






一篇CLIP应用在语义分割上的论文
论文标题:
Extract Free Dense Labels from CLIP
作者信息:

代码地址:
https://github.com/chongzhou96/MaskCLIP
Abstract:
许多论文研究了CLIP在图像分类的表现,作者提出了采用CLIP去处理像素型密集任务,如图像分割,作者提出了MaskCLIP和MaskCLIP+均取得了很好的效果。
Introduction
(作者认为CLIP模型有处理密集型预测任务的潜力,具有以下优势:)
1.能够学习一些局部的语义特征(从NLP中)。
2.能够学习一些开放的词汇的概念。
3.能够捕获丰富的上下文本信息。
(作者的尝试和经验)
1.不要打破CLIP中固有的visual-language association。作者早期将CLIP中的img encode单独拿出用于初始化如deeplab的backbone并Fine tune。使CLIP的泛化能力降低。
2.不要对CLIP中的text encode做太多改变,会使CLIP丢失对unseen物体的分割能力。
(作者的贡献和模型的效果)
1.作者提出了MaskCLIP模型:从CLIP中的 Img encode获得patch-level图像特征,从text encode直接获得像素预测的权重,而没有采用有意的映射。
(另一篇论文有些类似:也取消了采用GAP生成CAM,而是改用1×1的卷积直出)
2.提出两种refine技术:key smoothing 和prompt denoising。
2.提出了MaskCLIP+,利用MaskCLIP对unseen的物体生成伪标签,然后进行训练。
Methodology
下图为模型的整体概略图

3.1 Preliminary on CLIP
(作者简单介绍了下CLIP模型)
3.2 Conventional Fine-Tuning Hinders Zero-Shot Ability
(对于分割问题的范式)1.初始化在Image net上预训练的backbone,2.添加专用于分割模块(随机初始化权重)3.fine tune backbone,增添新的模块。
(作者仿照这样的思路)首先,用image encoder of CLIP替换ImageNet预训练的backbone(deeplab)。然后,使用映射器将CLIP中的text decoder权重的映射给模型(deeplab)分类层权重,用公式表达如下:
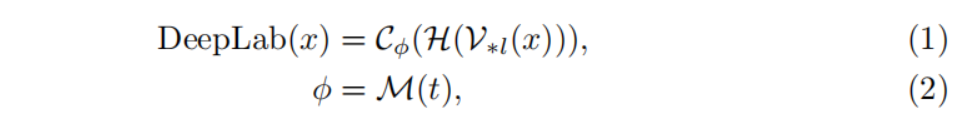
这样效果不好,尤其是对unseen物体的zero-shot分割上面无法取得满意的分割性能。作者认为可能出了这些问题:
1.CLIP中的img encode和常规网络的backbone应该有区别。
2.img encoder的权重在训练以及fine tune中被重新更新。
3.text encoder的映射器仅仅只在新的数据上进行训练,因此泛化性不够。
3.3 MaskCLIP
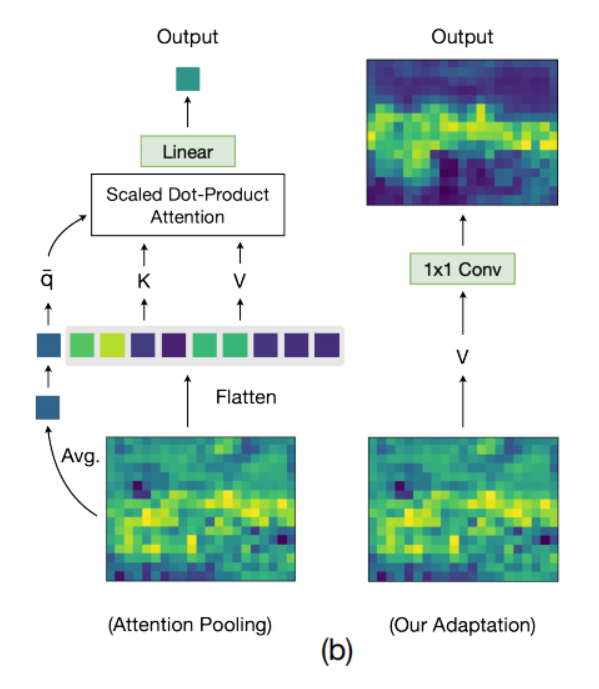
(上图是MaskCLIP种的核心做法,把CLIP 中以Transfomer为基的encoder给换成的右侧的1×1卷积)
原本CLIP中的方法用公式表示如下:
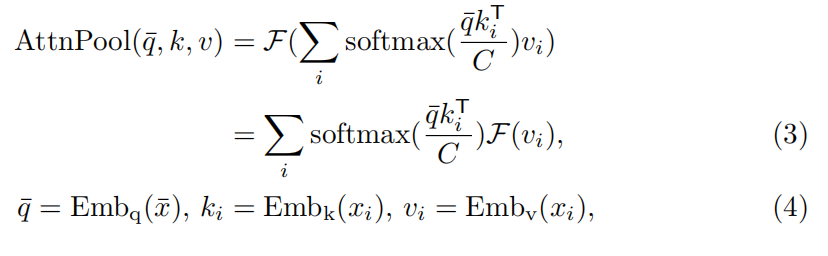
作者认为这里Transformer的输出可以作为整体文本的一个较好的representation。是由于这些计算的
F
(
v
i
)
F(v_i)
F(vi)已经捕获了丰富的局部语义响应,这些响应与CLIP的文本嵌入中的标记很好地对应。(不太能理解,参考:https://zhuanlan.zhihu.com/p/562819258)
基于这样的假设,作者进行了一些改进:
(1)丢弃了
q
q
q和
k
k
k,仅保留嵌入的
v
v
v
(2)将
v
v
v和最后一层线性层直接输入到1×1卷积中
同时不改变text encode,直接和目标prompt后,作为输入,每个类的结果文本嵌入被用作分类器。
(这里估计不太好理解,作者做了进一步的讨论,总的来说就是扔掉了
q
‾
\overline{q}
q使用了
v
v
v)
1.原CLIP中用的是
q
‾
\overline{q}
q作为分类型任务,叫global query,它是由一个特殊的[CLS]产生的。
而这里作者采用的是每个patch下的token的[CLS],即
v
v
v作为密集型任务预测。
1.或者从另一个角度看:q,k,v中的v和attention层的输出是差不多的,只是多了一个q和k相互dot后的系数,所以这里用attention的输出或者v进一步往下做都是可以的(作者代码中也给了接口)
(作者的原文是这么说的)
讨论了 ViT中Transformer层和 global attention pooling的不同:
(1) the global query is generated by a special [CLS] token instead of the average among all spatial locations;
(2)Transformer layer has a residual connection.
Key Smoothing and Prompt Denoising.
(两种refine手段,文章里面说得很简略,都没看懂)
Key Smoothing:
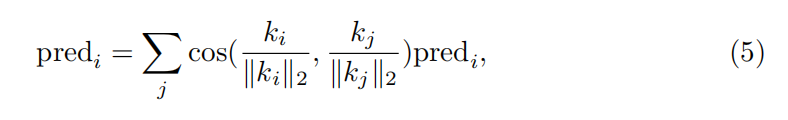
Prompt Denoising:
如果目标类在所有空间位置的类置信度都小于阈值t = 0.5,则删除具有目标类的Prompt。
3.4 MaskCLIP+
将相同的预处理图像输入提供给MaskCLIP,并使用MaskCLIP的预测作为伪地真标签来训练目标网络。
也可以用于zero-shot分割任务,使用MaskCLIP生成unseen的物体的伪标签,然后进行训练。
Self-Training:
训练到一部分发现MaskCLIP得为标签已经无法达到进一步提升性能得要求,于是用MaskCLIP+得训练结果进一步训练自己。
(知识蒸馏)
Experiments
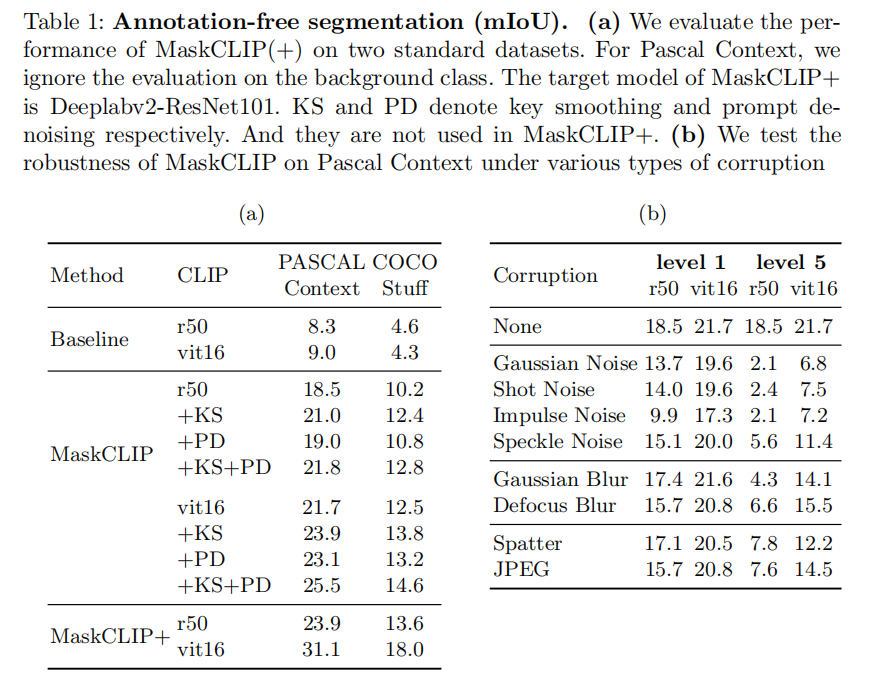
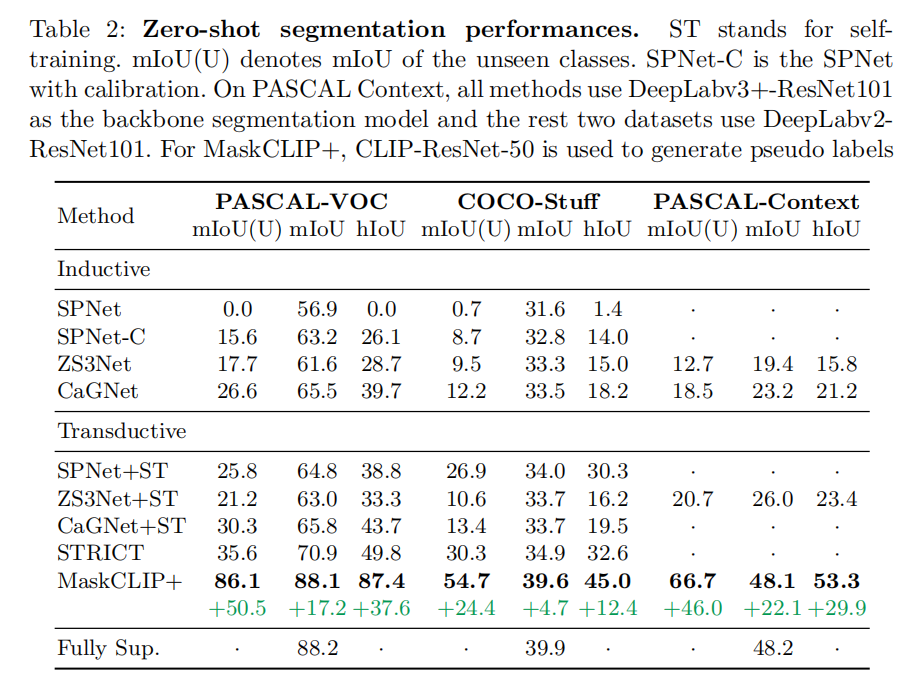















 2130
2130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









