







聚类分析 研究对样品或指标分类问题的一种多元统计方法.
根据一批样品的许多观测指标,按照一定的数学公式具体地计算一些样品或一些参数(指标)的相似程度,把相似的样品或指标归为一类。
本文将通过梳理聚类分析全过程,展现如何实现该分析及其原理。
一、对初始数据变换处理--(较详细原理介绍,实践中推荐正向化标准化即可)
(可用spss得到数据均值、标准差)
根据数据特性以及接下来可能进行的操作,有三种变换,可以帮助处理数据:
1.中心化变换:--(方便计算方差、协方差、期望)
中心化变换是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化后的数据。
设原始观测数据矩阵为:
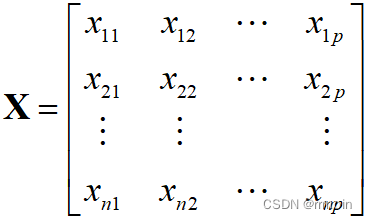
进行中心化变换:![]() ,
,![]() ;
;
特点:每列数据之和均为0,即每个变量的均值为0.
每列数据的平方和是该列变量样本方差的(n—1)倍.
任何不同两列数据之积是这两列变量样本协方差的(n—1)倍.
2.标准化变换:--(方便计算相关系数矩阵、可以消除数据量纲)
在中心化变换基础上,用变量的标准差进行标准化。
标准差 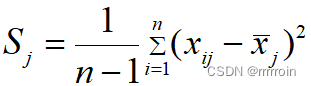
标准化 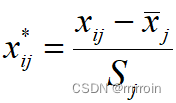 ,
, ![]() ;
;
特点:
数据矩阵中每列数据的平均值为0,方差为1.
数据不再具有量纲,便于不同变量之间的比较.
数据矩阵中任何两列数据之积是两个变量相关系数的(n-1)倍.
*3.对数变换:--(将指数结构化成线性结构)
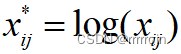
二、选取聚类变量
选取的原则:(1)与聚类分析的目的密切相关(2)能反映所分类变量的特征(3)对不同研究对象其值有明显的差异 (4)变量之间不能高度相关
主要分为两个指标:相关系数(多用于考察变量之间亲疏程度)、距离(多用于测度样品之间的亲疏程度。)
1.相关系数:
①相关系数:
相关系数计算公式:
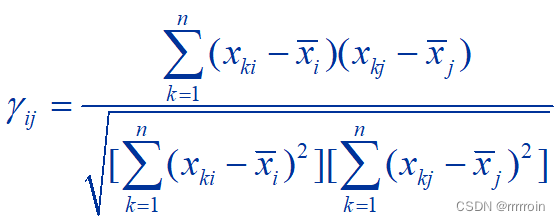
②夹角余弦:从向量集合的角度所定义的一种测度变量之间亲疏程度的相似系数。
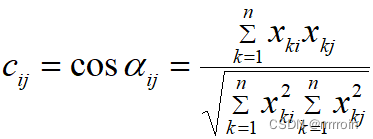
2.距离:有四种类型选择:
1.明考夫斯基距离:
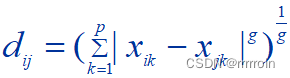 ,(欧几里得距离是其情形之一)
,(欧几里得距离是其情形之一)
明氏距离主要缺点: ①明氏距离的值与各指标的量纲有关.②明氏距离没有考虑各变量之间的相关性,没有考虑变量方差的不同.
2.兰氏距离:
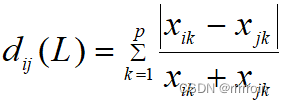 ,
,
特点:对大的奇异值不敏感,使它特别适合于高度偏倚的数据。不考虑变量相关性。
3.马氏距离(又称广义欧氏距离)
![]() ,
,
( 表示观测变量之间的协方差短阵。若总体协方差矩阵未知,可用样本协方差矩阵作为估计代替计算。)
特点:不受量纲的影响,考虑了观测变量之间的相关性。也考虑到了各个观测指标取值的差异程度。
4.斜交空间距离:(变量存在相关关系,不相关用欧氏距离即可)
由于各变量之间往往存在着不同的相关关系,用正交空间的距离来计算样本间的距离易变形,所以可以采用斜交空间距离。
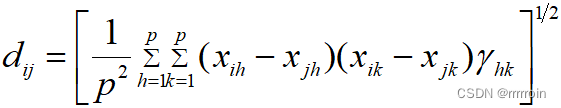
三、确定形成类数
一是根据题目要求或生活常识,进行一个大致的类数确定;或者是用算法聚类,根据距离、密度分出大致的类别。
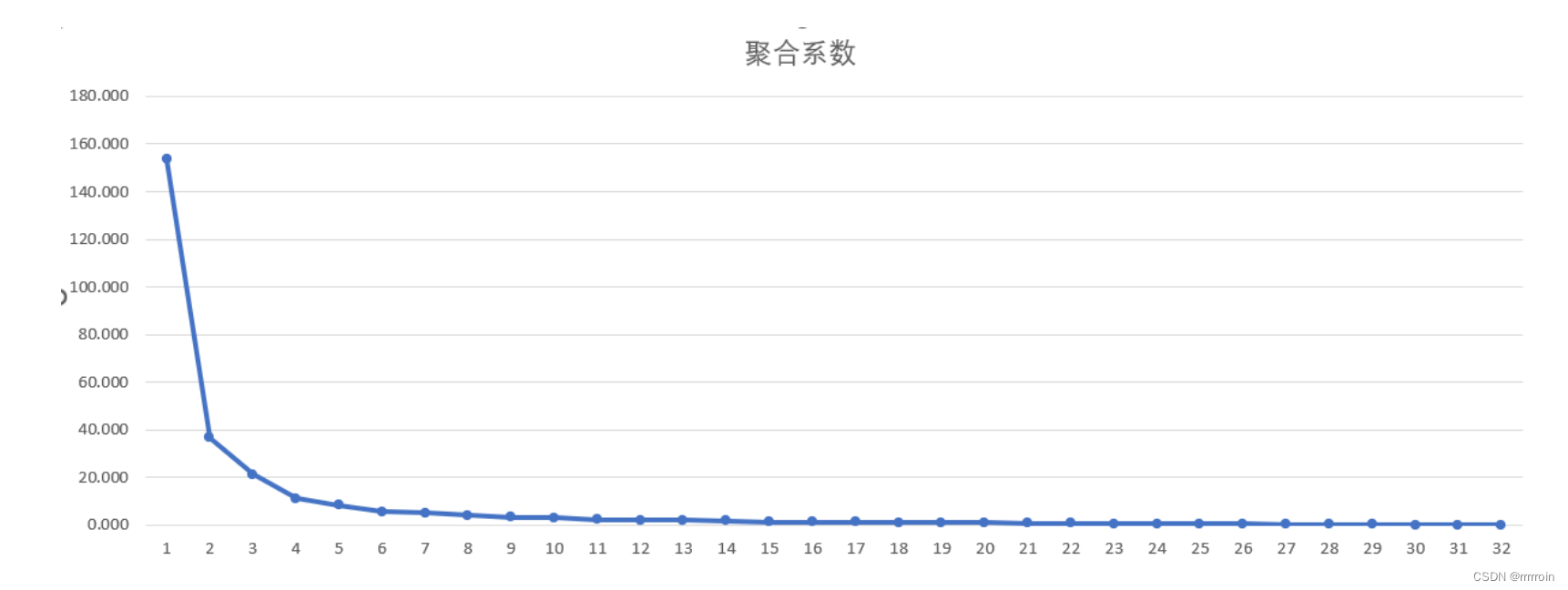
或者是通过计算得出:通过画出聚合系数曲线,找到合适的k值。(肘部法则)
如下:

当曲线突然变缓时,是对应取得的效果较好的K值。效果如下图,应选取4或者5.
四、选择聚类方法
1.系统聚类法:
基本思想:
(1)列出距离矩阵D(0)。
(2)选择最小的非零数,不妨假设为 ,于是将
和
合并为一类,记为
.
(3)给出计算新类与其它类的距离公式,并计算新类与其它类之间的距离Dkr .分别删除D(0)表的第p,q行和第p,q列,并新增一行和一列对应于Dr .得到新矩阵记为D(1).
(4)再次重复23步,直至所有样本点归为一类。
按照不同的方法定义距离,得到不同的聚类方法:
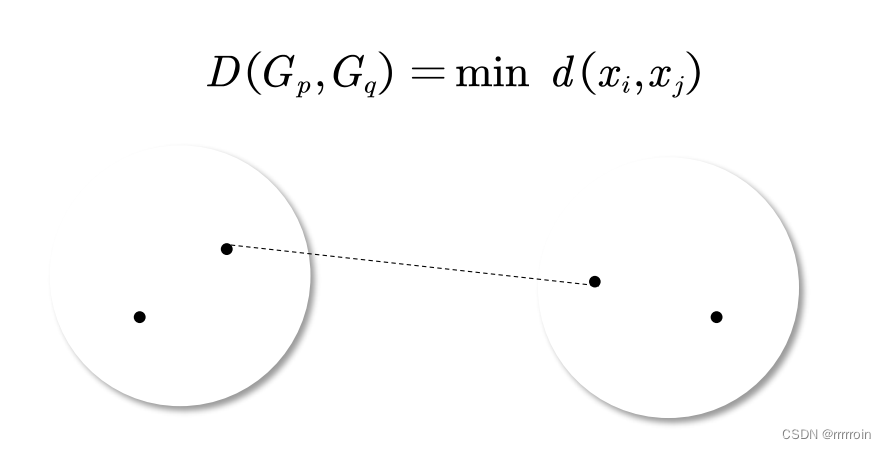
①最短距离法(常用):
②最长距离法:
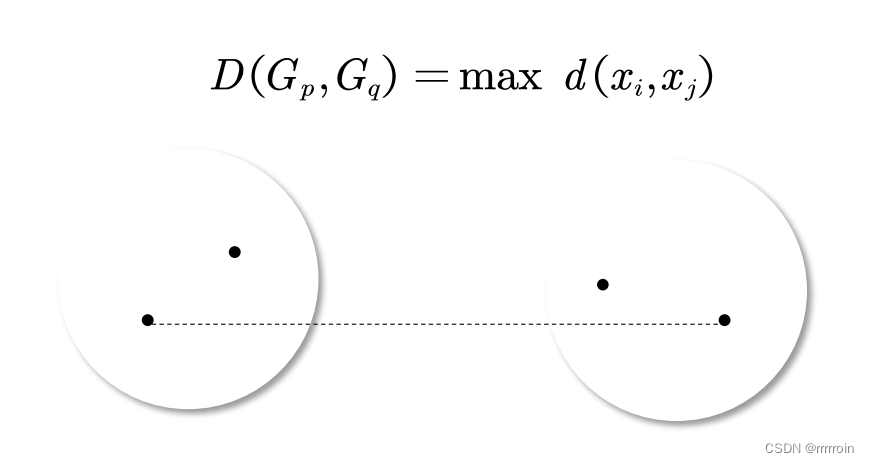
③组间平均距离法:
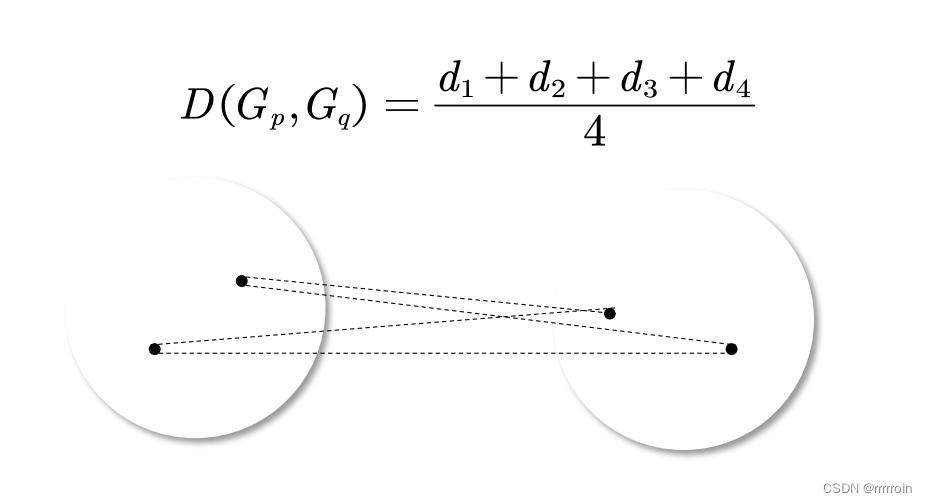
④重心法:
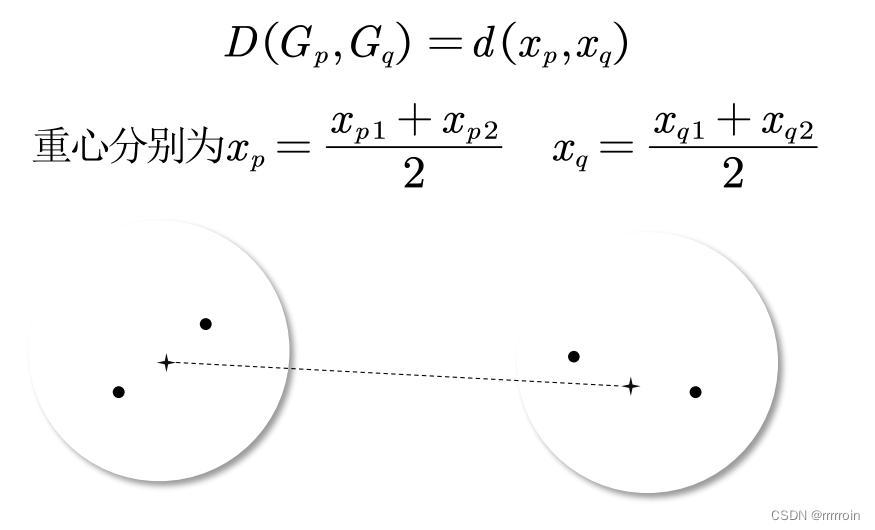
⑤类平均法:
类平均法定义类间的距离是两类样品两两之间平方距离的平均.
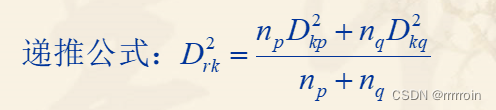
例:G1对G3距离为6.25,G2对G3距离为2.25;G1、G2合并后,新类G‘对G3距离为(6.25+2.25)/ 2;
最终结果应呈现为:
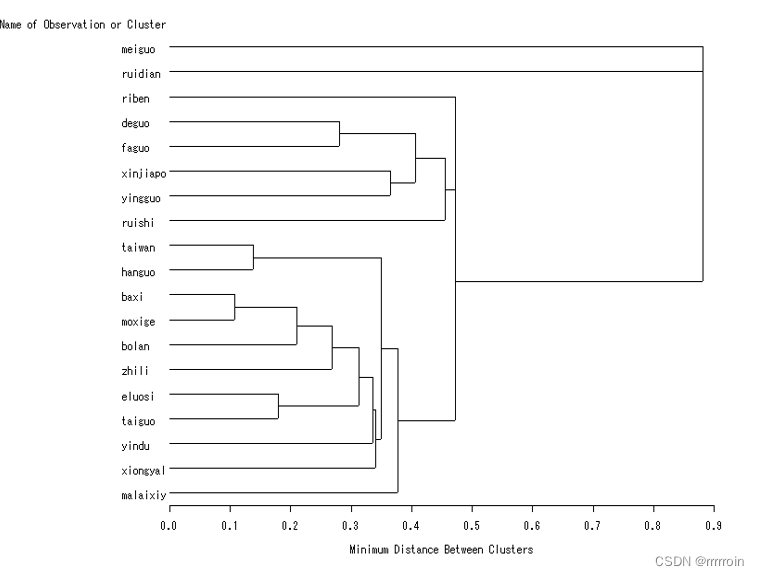
缺点:样本点数量庞大时,计算量大,且聚类的计算速度也比较慢.
具体代码呈现可参考:数学建模之聚类分析_最短距离法聚类分析例题-CSDN博客
2.kmeans聚类算法:
原理:

Kmeans算法是一种动态迭代的算法。
缺点:由于初始聚类中心是随机选取的,聚类结果会受孤立、离群点影响,甚至因此产生偏差。
3.kmeans++算法:(对kmeans算法的改进)
对kmans算法进行改进,其思想为:让初始的聚类中心之间距离尽可能的远,从而减少初值与孤立点的影响。而通过改变概率权重:样本点与当前已有聚类间最短距离越大、被选取为下一个聚类中心的概率越大。从而实现让聚类中心更加科学合理的目标。

算法及详细原理可参考:机器学习 K-Means(++)算法_kmeans++-CSDN博客
4.DBSCAN算法:
原理:一种基于密度的聚类方法,聚类前不需要预先指定聚类的个数,生成的簇的个数不定。
该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象 (点或其他空间对象) 的数目不小于某一给定闯值。该方法能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据。
用几何的观念直观理解DBSCAN密度算法:

下为DBSCAN算法参考代码:
function [IDX, isnoise]=DBSCAN(X,epsilon,MinPts)
C=0;
n=size(X,1);
IDX=zeros(n,1);
D=pdist2(X,X);
visited=false(n,1);
isnoise=false(n,1);
for i=1:n
if ~visited(i)
visited(i)=true;
Neighbors=RegionQuery(i);
if numel(Neighbors)<MinPts
% X(i,:) is NOISE
isnoise(i)=true;
else
C=C+1;
ExpandCluster(i,Neighbors,C);
end
end
end
function ExpandCluster(i,Neighbors,C)
IDX(i)=C;
k = 1;
while true
j = Neighbors(k);
if ~visited(j)
visited(j)=true;
Neighbors2=RegionQuery(j);
if numel(Neighbors2)>=MinPts
Neighbors=[Neighbors Neighbors2]; %#ok
end
end
if IDX(j)==0
IDX(j)=C;
end
k = k + 1;
if k > numel(Neighbors)
break;
end
end
end
function Neighbors=RegionQuery(i)
Neighbors=find(D(i,:)<=epsilon);
end
end5.ISODATA算法:
原理:通过迭代获得较为理想的分类成果,找到合适的K值。可以自己设置初始参数,是一种非监督机器学习方法。
ISODATA算法通过设置初始参数而引入人机对话环节,并使用归并和分裂等机制。当两类聚中心小于某个阀值时,将它们合并为一类。
当某类的标准差大于某一阀值时或其样本数目超过某一阀值时,将其分裂为两类,在某类样本数目小于某一阀值时,将其取消。这样根据初始类聚中心和设定的类别数目等参数迭代,最终得到一个比较理想的分类结果。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









