是学的不精。学习率越小,模型学的速度越慢。但是学的很精细。
为了让大家更好的理解,我来举一个例子。
学习率大:假设你想看一本关于模型训练的书。打算花一天的时间就看完。所以为了赶紧看完,你一目十行。基本不怎么思考。虽然看的快,但是也可能漏了很多关键信息和细节,没有太多的停留。最终可能你好像学会了,但是又好像没学到什么。甚至可能还会错误理解其中的一些内容。
优点:能快速了解书的大致内容,知道了整体大概框架。
缺点:可能错过重要细节,理解不深,记住的内容有限。
学习率小:这次换成你打算静下心来好好读模型训练书。所以打算花更长的时间学习。你准备花一个星期好好的研读。这期间你每天读一部分,然后细细评味其中的原理和实际的运用方法。这次你虽然花了很多的时间,但是你收获很大,远远比第一次学到了更为详细的内容。
这就是学习率小的情况
优点:能深入理解内容,记住更多细节,收获更多。
缺点:相对来说需要更长的时间,如果时间有限,可能无法完成整本书。
看完了上面的内容,你可能会说:学习率低的缺点好像可以接受啊!只要能学好我给它的数据,那慢一点又何妨呢?
对此,我想说 no no no
如果真的那么简单那也不需要调整学习率了。
学习率很低的情况下,你的模型可能会收敛的非常非常的慢,慢到你甚至以为它根本就没有在训练。而且最致命的问题是,它可能会去“抠字眼”也就是说在某个地方会死脑筋,不会联系整个内容框架。一根筋的去研究每一段内容,甚至每一个字。如果你的数据集噪声很大,它甚至会去非常认真的去学习噪声。
所以这种情况很容易出现过拟合现象。也是学成书呆子了。这也是我们常说的模型陷入了局部最优的情况。(即在某一个区间找到了最优质的点。但是这个点在整个区间上并不是最优的。)
所以,一般来说,我们都是使用学习率调度器,例如:cosine
它会首先在你设定的学习率的初始值逐渐减小,也就是说。你的学习率并不是一直固定不变的。而是随着模型的不断学习一直在对应下降的。
这个在大多数的模型训练中已经是被默认选择了,是一个十分有效的策略。
个人经验:
虽然但是,理论是理论,实践是实践。我建议大家一开始使用比较小的学习率比较好,例如5e-5、4e-5 这种。然后看情况看模型效果,慢慢调高或者。特别是小数据集的朋友们,一开始不要用特别大的学习率。例如1e-4、2e-4这种的。总的来说,小一点的学习率确实比较好拟合。也有不错的效果。
第二个:num_train_epochs
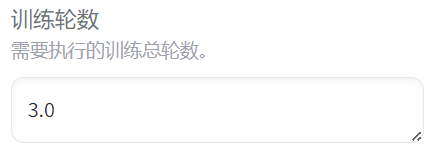
其中这个epoch直译是"轮、周期"的意思。整个 num_train_epochs 的含义就是“训练轮数”
其实指的就是在训练的时候,模型完整的在你的数据集上面完完整整学了一遍的意思。例如1个epoch指的就是模型它在你给它的数据集上训练了一轮。3个epoch就是完整的在数据集里训练了3轮。以此类推。
那我们要怎么判断到底要用多少epoch呢?实际上,这个没有一个固定的值。因为不同的数据最终目标不同、token量不同。模型也不同。这些等等都会有区别。但是。一般来说,数据集越少,所需要的epoch就越多。数据集越多,需要的epoch就越少。
所以我们一般不怎么看epoch。而是看loss的下降。只要保证loss下降到合适的区间,我们甚至可以手动停止训练。如果loss没有下降到合适区间,即便已经练完了,我们可能还是需要增大epoch。所以,epoch只是一个控制模型训练的时长工具。而决定模型最终对象是loss 这里不要搞错了。
个人经验:
一般建议最好控制在10个epoch以内。尽可能在10个epoch里面将模型拟合到0.7~1.4范围的loss中
第三个:cutoff_len
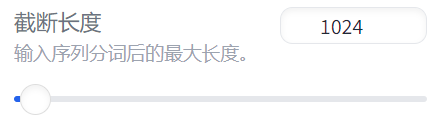
这个cutoff_len正如图片上显示的“截断长度”
顾名思义,意思就是你数据集里面,单条数据内容加起来超过了设定的1024这个长度,就会自动截断。它的单位是token (这个token你可以简单理解为一个汉字的意思)什么意思呢?
例如我说了一段话:
“今天我简单说两句,要说什么呢?其实也没什么,就是简单说一下,主要啊,就是这个啊。怎么说呢。就是懂得人自然懂,不懂的说了也不懂。啥也不说了,干一个!”
假设我把这个cutoff_len设定为10,那么也就是说超过了10个token就会被强行截断。如果你的数据集超过了。可能最终传给模型的就是这样的内容:
“今天我简单说两句,要说”
发现了吗?这段话被直接截断了。最终模型训练的就是这断了的数据。有的时候你发现训练完了,模型好像只说了一半的现象。这个时候建议去看看自己的数据集是否超过了这个截断的长度。是不是这里出的原因。
这个截断的长度可以自行手动调整,但是cutoff_len也直接影响训练的资源。也就是显存的占用,所以这个取决于你的数据集的平均长度。来设置一个合适的截断长度。
个人经验:
可以让chatgpt帮你写一个脚本计算数据集里面的平均每条的token量从而来设置截断长度。
第四个:per_device_train_batch_size
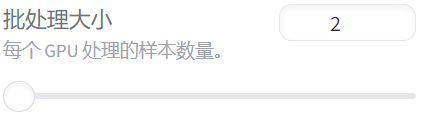
这个就是批处理大小,意思就是在训练过程中,每个设备(你的GPU)一次处理的样本数量。如果你有一块GPU,batch_size调到16 那么就意味着你一块GPU一次处理16个样本(这里的样本指的就是你一条数据集)
同理,2块GPU batch_size16,每块GPU处理8个样本。
那么这个具体大了小了对模型有什么影响吗?那是必然的。
首先大的batch_sizer让GPU每次需要处理的样本更多,从而需要更多的显存资源。此外,泛化能力可能会略差,因为更新次数减少,模型可能容易过拟合。当然,好处也是有的,就是训练更为的稳定,从而更容易找到全局最优解。可以更快的收敛模型。
总结batch_size大的特点:
1.训练过程更稳定。容易找到全局最优解
2.通常能更快地收敛到一个较好的解。
3.需要更多的GPU内存。
4.泛化能力可能略差,因为更新次数减少,模型容易过拟合
那batch_size小了会怎么样呢?就是上面的反过来的意思,训练过程可能不稳定,容易陷入局部最优解。好处是因为每次GPU处理的样本很少,所以gpu显存占用很低。其次更容易学习到数据集里面的细节特征。其次泛化能力更好,因为噪声更大,有助于跳出局部最优,找到全局最优。
总结batch_size小的特点:
1.训练过程可能更不稳定。
2.可能更容易学习到数据的细节特征。
3.适合显卡显存受限的情况。
4.泛化能力可能更好,因为噪声更大,有助于逃离局部最优。
最后,要说的就是一般来说,调大batch_size的时候,也要相应的调大学习率。调小batch_size的时候,也得相应的调小学习率。至于为什么要这样?因为解释起来相当的麻烦,绝对不是我不会讲。
简单来说,大batch_size搭配上大学习率意味着就像是在大晴天找公交站,很远就能看见。所以可以放心的大步往前走。
小batch_size搭配上小学习率意味着雾霾天找公交站。你很难看清,所以只能用很小的步子慢慢走。
这个比喻我自己都不是很懂,只能说懂的都懂。
反正只要记住大batch_size大,学习率也得调大,反之亦然。
个人经验:
一般来说,小模型,例如10b以下的模型,我建议batch_size调小一些比较好,其次如果你的数据集很少,那batch_size还调的很大的话,特别容易严重过拟合。导致效果很差。小batch_size的拟合效果其实是不错的。这里建议从batch_size调到2开始,甚至可以从1开始。
第五个:gradient_accumulation_steps
梯度累积步数(gradient_accumulation_steps)是啥?
简单来说这是一个小技巧,让你在显存不够的情况下,也能用上大批处理大小(batch size)。
举个例子
你的显存最大只能处理4个样本一次,也就是说 batch size = 4。
你想要的效果是处理8个样本一次,但直接设置 batch size = 8 会爆显存。
怎么办呢?用梯度累积!
梯度累积步数(gradient_accumulation_steps):设置为 2。
它怎么工作?
第一步:处理4个样本,计算梯度,但不更新模型参数。
第二步:再处理4个样本,计算梯度,和第一步的梯度加在一起。
更新参数:现在你有了8个样本的梯度,合并后一次性更新模型参数。
最后的效果
就像你一次处理了8个样本(大批处理大小),但实际上每次只用4个样本的显存。
就像分期付款一样,让你显存不够也能享受大批处理的效果。
第六个:loraplus_lr_ratio
这个是今年出来的一个新的训练算法,旨在传统lora训练方式下。
lora+提高了性能(1% ‑ 2% 的改进)和微调速度(高达 ~ 2 倍加速),而计算成本与 LoRA 相同。
具体的就不展开说了,只知道它可以大幅缩短模型所训练的时间,同样的步数下拟合的会更加的快。我建议可以设置为8或者16。
至于为什么不展开说是因为我还没看完它的论文,所以就不献丑乱说了。只是基于个人经验来推荐一下。
这里我就介绍这6个参数了,基本上这6个是我平时调整的最为频繁的。其实还有很多重要的参数可以讲,但是我感觉每一个都讲的话可能会过于的无聊,不知道这种枯燥的参数讲解会不会有人看。而且我也怕大家睡着了。
实际上不同的参数互相搭配会有很神奇的效果,不同模型下不同的调参也会截然不同。我觉得这也是一个比较有趣的特点。
下期可能会介绍一下如何训练出一个AI客服,目前已经做到下图水平


你可能会问我为什么要打码?因为模型每一次说出的地址和信息都是正确的。我也没有想到换了一种训练方式会对模型产生这么好的影响。目前很少看到有人做AI客服是用训练的方法的。
实际上是可以的,只不过非常难,要对数据集每一个的比例分的特别平均,且关键信息数量要足够。不然会导致训练不充分导致没效果。还有模型的参数搭配也很关键。最后不停的测试训练,找出模型说错的内容然后去修饰、增加\减少数据集,弥补这一部分的错误。最后做到近乎找不出错误的效果。这就是一个完整的AI客服训练了。和传统的模型依靠RAG检索知识库最大的区别就是模型能够模仿带入角色,用训练人的语气性格来和你对话,这种感觉很奇妙。在测试好几次中我都认为它是一个真的人,而不是AI。所以心里话会吐露的比较多。
这个具体的AI客服实现流程我可能会做成视频或者写成文章,具体看时间是否充裕。可能会在下一期或者更久以后。

















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









