






- ——如何为生成式AI构筑“防火墙”与“红绿灯”
一、当大模型落地时,我们在担忧什么?
2023年,某金融公司上线智能客服,因未过滤用户隐私数据,导致信用卡号泄露;某医疗AI在诊断建议中生成错误药物剂量,引发监管审查……大模型在释放巨大商业价值的同时,安全与合规问题已成悬顶之剑。
核心痛点直击:
-
黑盒失控:生成内容不可预测,传统规则引擎失效
-
数据深渊:训练数据含敏感信息,清洗难度指数级上升
-
合规迷宫:全球AI监管框架快速迭代(欧盟AI法案、中国《生成式AI服务管理暂行办法》)
-
对抗升级:黑客利用Prompt注入绕过安全限制
二、大模型安全测试四重防线
1. 数据层:从源头建立“净化车间”
1.1.敏感数据扫描:
1.1.1工具:Microsoft Presidio(识别PII) + 自定义正则规则库
PII:在信息安全领域指“个人身份信息”
Presidio 是微软开源的一个SDK,支持针对特定业务需求的可扩展性和可定制性,允许组织通过民主化去识别技术和引入决策透明度,以更简单的方式保护隐私,它有两个主要部分——分析器Analyzer和匿名器Anonymizer,分析器Analyzer是一种基于Python的服务,用于检测文本中的PII实体。它利用命名实体识别、正则表达式、基于规则的逻辑和校验和多种语言的相关上下文。例如,它使用预定义的基于Regex模式的电子邮件和IP地址识别器,以及SpaCy自然语言处理模型来构建命名实体的识别器。
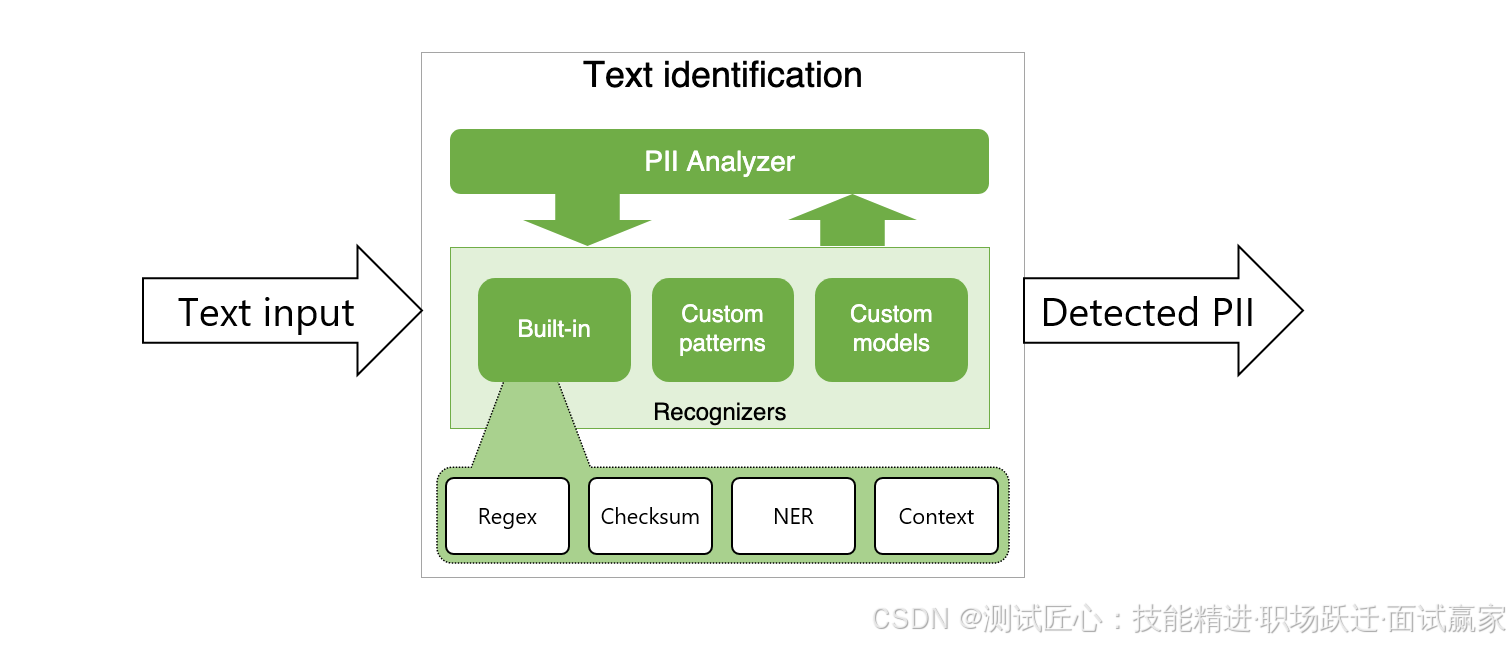 分析器Analyzer内部工作流程
分析器Analyzer内部工作流程
匿名器Anonymizer也是一个基于python的服务。它通过应用某些运算符(如替换、掩码和密文),将检测到的PII实体匿名化为所需值。默认情况下,它直接在文本中用其实体类型(如<EMAIL>或<PHONE_NUMBER>)替换检测PII。但人们可以自定义它,为不同类型的实体提供不同的匿名逻辑。
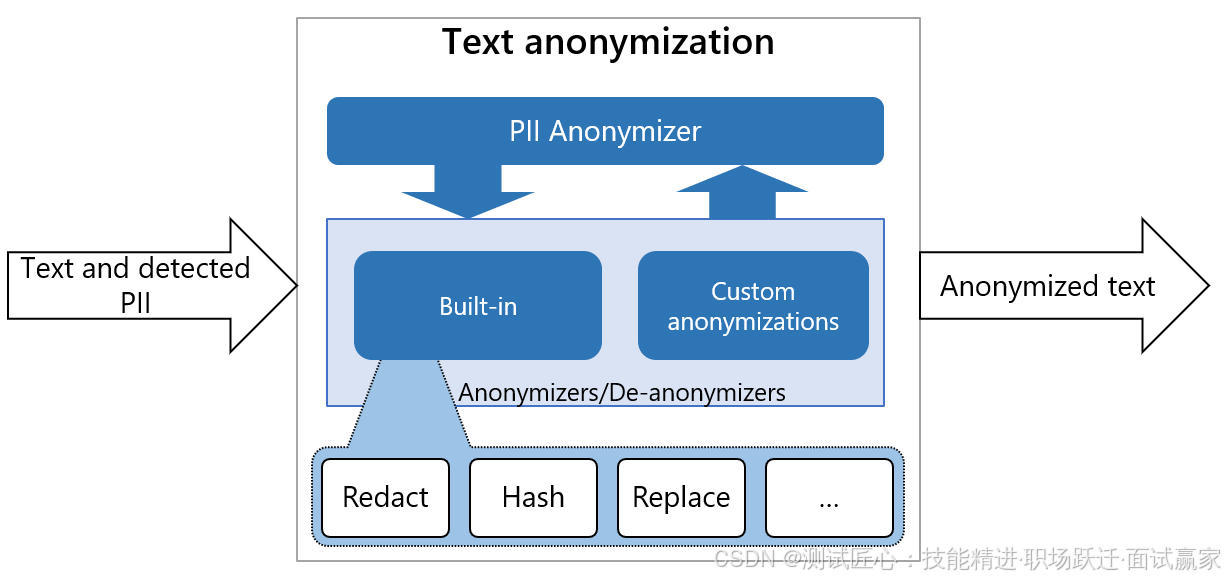
匿名器Anonymizer内部工作流程
在实际工作中,我们可以将通过分析器Analyzer得到的PII信息,再通过匿名器Anonymizer,转成普通文本,如下:
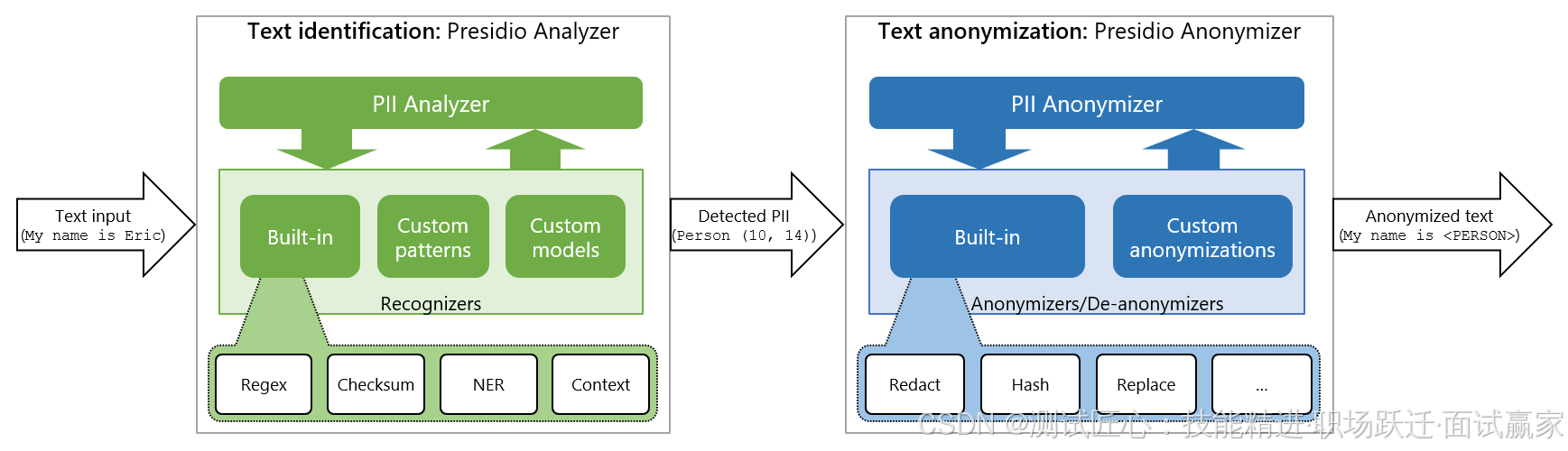
分析器Analyzer和匿名器Anonymizer搭配使用流程
参考文档: 官网:Home - Microsoft Presidio 官网主要提供的是英文的使用手册,如果阅读英文有障碍的话,可以看这个博主整理的中文教程。【数据保护】微软开源数据保护项目Presidio-从入门到精通-CSDN博客
1.1.2 案例:某电商评论生成模型,自动屏蔽手机号
presidio默认使用的是spaCy作为自然语言处理库,spaCy是一个基于Python编写的开源自然语言处理库。它专为生产环境设计,提供了先进的NLP功能,包括文本预处理、文本解析、命名实体识别、词性标注、句法分析和文本分类等任务。spaCy的设计目标是高性能、易于使用和可扩展性,内置了多种预训练模型,可用于处理多种语言,如英语、法语、德语、中文等。
1.1.2.1安装Presidio
pip install presidio-analyzer
pip install presidio-anonymizer
python -m spacy download en_core_web_lg1.1.2.2.进行评论信息的Analyze + Anonymize
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
text="My phone number is 212-555-5555"
# Set up the engine, loads the NLP module (spaCy model by default)
# and other PII recognizers
analyzer = AnalyzerEngine()
# Call analyzer to get results
results = analyzer.analyze(text=text,
entities=["PHONE_NUMBER"],
language='en')
print(results)
# Analyzer results are passed to the AnonymizerEngine for anonymization
anonymizer = AnonymizerEngine()
anonymized_text = anonymizer.anonymize(text=text,analyzer_results=results)
print(anonymized_text)1.2.偏见量化工程:
1.2.1 工具:Fairlearn
消除数据的偏见,可以使用Fairlearn ,Fairlearn是一个开源的项目,旨在帮助数据科学家提高人工智能系统的公平性。
官网:Fairlearn
Fairlearn 主要功能:
- 公平性评估:Fairlearn提供了多个公平性指标,用于评估机器学习模型对不同人群的影响,如真阳性率、假阳性率、选择率等。通过这些指标,数据科学家可以了解模型是否对某些群体存在偏见。
- 公平性改进:Fairlearn提供了不公平缓解算法,帮助数据科学家改进模型的公平性。这些算法可以作为任何标准分类或回归算法的“包装器”,通过转换模型的预测或重新训练模型来减轻不公平现象。
- 交互式可视化仪表板:Fairlearn还包含一个交互式可视化仪表板,帮助用户评估模型可能对哪些人群产生负面影响,并比较多个模型在公平性和性能方面的表现。
1.2.2 案例:使用Fairlearn评估性别偏见
# 使用Fairlearn评估性别偏见
from fairlearn.metrics import demographic_parity_difference
disparity = demographic_parity_difference(y_true, y_pred, sensitive_features=gender) 1.3.数据血缘追踪:
1.3.1.工具:
1.DVC
DVC(Data Version Control)是一个开源的数据科学版本控制系统,专为机器学习和数据分析项目设计。它通过利用Git的灵活性,将数据文件和实验版本化,解决了数据追踪、复现性和协作中的难题。DVC支持云存储集成,如Amazon S3和Google Cloud Storage,以实现高效的数据共享和备份
DVC的主要功能和特点
- 版本控制:DVC支持对数据集和模型进行版本控制,确保数据的可追溯性和可复现性。通过将数据文件和模型作为独立的实体进行跟踪,DVC简化了数据科学工作流程。
- 高效处理大数据:DVC特别设计用于处理大数据文件和机器学习模型,这些文件通常太大而无法有效地使用传统的版本控制系统如Git进行管理。DVC通过将数据和模型作为独立的实体进行跟踪,允许用户在不同的实验之间共享和复现数据。
- 团队合作与复现性:DVC支持定义数据处理管道,团队成员可以轻松获取最新数据及处理步骤,保证实验的一致性和可复现性。
- 云存储集成:DVC支持云存储集成,如Amazon S3、Google Cloud Storage等,以实现高效的数据共享和备份。
DVC的使用方法
安装DVC:首先确保安装了Git,然后在命令行中执行pip install dvc来安装DVC。
初始化项目:在数据科学项目目录下执行dvc init,这将在项目根目录创建.dvc文件夹,标志着项目已准备好使用DVC。
添加数据到DVC:使用dvc add data.csv将数据文件纳入版本控制,然后提交到Git。
配置远程存储:通过dvc remote add -d myremote https://my云端存储路径配置远程存储,并使用dvc push将数据推送到远程存储。
官网:Home | Data Version Control · DVC
2. MLflow
在机器学习和数据科学项目中,跟踪数据变更的历史非常重要,以确保模型的训练和验证过程是可追溯和可解释的。MLflow 是一个开源平台,用于管理机器学习生命周期,包括实验跟踪、模型管理和部署。虽然 MLflow 本身不直接提供数据版本控制的功能,但它提供了强大的工具来记录和管理与数据相关的元数据和实验配置,这对于追踪数据变更历史至关重要。
官网:MLflow: A Tool for Managing the Machine Learning Lifecycle
1.3.2.实践:
可以采用DVC标记数据版本, MLflow记录数据变更历史。
1.使用 MLflow 的 Experiments 和 Runs
MLflow 通过 Experiments 和 Runs 来组织和管理实验。你可以在每次数据变更后启动一个新的 run,并记录相关的数据集信息。
import mlflow
import mlflow.sklearn
# 启动一个新的 MLflow run
with mlflow.start_run():
# 记录数据集信息
mlflow.log_param("dataset_version", "v2")
mlflow.log_param("data_change_description", "Added new feature and cleaned missing values")
# 你的数据加载和处理代码
data = load_and_process_data("path_to_new_data.csv")
# 记录数据集的元数据或摘要信息
mlflow.log_artifact("path_to_new_data.csv")
# 训练模型并记录模型
model = train_model(data)
mlflow.sklearn.log_model(model, "model")2.使用 MLflow 的 Artifacts
MLflow 的 Artifacts 功能允许你存储和追踪数据文件。每次数据变更时,你可以将新的数据集作为 artifact 存储,并在 run 中记录相关信息。
import mlflow
with mlflow.start_run():
# 记录数据集信息
mlflow.log_param("dataset_version", "v2")
mlflow.log_param("data_change_description", "Added new feature and cleaned missing values")
# 将数据集作为 artifact 存储
mlflow.log_artifact("path_to_new_data.csv")
# 你的数据处理和模型训练代码
data = load_and_process_data("path_to_new_data.csv")
model = train_model(data)
# 记录模型
mlflow.sklearn.log_model(model, "model")三、合规测试实战:穿透法律迷雾
1. 全球合规地图
| 地区 | 核心要求 | 测试重点 |
|---|---|---|
| 欧盟 | AI法案高风险分类 | 透明性/可解释性验证 |
| 中国 | 《生成式AI服务管理办法》 | 内容黑名单过滤效率测试 |
| 美国 | NIST AI RMF框架 | 风险分级管控机制验证 |
2. 可解释性测试工具箱
-
LIME:局部特征重要性可视化
-
import lime explainer = lime.LimeTextExplainer() exp = explainer.explain_instance(text, model.predict_proba) exp.show_in_notebook()
四、未来战场:AI安全测试新范式
-
AI检测AI:用GPT-4作为安全审计员,扫描百万级生成内容
-
合规即代码:将法律条款转化为自动化测试用例(如GDPR第17条→数据删除接口测试)
-
安全众测平台:邀请白帽子通过Bug Bounty挖掘模型漏洞
五、写在最后
大模型安全与合规测试不是简单的“规则列表”,而是一场需要持续迭代的攻防战争。建议采取“三层防御”策略:
-
预防:在训练阶段植入安全基因
-
检测:部署阶段建立实时哨兵
-
响应:完善事件应急机制
只有将安全视为产品核心特性而非附加功能,才能让大模型真正通过“社会考卷”。

















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









