








1 Read DQS Gate Training
读请求时DRAM返回的DQS选通信号一般都会经过PHY内部的一个门控电路,此门控电路可以抑制噪声并选择正确的读数据。针对读数据精确位置是读请求正确完成的先决条件。由于板上的走线延时并不是精确可控的,所以对于门控的训练时必须的。PUB中的门控训练机制可通过配置PIR寄存器触发。门控训练机制可通过一系列的读,并扫过所有有可能的门控位置以找到最合适的门控位置,从而保证读操作的正确性。门控训练的窗口时间可达0~7个CK周期,步长精度可达10-25ps,此数据是通过组合逻辑的流水线与延迟线完成的。读系统延迟的线性搜索使用了半区间搜索方式(二分搜索法)来找到精确位置的。
半区间搜索法克加速训练过程,且所有bytelane都是同时进行的。每个rank则是轮流进行。
搜索算法是从最小延迟开始的,并由两个位置,最左位置与最右位置。最终门控延迟会选择最左位置与最右位置的中间值。此结果可能与实际访问中的最佳位置存在一个或两个精确步长的差别。在某些特殊情况下,若门控信号的轨迹延时足够大到可以满足补偿区间,那么门控训练将不会对DQS进行对称展开。这种情况在使用门控训练扩大(extension)时也会出现,门控训练扩大是通过DSGCR.DQSGX来开启的。
测试序列中包含了DQS门控训练,在防止读错误是非常重要的。唯一可能使完成门控训练的读操作错误的原因是,每个读操作之间的DQS jitter非常大。为了缓解这种状态,门控训练的读操作会被重复很多次,其中一次读错误操作都不能出现。DTCR.DTRPTN可配置每一次门控训练时重复的读操作次数。为了更长远的提高门控训练的可靠性,读返回数据会根据返回数据计数来与期望的读数据进行比较,来确定读操作是否正确。DTCR.DTCMPD控制。
在DDR2模式中,训练使用的数据是DTDR0-1中由用户定义的。而在DDR3中,在进行了Write Leveling 的之后,初始化DQS的门控训练必须使用MPR寄存器内的数据。但是,通过配置DTCR.DTMPR 可使DDR3模式下仍然使用用户定义的数据进行比较。在写操作已经完成训练之后,这种方在重新训练时非常有用的。
在DX BIST loopback模式下,门控训练在默认状态下是打开的。但是,如果有需要仍然可以通过PGCR.LBGDQS来触发训练。也就意味着,在BIST过程中也可对门控训练进行测试。由于Loopback的路径要比实际功能模式下的读请求要短得多,所以BIST模式下的门控位置与实际功能模式下的门控位置会有比较大的区别。值得注意的是,BIST过程中仅对一个rank进行训练,并将结果使用于所有的rank上。并且,在BIST中仅发送写命令,因为loopback返回的写数据将作为读数据被接收。DQS门控最大的可调整范围是6个时钟周期。
2 算法
如上文描述的,DQS门控是从最左边的位置扫到最右边的位置,直到读传输第一次正确。首先确定最左的正确位置,然后确定最右的正确位置,从而得到一个读操作稳定正确的有效位置。最小的延迟位置对应门控关闭,最大的延迟位置对应门控打开。这两个位置的中间为最后的门控位置,此位置与上述两个位置的距离都是相等的。门控的延时是通过DXnGTR.RmDGSL与DXnLCDLR2.RmDQSGD来进行控制的。
为了找到最左的有效位置,门控信号以PHY SDR 时钟的1/8延迟作为步长,通过自增延迟的方式来找到第一次读正确的位置。门控时钟的位置是由当前位置与下一步位置共同限制,并慢慢固定的。同时通过一个二进制算法来加速此进程。以上两种方式组成了最左有效位置与门控关闭位置。
一旦门控关闭位置找到了,门控信号将以PHY SDR时钟的1/4周期作为步长,从二进制空间最右的位置进行搜索。此步可有效减少jitter对对稳定性的影响。
门控信号以PHY SDR时钟的1/8周期为步长,以自增延迟的方式进行搜索,直到找到第一个读请求错误的位置,作为最右位置。在此之后,门控时钟的位置是由当前位置与下一步位置共同限制,并慢慢固定。向之前一样,同时通过一个二进制算法来加速此进程。以上两种方式组成了最右有效位置与门控打开位置。
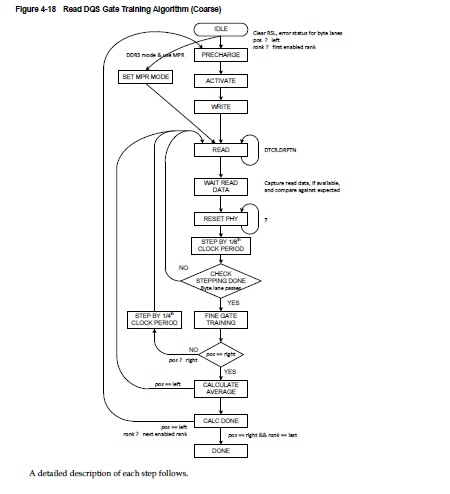
- IDLE:静止状态,在收到触发信号之前,读系统延迟与所有bytelane的LCDL都处于清零状态,且此时处于error状态。触发门控训练之后就会开始搜索最左位置与门控关闭位置。
- PRECHARGE:对所有bank进行预充电。
- SET MPR MODE:在DDR3模式中,如果MPR模式被使能了,那么就需要将DRAM配置成MPR使能。
- ACTIVATE:激活指定的bank与row
- WRITE:如果DDR3-MPR模式没有开启,或者当前模式为DDR2模式,对指定地址的写操作BL都为BL8.
- READ:向指定的地址发送指定数量的读请求。对读返回数据与期望数据进行追踪并对比。
- WAIT READ DATA:若得带数据返回的时间超过24+读系统延迟,那么就可以将此读请求定位成错误请求。以防门控信号将读数据削减或门控信号位置错误导致读数据没有返回,以上都会导致读请求数据返回超时。
- STEP BY 1/8th CLOCK PERIOD:在门控训练中,在调整门控信号延时的时间单位都是1/8个时钟周期。
- CHECK STEPPING DONE:在搜索最左位置与最右位置时,都仅找到一个粗略的延时。后续会进行一个精确的门控训练算法,来重新精细化门控信号的位置。如果,此时读请求错误了,那么此步骤后将重新跳回READ。
- FINE GATE TRAINING:等待门控训练的结果。如果结果为成功,即找到最右位置或门控打开位置,则开始计算此rank的精细化门控位置。若结果不正确,则跳回READ步骤,重新计算最右位置。
- STRP BY 1/4th CLOCK PERIOD:在找到门控最左边的位置后,以1/4时钟周期为延时增量,来找到门控关闭位置,以防止潜在的读不稳定所带来的风险。
- CALCULATE AVERAGE:在找到最左位置与最右位置后,PUB会将两个位置的LCDL与RSL延迟的差值除以2,并将此结果加到最左位置的基础上,作为门控训练的最终结果。若没有其他的rank需要进行训练,则训练完成。
- CALC DONE:检查是否所有的rank都得到了最终的门控训练结果。若没有则训练下一个rank
- DONE:对所有BANK进行预充电操作,使状态回到IDLE。
注意DQS门控时钟周期是由DXnGSR0.GDQSPRD来确定的,而不是LCDL的最大值来确定的。延迟计算也是基于这个周期值。
精细门控算法的大纲如下图所示。它采取了二分搜索法来确定读DQS的门控位置。通过粗略的算法确定了门控信号的大概位置,此位置位于正确的读请求与错误的读请求之间。当搜索最左位置的时候,读请求的正确性随着门控延迟的增加是由错误转变为正确。当正确位置出现时,PUB就会将此位置记录为最左的有效DQS门控位置,也就是门控延迟的最低要求。当搜索最右有效位的时候,读请求的正确性随着延迟增加是由正确转变成错误的,这与最左位置恰好是相反的。当读请求开始出现错误的时候,PUB会将此位置记录为最右有效位。
在二分搜索法中,有三个基本点:最左、最右以及终点。在经过一系列的读请求之后,PUB根据读请求的正确性以及读操作返回的数据正确性来对延迟参数进行更新。例如,在搜索最左有效位置的时候,若当前的读请求错误了,那么下一次读请求的延迟位置就是当前指针与最右指针的中点,且此时最左的指针也会指向当且指针的位置。相反的,如果当前指针的读请求正确了,那么下一次读的位置将会是当前指针与最左指针的中点,且此时的最右指针将会是当前指针的位置。当指针的位置已经非常接近,且没有更多的空间来进行更加精细的调整,那么次算法就完成了,同时指针的位置也就确定了。
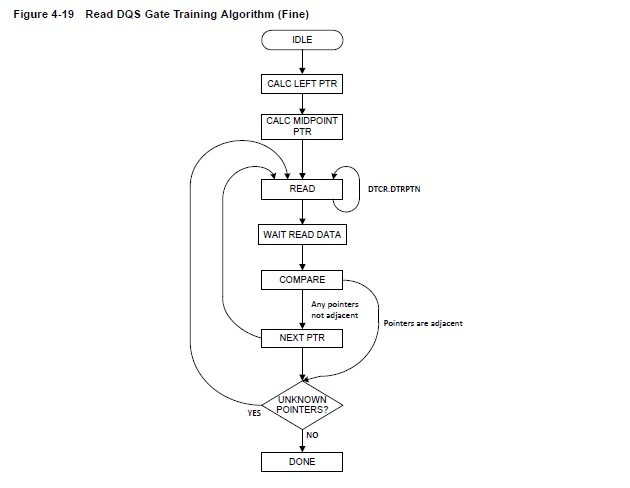
详细的步骤描述:
1. IDLE:静止状态。当接收到开始信号时,所有bytelane的LCDL值都将进行清零,且所有指针的正确、错误状态都将回到初始状态。
2. READ:向指定的地址发送指定数量的读请求。对读返回数据与期望数据进行追踪并对比。
3. WAIT READ DATA:若得带数据返回的时间超过24+读系统延迟,那么就可以将此读请求定位成错误请求。以防门控信号将读数据削减或门控信号位置错误导致读数据没有返回,以上都会导致读请求数据返回超时。
4. 当得到比较数据的结果时,所有bytelane的此步骤结束时都会得到一个正确或失败的结果。
5. COMPARE:每次读返回结果时更新状态指针。
6. PHY此时会进行一次高速复位,此复位信号至少持续7个周期。以保证PHY内所有的逻辑与数据都已经清除,且不会对后续的读操作造成影响。
7. NEXT PTR:若指针相互之间已经非常靠近,且互相之间的空间已经几乎没有,则此算法完成,反之,则重新回到READ步骤
8. UNKNOWN POINTERS:处于这个状态时,二分搜索法就已经结束了。如果任何一个指针存在不确定的状态,则重新回到READ步骤,以找回丢失的信息。否则,基于指针的状态,以及最左最右位置是否已经重新细化,可确定将最左或最右指针作为最后的结果。
9. DONE:将控制权交回粗放门控算法的FSM。
在门控训练结束后,门控信号应该覆盖在读数据上,且两边各留1/4个DDR时钟周期的余量,不过这取决于LCDL的步长。
3 在门控训练中插入刷新命令
门控训练的算法支持在训练过程中插入DRAM的刷新命令。一般来说,根据需要刷新命令可以被插在以下几个位置:一系列的读请求发送完成之后、延迟增加以及完成之后、延迟计算完成之后。
PGCR2.tREFPRD是用来定义刷新周期,DDTCR.RFSHDT是用来定义在一个刷新周期内共插入多少个刷新命令。















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









