






问题引出, 为什么要内存TRAINING?
因为DDR 3/4/5 采用了FLY BY 连线方式,控制信号,命令信号还有时钟到达DIMM 端的时间不一样,TRAINING 就是为了将这些信号对齐。
内存从上电到下电会经过哪些过程:
答: 初始化--> 校准--> 训练--> (刷新/读/写)--> 下电
初始化过程
内存控制器DDR 芯片上电--> 复位DDR4 芯片--> 时钟稳定CKE 使能--> MRS 寄存器模式配置
校准过程
DDR4 芯片端ZQ 校准--> 内存控制器VrefDQ 训练
训练过程
写入均衡 write leveling-->门控训练 Gate training--> 读数据去偏斜 read De skew--> 写数据去偏斜write de skew--> 写DQS 延迟训练
--> 读DQS 延迟训练 Read Eye Centering
到这个时候, DDR4 就已经基本Ready. 就可以进行正常的读写操作了。
刷新 /读操作 写操作 ----> 下电
后面,我们就对上面提到的各个过程进行详细的解读。
写入均衡(Write leveling)
有书的同学打开 4.21.1 Write Leveling Training Mode.
没书的同学,私信我,我发给你,18.88 一份。
包含两本( JEDEC SPEC + MEMORY SYSTEM Cache, DRADM, Disk).
Write leveling 是对fly by 布线的一种时序补偿。 要说清楚这个,先要了解信号分类。
DDR 信号分地址,数据,控制等等大类,但是,按照布线方式,可以分为两个大类。一个DDR 控制器,往往会接很多DDR 芯片。按照布线来说,一大类就是点对点信号。 比如数据信号DQ, 以及DQS, 在同一个RANK 里面,控制器到芯片都是一一对应的。那相对的, 另一大类,就是共有信号。 比如时钟,地址和命令信号。 这些信号都是一对多连接的。 于是,对于这些信号就有了两种布线方式。
第一种就是T 型布线, 就是将时钟,地址,命令 以T 字型,保证控制器到DDR 芯片的距离都是一样的。
第二种, 就是FLY BY, FLY BY 就是将时钟,地址,命令,依次经过DDR3. 连接沿路的DDR 芯片, 只留下很小的STUB, 减小反射。并且在终端做了匹配, 尽可能的改善信号质量。
这是非常推荐的布线方式。 但是会存在一点点问题。 由于这些共有信号,都是沿路供给DDR芯片。 也就意味着,控制器到各个芯片的距离都不相同。 比如控制器发出的时钟CK 信号到达各个芯片的延时会有差别。 而一对一信号,比如,数据DQ ,它们都是等长的。 对于一对一信号,控制器到各个芯片的延时都是一样的。
于是,共有信号和一对一信号,在各个芯片上面,就有了不同步的现象。

什么叫FLY BY, 上图:
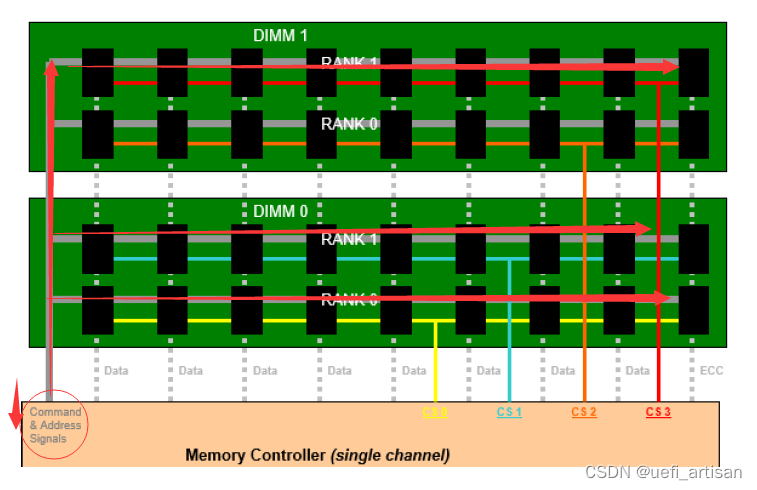
从图中,可以看出, 控制信号, 地址信号用一根线将所有的内存芯片串起来了, 很明显信号到达每个DIMM 的时间就会不一样,因为线长不一样。 另外,可以看出来,DATA 信号的数据线,是一样长的。
即然发现了问题,解决起来,就方便了,毕竟我们永远不缺解决问题的人,而是总缺发现问题的人。
问题解决:继续打开书:
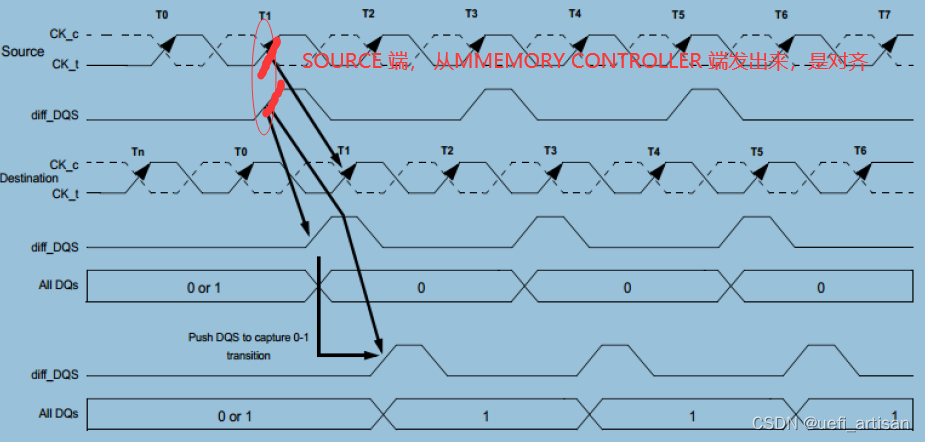
从这张图可以看出, 信号从MEMORY CONTROLLER 发出的时候,是对齐的。
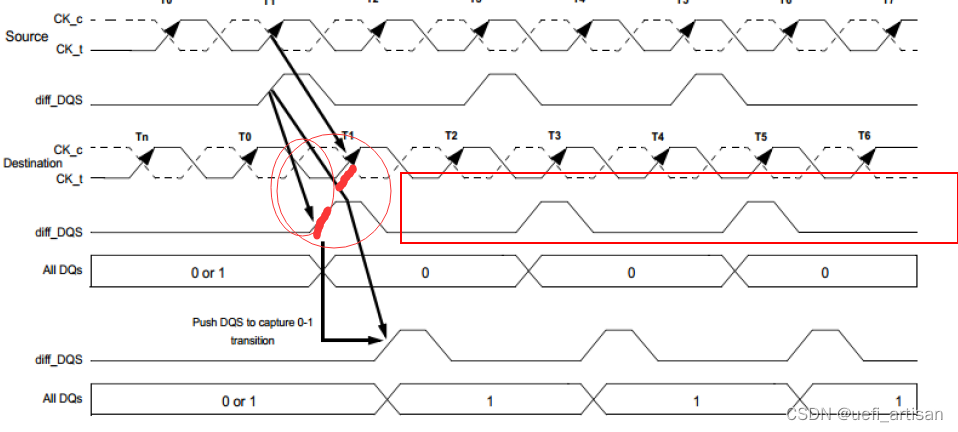
到了DIMM 端,两边对不齐了,本来DIFF_DQS 应该是在正下方的。TRAINING 就是为了解决这个问题。
移动 DQS 去采样CLOCK, 就是对CLOCK 进行画像, 比如一个CLOCK 采样128 次, 每一个间隔叫一个PI(Phase Interpolator)。这样就能知道CLOCK 长什么样子了。
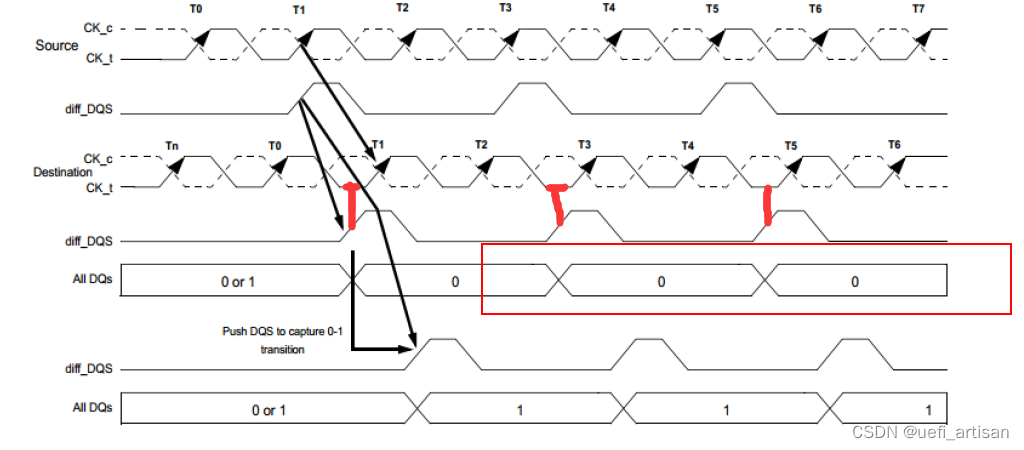
从上图可以看到, CLOCK 都是0, 0 OR 1 也就是说,之前是啥不用管,统计后面的就可以了。
然后, 挪动一个或多个PI, 再次对CLOCK 进行采样。
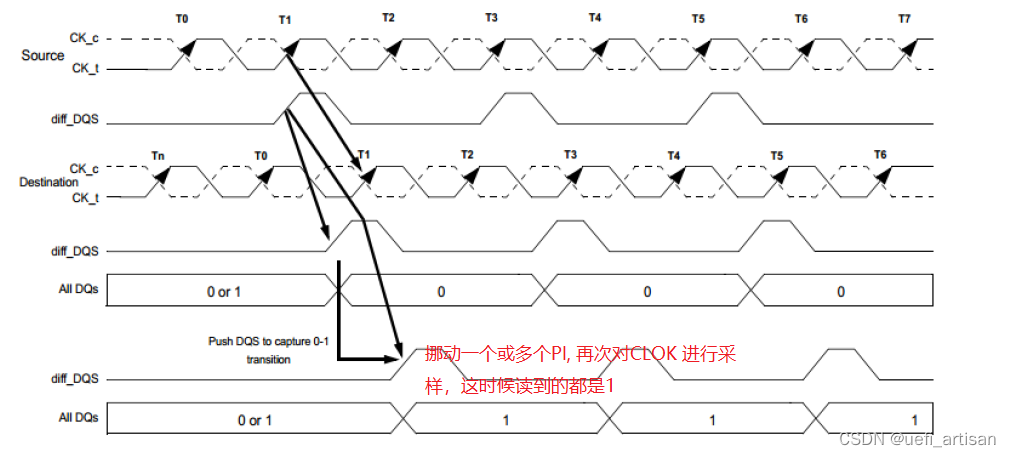
有了对CLOCK 的画像,我们就能调整DQS 的延时, 以达到我们的目的,也就是让DQS 和CLOCK 对齐。
具体的步骤,可以分为以下四步:
按时间T1, T2, T3, T4:
T1: 使能 ODT
T2: DDR 控制器发送DQS 信号, DDR芯片在DQS 上升沿采样CK 信号, 发现CK = 0, 则DQ 保持为0.
T3: DDR 控制器加入延时后发送DQS 信号, DDR 芯片在DQS上升沿采样CK 信号, 发现CK=0, 则DQ 仍然保持为0
T4: DDR 控制器继续加入延时后发送DQS 信号, DDR 芯片在DQS上升沿采样CK 信号, 发现CK=1, 则等待一段时间后, DDR 芯片将DQ 信号置高。
就是用这种方法对每个DDR 芯片做写入均衡。这样对于每个芯片,看到的时钟和DQS 就椒对齐的。
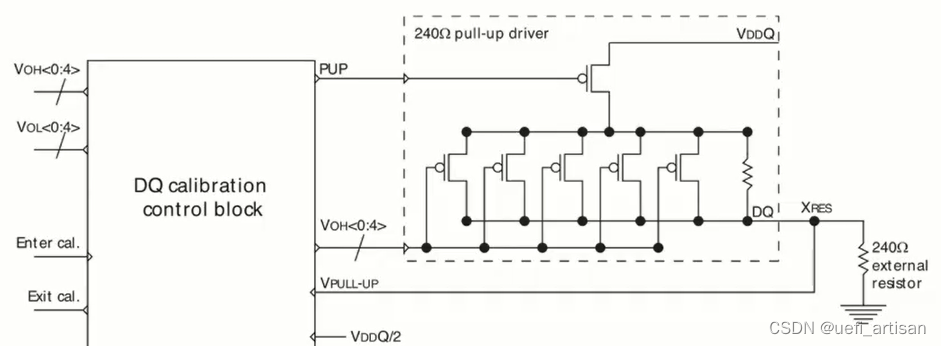
ZQ 校准
DQ 数据线上每个240 欧姆上拉电阻 要略大于240 欧姆,并联上多个可开关大电阻
ZQ 校准时,将上拉电阻和外部精确ZQ电阻连接成戴维南分压, 调整VOH 并联大电阻的数量,让
分压电平等于VDDQ/2, 存下VOH 值作为校准结果。校准结束后, 校准值传到所有DQ 引脚
DDR 基他训练
门控训练 Gate training
调整内存控制器侧 门选通时间,让内存控制器能精确获得从DDR4 芯片侧送过来的读DQS 信号。
读数据去偏斜 Read De-skew
内存控制器内部对读回的数据各个比特信号加入不同的延迟, 让他们边沿对齐。
写数据去偏斜 Write De-skew
内存控制器内部对写出的数据各个比特信号加入不同的延时,让其边沿对齐。
读 DQS 延迟训练Read Eye Centering
计算读回的DQ 数据眼图宽度, 对收到的读DQS 信号加入合适延时, 让其边沿处于DQ 数据中心们置, 提高读时序建立保持裕量。
写DQS 延迟训练 Write Eye Centering
计算写出的DQ 数据眼图宽度, 调整发送的DQS 信号时间位置,让其边沿处于DQ 数据中心位置, 提高DDR4 芯片侧建立保持时间裕量。
RECEIVE ENABLE
包含精调和粗调 , Fine 和 Coarse
为了节约能源(电), 只有在DIMM 端向内存控制器发送有效数据的时候,我才开始收数据。
先行知识:
DDR 读操作
读写前寻址操作分为两步:
一个是地址输出部分,第二个是读出数据部分。由于地址分为行地址和列地址,所以地址输出也
分为两步,
看下面真值表,就是CKE 两个时钟周期都为高,CS 和RAS 都是低选通。CAS和WE 都为高。WE 为高,代表读操作。

Bank 地址与相应行地址是同时发出的,此时这个命令称之为“行激活” (ACTIVE),将发送到地址寻址命令与具体的操作命令(是读还是写),这两个命令也是同时发出的,所以一般都会以“READ" 来表示列寻址。
经过列地址选通潜伏期tCL后,数据DQ 以前DQS出现在线路通道中。
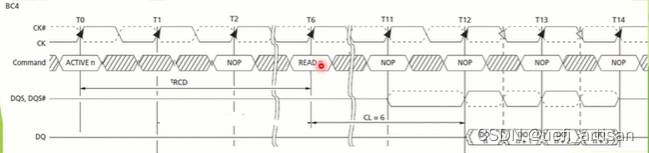
DDR3 预取技术(Pre-Fetch)
核心频率即为内存cell 阵列(即内部电容)的刷新频率,它是内存的真实运行频率
时钟频率即I/O Buffer (输入/输出缓冲)的传输频率
有效数据传输频率就是指数据传送的频率(即等效频率)
DDR 针脚定义
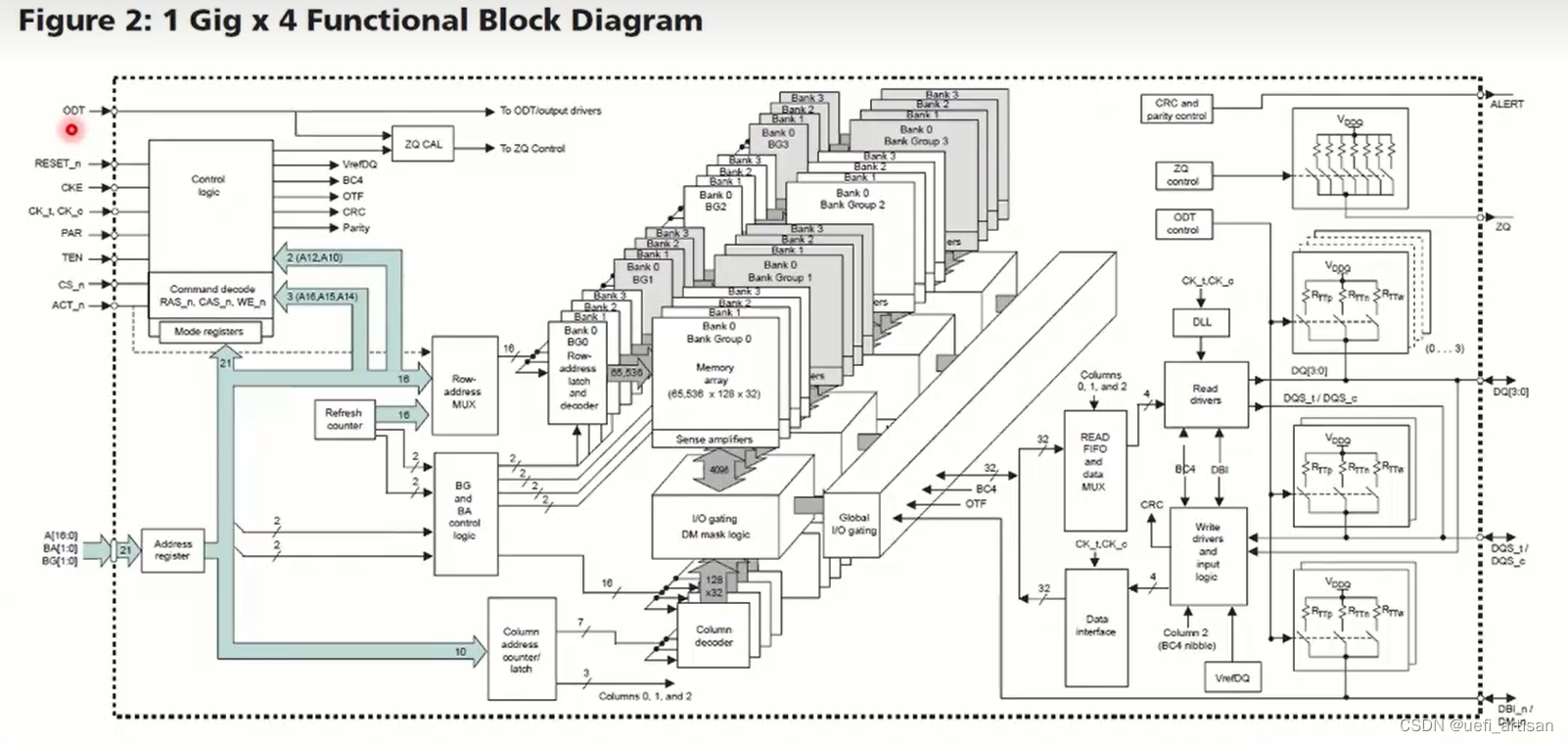
ODT 终端匹配使能引脚,如果在模式寄存器MR中, 当ODT 引脚为高时, 数据线DQ, DQS, DM 等信号,在DDR4内部的RTT 电阻就会生效。
Reset n , CKE 以及CK, 分别是复位信号,时钟使能信号,以及差分时钟输入信号,复位信号是低有效, 也就是拉低了,就是DDR4 芯片置于复位状态, CKE 是高有效, 当CKE 为高时则使能DDR4 内部时钟
TEN: 引导进入测试模式
CS_N ACTIVE_N 是命令信号, 也是为了节约引脚, ACTIVE _N 帮助实现地址复用。
A16 A0 17 根地址线。
两根BANK 地址线, DDR4 使用了BANK GROUP 的概念
ALERT: 用于校验, 校验出错的时候, 就ALERT.
DDR 是如何存储数据的,是使用电容。
我要小额(2元)赞助,鼓励作者写出更好的教程
如果您认为本教程质量不错,读后觉得收获很大,预期工资涨幅能超过30%,不妨小额赞助我一下,让我有动力继续写出高质量的教程。
如果你有微信,请打开微信,使用“扫一扫”付款


















 6026
6026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









