






R语言缺失值
有的情况下,数据集里面有的数据值是不知道的,unknown values。对于数据分析来说,一个常见的功能就是缺失值的处理。R语言用NA表示缺失值,not available的意思。
1. 缺失值例子
数据文件:
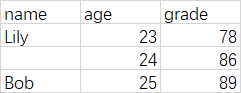
读入R:
> df
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
2. 如何判断缺失值
2.1 is.na
R语言里面用is.na函数来判断是否是缺失值。is.na会判断每一个值是否缺失。
> is.na(df)
name age grade
1 FALSE FALSE FALSE
2 TRUE FALSE FALSE
3 FALSE FALSE FALSE
2.2 complete.cases
complete.case是判断哪一行有缺失值。可以判断vector, data.frame, matrix。
> df
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
> complete.cases(df)
[1] TRUE FALSE TRUE
3. 设定特定值为缺失值
我们将上面的数据新加一行。我们的grade值的范围是0~100,对于超过100或者小于0的值,我们可以指定为缺失值。
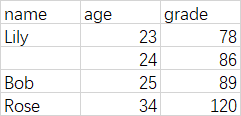
> df <- read.xlsx("data.xlsx",sheet=1)
> df
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
4 Rose 34 120
> df$grade[df$grade > 100] <- NA
> df
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
4 Rose 34 NA
4. 如何处理缺失值
缺失值的处理一般有两种方式:(1)删除缺失值所在的行数据;(2)修改缺失值为某一值。
4.1
R提供了一些基本的functions或者叫actions来处理NA值。在modeling过程中,或者其他functions中,可以指定na.action来处理数据中的NA值。
na.fail(object, ...),指定这个action,如果数据里面有NA值,会报错。如果没有,会返回原来的数据值。
na.omit(object, ...), 会删除所有缺失值,对data.frame,就是删掉所有有缺失值的行。
> df
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
4 Rose 34 NA
> na.omit(df)
name age grade
1 Lily 23 78
3 Bob 25 89
na.exclude(object, ...)
na.pass(object, ...),会返回数据,什么都不处理。
> df
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
4 Rose 34 NA
> na.pass(df)
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
4 Rose 34 NA
4.2 用特定值替换NA值
还有一种处理方式就是用特定值替换NA值。对于下面这个数据,可以用均值替换grade的NA值。
> df
name age grade
1 Lily 23 78
2 <NA> 24 86
3 Bob 25 89
4 Rose 34 NA
> mean(df$grade, na.rm=TRUE)
[1] 84.33333
> df$grade[is.na(df$grade)] <- mean(df$grade, na.rm=TRUE)
> df
name age grade
1 Lily 23 78.00000
2 <NA> 24 86.00000
3 Bob 25 89.00000
4 Rose 34 84.33333















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









