







- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
一、前期工作
1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True)
tf.config.set_visible_devices([gpus[0]],"GPU")
print(gpus)
输出
[PhysicalDevice(name=‘/physical_device:GPU:0’, device_type=‘GPU’)]
2.导入数据
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import os,PIL,pathlib
#隐藏警告
import warnings
warnings.filterwarnings('ignore')
data_dir = "./P8/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
输出
图片总数为: 3400
二、数据预处理
1.加载数据
batch_size = 8
img_height = 224
img_width = 224
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
输出
Found 3400 files belonging to 2 classes.
Using 2720 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
输出
Found 3400 files belonging to 2 classes.
Using 680 files for validation.
class_names = train_ds.class_names
print(class_names)
输出
[‘cat’, ‘dog’]
2.再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
输出
(8, 224, 224, 3)
(8,)
3.配置数据集
代码知识点
tf.data.AUTOTUNE是一个特殊的值,用于在TensorFlow中自动调整数据集的并行处理参数。- 定义了
preprocess_image函数,它接受两个参数:image和label。这个函数的作用是将输入的图像进行归一化处理,即将像素值除以255,使得像素值的范围在0到1之间。同时,函数返回一个元组,包含归一化后的图像和对应的标签。- 分别对训练集(train_ds)和验证集(val_ds)进行映射操作。映射操作使用
preprocess_image函数对每个元素进行处理,并使用num_parallel_calls=AUTOTUNE参数来指定并行调用的数量。这样可以在多个CPU核心上并行处理数据,提高数据处理速度。- 最后两行代码对训练集和验证集进行了缓存、随机打乱和预取操作。缓存操作将数据集存储在内存中,以便快速访问;随机打乱操作将数据集中的样本随机排列;预取操作则在数据读取时提前加载一部分数据到内存中,以便后续操作能够更快地获取数据。这些操作可以提高数据处理的效率。
AUTOTUNE = tf.data.experimental.AUTOTUNE
def preprocess_image(image,label):
return (image/255.0,label)
# 归一化处理
train_ds = train_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(preprocess_image, num_parallel_calls=AUTOTUNE)
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
4.可视化数据
plt.figure(figsize=(15, 10)) # 图形的宽为15高为10
for images, labels in train_ds.take(1):
for i in range(8):
ax = plt.subplot(5, 8, i + 1)
plt.imshow(images[i])
plt.title(class_names[labels[i]])
plt.axis("off")
输出

三、构建VGG网络
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 1st block
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 2nd block
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 3rd block
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 4th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 5th block
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# full connection
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
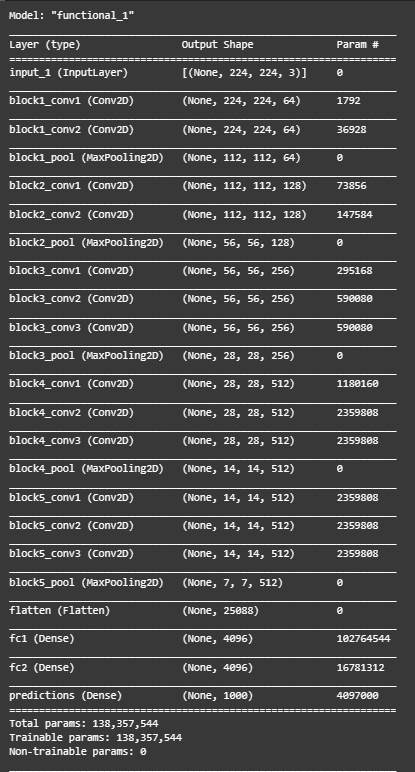
model=VGG16(1000, (img_width, img_height, 3))
model.summary()
输出
四、编译
model.compile(optimizer="adam",
loss ='sparse_categorical_crossentropy',
metrics =['accuracy'])
五、训练模型
代码知识点
tqdm模块是python进度条库def init(
self, iterable=None, desc=None, total=None, leave=False, file=sys.stderr, ncols=None, mininterval=0.1, maxinterval=10.0, miniters=None, ascii=None, disable=False, unit='it', unit_scale=False, dynamic_ncols=False, smoothing=0.3, nested=False, bar_format=None, initial=0, gui=False):
iterable:可迭代的对象, 在手动更新时不需要进行设置
desc:字符串, 左边进度条描述文字
total:总的项目数
leave:bool值, 迭代完成后是否保留进度条
file:输出指向位置, 默认是终端, 一般不需要设置
ncols:调整进度条宽度, 默认是根据环境自动调节长度, 如果设置为0, 就没有进度条, 只有输出的信息
unit:描述处理项目的文字, 默认是’it’, 例如: 100 it/s, 处理照片的话设置为’img’ ,则为 100 img/sunit_scale:自动根据国际标准进行项目处理速度单位的换算, 例如 100000 it/s >> 100k it/s
代码示例
import time
from tqdm import tqdm
def action():
time.sleep(0.5)
with tqdm(total=5000, desc='test', leave=True, ncols=100, unit='B', unit_scale=True) as pbar:
for i in range(10):
# sleep 0.5秒
action()
# 更新sleep进度
pbar.update(500)
test: 100%|██████████████████████████████████████████████████████| 5.00k/5.00k [00:05<00:00, 998B/s]
代码知识点
model.train_on_batch()函数是Keras库中的一个函数,用于在单个批次的数据上训练模型。这个函数的主要作用是在给定的输入数据和对应的目标数据上,使用模型的优化器进行一次前向传播和反向传播,从而更新模型的权重。函数参数详解:
x:输入数据,通常是一个numpy数组或者一个列表,其形状为(batch_size,
input_dim),其中batch_size表示批次大小,input_dim表示输入数据的维度。
y:目标数据,通常是一个numpy数组或者一个列表,其形状为(batch_size,
output_dim),其中output_dim表示输出数据的维度。
sample_weight:可选参数,用于指定每个样本的权重。如果提供了这个参数,那么在计算损失时会考虑这个权重。
class_weight:可选参数,用于指定每个类别的权重。如果提供了这个参数,那么在计算损失时会考虑这个权重。
reset_metrics:可选参数,布尔值。如果设置为True,那么在每次调用train_on_batch()时,都会重置模型的评估指标。默认值为False。
return_dict:可选参数,布尔值。如果设置为True,那么返回的结果将是一个字典,包含每个评估指标的值;如果设置为False,那么返回的结果将是一个列表,包含每个评估指标的值。默认值为False。
epoch:可选参数,整数。表示当前的训练轮次。这个参数主要用于在多轮训练中跟踪训练进度。
validation_data:可选参数,用于提供验证数据。这个参数可以是一个元组,包含输入数据和目标数据;也可以是一个列表,包含输入数据和目标数据的列表;还可以是一个字典,包含输入数据和目标数据的字典。
validation_split:可选参数,浮点数。表示从训练数据中划分出多少比例的数据作为验证数据。这个参数可以与validation_data一起使用。
validation_steps:可选参数,整数。表示在验证过程中使用的步数。这个参数可以与validation_data一起使用。
代码知识点
tensorflow.keras.backend是Keras的后端API,提供了许多用于张量计算的函数,例如:
tf.keras.backend.abs(x):返回张量x中每个元素的绝对值。
tf.keras.backend.add(x,y):返回张量x和y的元素级和。
tf.keras.backend.all(x):返回张量x中所有元素的按位与。
…………
tensorflow.keras.backend.set_value()函数用于设置张量中指定位置的值。它接受三个参数:
x:要修改的张量。
indices:一个包含要修改的元素的索引的元组或列表。
value:要设置的新值。
这是没有找到问题的代码和结果
from tqdm import tqdm
import tensorflow.keras.backend as K
epochs = 10
lr = 1e-4
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):
train_total = len(train_ds)
val_total = len(val_ds)
with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:
lr = lr*0.92
K.set_value(model.optimizer.lr, lr)
for image,label in train_ds:
history = model.train_on_batch(image,label)
train_loss = history[0]
train_accuracy = history[1]
pbar.set_postfix({"loss": "%.4f"%train_loss,
"accuracy":"%.4f"%train_accuracy,
"lr": K.get_value(model.optimizer.lr)})
pbar.update(1)
history_train_loss.append(train_loss)
history_train_accuracy.append(train_accuracy)
print('开始验证!')
with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:
for image,label in val_ds:
history = model.test_on_batch(image,label)
val_loss = history[0]
val_accuracy = history[1]
pbar.set_postfix({"loss": "%.4f"%val_loss,
"accuracy":"%.4f"%val_accuracy})
pbar.update(1)
history_val_loss.append(val_loss)
history_val_accuracy.append(val_accuracy)
print('结束验证!')
print("验证loss为:%.4f"%val_loss)
print("验证准确率为:%.4f"%val_accuracy)
输出
Epoch 1/10: 100%|██████████| 86/86 [00:36<00:00, 2.37it/s, loss=0.6846, accuracy=0.5312, lr=9.2e-5]
开始验证!
Epoch 1/10: 100%|█████████████████████| 22/22 [00:02<00:00, 8.28it/s, loss=0.6876, accuracy=0.6250]
结束验证!
验证loss为:0.6876
验证准确率为:0.6250
Epoch 2/10: 100%|█████████| 86/86 [00:11<00:00, 7.51it/s, loss=0.5014, accuracy=0.7812, lr=8.46e-5]
开始验证!
Epoch 2/10: 100%|█████████████████████| 22/22 [00:01<00:00, 16.63it/s, loss=0.6224, accuracy=0.6250]
结束验证!
验证loss为:0.6224
验证准确率为:0.6250
Epoch 3/10: 100%|█████████| 86/86 [00:11<00:00, 7.69it/s, loss=0.4724, accuracy=0.7812, lr=7.79e-5]
开始验证!
Epoch 3/10: 100%|█████████████████████| 22/22 [00:01<00:00, 16.81it/s, loss=0.5470, accuracy=0.7500]
结束验证!
验证loss为:0.5470
验证准确率为:0.7500
Epoch 4/10: 100%|█████████| 86/86 [00:11<00:00, 7.77it/s, loss=0.3038, accuracy=0.8750, lr=7.16e-5]
开始验证!
Epoch 4/10: 100%|█████████████████████| 22/22 [00:01<00:00, 17.43it/s, loss=0.0449, accuracy=1.0000]
结束验证!
验证loss为:0.0449
验证准确率为:1.0000
Epoch 5/10: 100%|█████████| 86/86 [00:10<00:00, 7.86it/s, loss=0.0205, accuracy=1.0000, lr=6.59e-5]
开始验证!
Epoch 5/10: 100%|█████████████████████| 22/22 [00:01<00:00, 18.23it/s, loss=0.2128, accuracy=0.8750]
结束验证!
验证loss为:0.2128
验证准确率为:0.8750
Epoch 6/10: 100%|█████████| 86/86 [00:10<00:00, 7.87it/s, loss=0.0164, accuracy=1.0000, lr=6.06e-5]
开始验证!
Epoch 6/10: 100%|█████████████████████| 22/22 [00:01<00:00, 17.62it/s, loss=0.2016, accuracy=0.8750]
结束验证!
验证loss为:0.2016
验证准确率为:0.8750
Epoch 7/10: 100%|█████████| 86/86 [00:10<00:00, 7.83it/s, loss=0.0332, accuracy=0.9688, lr=5.58e-5]
开始验证!
Epoch 7/10: 100%|█████████████████████| 22/22 [00:01<00:00, 18.18it/s, loss=0.0077, accuracy=1.0000]
结束验证!
验证loss为:0.0077
验证准确率为:1.0000
Epoch 8/10: 100%|█████████| 86/86 [00:10<00:00, 7.85it/s, loss=0.0035, accuracy=1.0000, lr=5.13e-5]
开始验证!
Epoch 8/10: 100%|█████████████████████| 22/22 [00:01<00:00, 17.21it/s, loss=0.0259, accuracy=1.0000]
结束验证!
验证loss为:0.0259
验证准确率为:1.0000
Epoch 9/10: 100%|█████████| 86/86 [00:10<00:00, 7.89it/s, loss=0.0316, accuracy=0.9688, lr=4.72e-5]
开始验证!
Epoch 9/10: 100%|█████████████████████| 22/22 [00:01<00:00, 17.65it/s, loss=0.2478, accuracy=0.8750]
结束验证!
验证loss为:0.2478
验证准确率为:0.8750
Epoch 10/10: 100%|████████| 86/86 [00:11<00:00, 7.81it/s, loss=0.0272, accuracy=0.9688, lr=4.34e-5]
开始验证!
Epoch 10/10: 100%|████████████████████| 22/22 [00:01<00:00, 18.06it/s, loss=0.0961, accuracy=0.8750]
结束验证!
验证loss为:0.0961
验证准确率为:0.8750
教案代码的错误
本周的问题在于找到教案中的一个bug并改正,其实注释就已经给得很明确,在输出时我们是输出的每一个batch的准确率和错误率,并不是数据集全体训练完后的结果,故而会出现结果中准确率一直保持不变的情形。最开始我没有真正理解这个注释,一直以为是陷入局部最优解了,但是经过反复的调参根本就无济于事。还是在很偶然的情况下发现了这个错误,只要将总的准确率平均后输出就没有问题了
这是找到问题并且解决后的代码块和结果
from tqdm import tqdm
import tensorflow.keras.backend as K
import numpy as np
epochs = 10
lr = 1e-4
# 记录训练数据,方便后面的分析
history_train_loss = []
history_train_accuracy = []
history_val_loss = []
history_val_accuracy = []
for epoch in range(epochs):
train_total = len(train_ds)
val_total = len(val_ds)
with tqdm(total=train_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=1,ncols=100) as pbar:
lr = lr*0.92
K.set_value(model.optimizer.lr, lr)
train_loss = []
train_accuracy = []
for image,label in train_ds:
history = model.train_on_batch(image,label)
train_loss.append(history[0])
train_accuracy.append(history[1])
pbar.set_postfix({"train_loss": "%.4f"%history[0],
"train_acc":"%.4f"%history[1],
"lr": K.get_value(model.optimizer.lr)})
pbar.update(1)
history_train_loss.append(np.mean(train_loss))
history_train_accuracy.append(np.mean(train_accuracy))
print('开始验证!')
with tqdm(total=val_total, desc=f'Epoch {epoch + 1}/{epochs}',mininterval=0.3,ncols=100) as pbar:
val_loss = []
val_accuracy = []
for image,label in val_ds:
# 这里生成的是每一个batch的acc与loss
history = model.test_on_batch(image,label)
val_loss.append(history[0])
val_accuracy.append(history[1])
pbar.set_postfix({"val_loss": "%.4f"%history[0],
"val_acc":"%.4f"%history[1]})
pbar.update(1)
history_val_loss.append(np.mean(val_loss))
history_val_accuracy.append(np.mean(val_accuracy))
print('结束验证!')
print("验证loss为:%.4f"%np.mean(val_loss))
print("验证准确率为:%.4f"%np.mean(val_accuracy))
输出
Epoch 1/10: 100%|███| 86/86 [00:11<00:00, 7.64it/s, train_loss=0.1023, train_acc=0.9688, lr=9.2e-5]
开始验证!
Epoch 1/10: 100%|██████████████████| 22/22 [00:01<00:00, 17.22it/s, val_loss=0.0022, val_acc=1.0000]
结束验证!
验证loss为:0.0730
验证准确率为:0.9673
Epoch 2/10: 100%|██| 86/86 [00:11<00:00, 7.80it/s, train_loss=0.0050, train_acc=1.0000, lr=8.46e-5]
开始验证!
Epoch 2/10: 100%|██████████████████| 22/22 [00:01<00:00, 18.04it/s, val_loss=0.1671, val_acc=0.8750]
结束验证!
验证loss为:0.0382
验证准确率为:0.9830
Epoch 3/10: 100%|██| 86/86 [00:11<00:00, 7.80it/s, train_loss=0.0034, train_acc=1.0000, lr=7.79e-5]
开始验证!
Epoch 3/10: 100%|██████████████████| 22/22 [00:01<00:00, 16.95it/s, val_loss=0.6676, val_acc=0.8750]
结束验证!
验证loss为:0.0675
验证准确率为:0.9801
Epoch 4/10: 100%|██| 86/86 [00:11<00:00, 7.79it/s, train_loss=0.0008, train_acc=1.0000, lr=7.16e-5]
开始验证!
Epoch 4/10: 100%|██████████████████| 22/22 [00:01<00:00, 18.16it/s, val_loss=0.4470, val_acc=0.8750]
结束验证!
验证loss为:0.0327
验证准确率为:0.9901
Epoch 5/10: 100%|██| 86/86 [00:11<00:00, 7.80it/s, train_loss=0.0001, train_acc=1.0000, lr=6.59e-5]
开始验证!
Epoch 5/10: 100%|██████████████████| 22/22 [00:01<00:00, 17.79it/s, val_loss=0.0001, val_acc=1.0000]
结束验证!
验证loss为:0.0127
验证准确率为:0.9972
Epoch 6/10: 100%|██| 86/86 [00:10<00:00, 7.87it/s, train_loss=0.0007, train_acc=1.0000, lr=6.06e-5]
开始验证!
Epoch 6/10: 100%|██████████████████| 22/22 [00:01<00:00, 17.76it/s, val_loss=0.0000, val_acc=1.0000]
结束验证!
验证loss为:0.0211
验证准确率为:0.9972
Epoch 7/10: 100%|██| 86/86 [00:10<00:00, 7.86it/s, train_loss=0.0000, train_acc=1.0000, lr=5.58e-5]
开始验证!
Epoch 7/10: 100%|██████████████████| 22/22 [00:01<00:00, 17.68it/s, val_loss=0.0002, val_acc=1.0000]
结束验证!
验证loss为:0.0187
验证准确率为:0.9986
Epoch 8/10: 100%|██| 86/86 [00:10<00:00, 7.86it/s, train_loss=0.0000, train_acc=1.0000, lr=5.13e-5]
开始验证!
Epoch 8/10: 100%|██████████████████| 22/22 [00:01<00:00, 17.66it/s, val_loss=0.0002, val_acc=1.0000]
结束验证!
验证loss为:0.0182
验证准确率为:0.9986
Epoch 9/10: 100%|██| 86/86 [00:11<00:00, 7.76it/s, train_loss=0.0000, train_acc=1.0000, lr=4.72e-5]
开始验证!
Epoch 9/10: 100%|██████████████████| 22/22 [00:01<00:00, 17.53it/s, val_loss=0.0002, val_acc=1.0000]
结束验证!
验证loss为:0.0186
验证准确率为:0.9986
Epoch 10/10: 100%|█| 86/86 [00:11<00:00, 7.80it/s, train_loss=0.0001, train_acc=1.0000, lr=4.34e-5]
开始验证!
Epoch 10/10: 100%|█████████████████| 22/22 [00:01<00:00, 16.99it/s, val_loss=0.0002, val_acc=1.0000]
结束验证!
验证loss为:0.0186
验证准确率为:0.9986
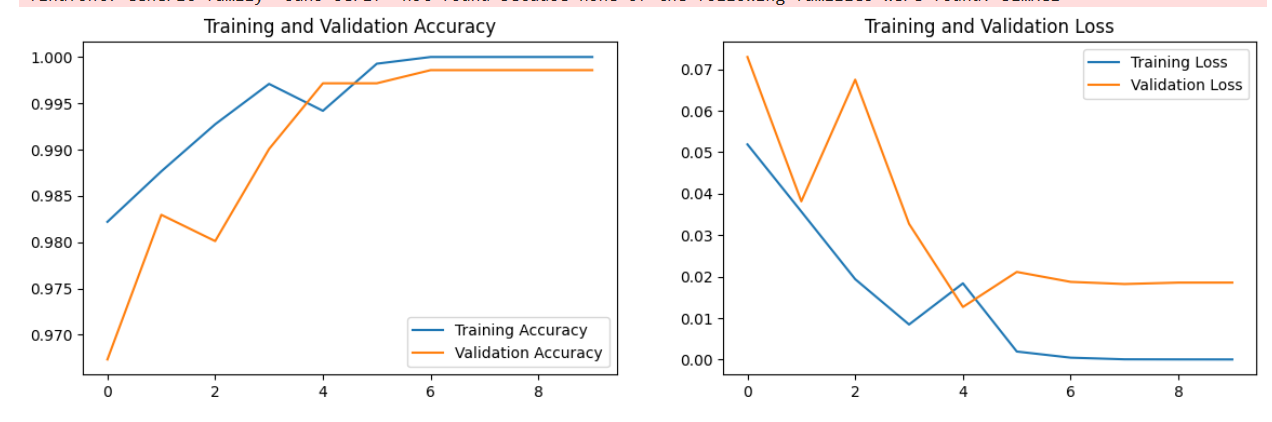
六、模型评估
epochs_range = range(epochs)
plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, history_train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, history_val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, history_train_loss, label='Training Loss')
plt.plot(epochs_range, history_val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
输出
七、预测
import numpy as np
plt.figure(figsize=(18, 3)) # 图形的宽为18高为5
plt.suptitle("预测结果展示")
for images, labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(1,8, i + 1)
plt.imshow(images[i].numpy())
img_array = tf.expand_dims(images[i], 0)
predictions = model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")
输出
















 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









