







Motivation:
现有的生成式对话摘要方法往往需要引入一些辅助信息,比如key words, dialog act,topic等等,来提高生成的摘要的信息性,相关性,减少摘要的冗余性。这些辅助信息的引入往往依赖于一些开源的工具,这些工具可能本身并不是针对于对话的,不能很好适应对话的特点,或者需要大量的手工标注。本文将DialogGpt改造成无监督的dialogue annotator,自动完成三种标记任务,Keywords Extraction,Redundancy
Detection,Topic Segmentation,下图给出了这三种任务的示例,keywords extraction是提取出对话中的关键词,redundancy detection的目标是发现冗余的语句,也就是对于对话的总体意思没有太大贡献的句子,Topic Segmentation的目标是根据topic将对话分成连续的若干段。用DialoGPT annotator对SAMSUM和AMI数据集进行标记,然后再用BART模型和PGN模型生成摘要。

Method
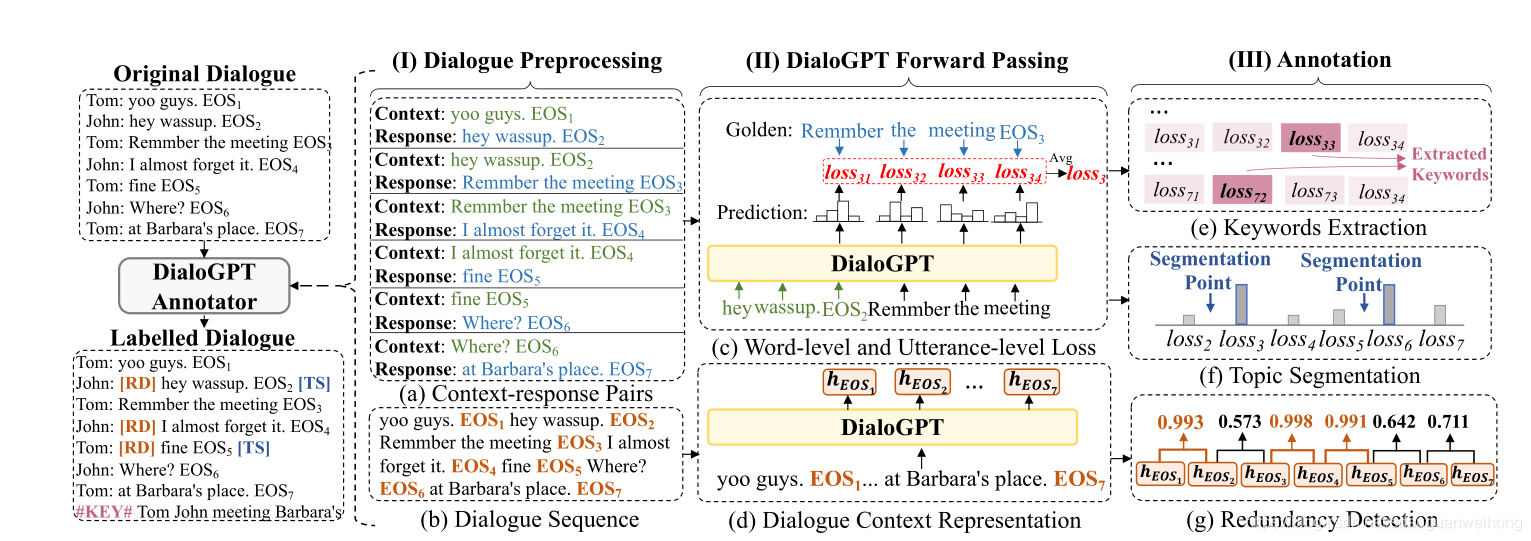
上图给出了DialoGPT annotator的总体架构:
Dialogue Preprocessing
首先将对原始的对话进行预处理,得到两种形式的输入,一种是context-response对,另一种是dialogue sequence ,将所有utterance拼接在一起,使用EOS分割。
DialoGPT Forward Passing
然后将预处理后的对话输入到DialoGPT中,进行forward pass。对于每对context-response,得到每个word的loss l o s s i , t loss_{i,t} lossi,t和每个utterance的loss l o s s t loss_t losst。对于每个dialogue sequence,得到对话的上下文表示 h E O S 1 , h E O S 2 , h E O S 3 , . . h E O S D = H ( E O S ) h_{EOS1},h_{EOS2},h_{EOS3},..h_{EOSD}=H(EOS) hEOS1,hEOS2,hEOS3,..hEOSD=H(EOS)
Annotation
利用Forward Pass的结果进行Annotation,包含三项任务,Keywords Extraction,Redundancy Detection,Topic Segmentation。
Keywords Extraction
作者认为keywords是unpredictable的词汇,如果golden response中的一个词很难被DialoGPT预测出来,这个词很可能包含了更多的信息,因此可以被视为key word。
在上一步得到了每个word
u
i
,
j
u_{i,j}
ui,j的loss
l
o
s
s
i
,
j
loss_{i,j}
lossi,j,从对话中提取出loss最大的
r
k
e
r_{ke}
rke比例的词作为key words,同时把所有的speaker的名字P也加入key words中,并添加一个特殊标记
#
K
E
Y
\#KEY
#KEY,最后得到标记后的dialogue为
D
K
E
=
[
p
1
,
u
1
,
1
,
…
,
#
K
E
Y
#
,
P
,
Key
1
,
K
e
y
2
,
…
⏟
]
\mathcal{D}_{\mathrm{KE}}=[p_{1}, u_{1,1}, \ldots, \underbrace{\# \mathrm{KEY} \#, \mathbb{P}, \operatorname{Key}_{1}, \mathrm{Key}_{2}, \ldots}]
DKE=[p1,u1,1,…,
#KEY#,P,Key1,Key2,…]
Redundancy Detection
每个
h
E
O
S
i
h_{EOSi}
hEOSi可以看做是对话上下文
[
u
1
,
u
2...
u
i
]
[u1,u2...u_i]
[u1,u2...ui]的表示,当添加一个新的utterance
u
i
+
1
u_{i+1}
ui+1,如果新的
h
E
O
S
i
+
1
h_{EOSi+1}
hEOSi+1和前一个
h
E
O
S
I
h_{EOSI}
hEOSI相似,就可以认为
u
i
+
1
u_{i+1}
ui+1带来较少的信息,从而将
u
i
+
1
u_{i+1}
ui+1看做冗余。
从最后两个对话上下文的表示
h
E
O
S
∣
D
∣
h_{EOS|D|}
hEOS∣D∣和
h
E
O
S
∣
D
−
1
∣
h_{EOS|D-1|}
hEOS∣D−1∣开始,计算之间的相似度,如果相似度得分超过预设的阈值,
u
D
u_{D}
uD就是一个冗余,如果没有超过阈值,就继续计算前两个句子的相似度重复这一过程直到开头。
在每个荣誉的句子之前添加一个特殊标志
[
R
D
]
[RD]
[RD],最后得到标记后的对话为
D
R
D
=
[
p
1
,
[
R
D
]
,
u
1
,
1
,
…
,
EOS
1
,
…
,
p
∣
D
∣
,
…
,
EOS
∣
D
∣
]
D_{RD}=\left[p_{1},[\mathrm{RD}], u_{1,1}, \ldots, \operatorname{EOS}_{1}, \ldots, p_{|\mathcal{D}|}, \ldots, \text { EOS }_{|\mathcal{D}|}\right]
DRD=[p1,[RD],u1,1,…,EOS1,…,p∣D∣,…, EOS ∣D∣]
Topic Segmentation
DialoGPT擅长生成上下文一致的对话,所以如果一句回复很难被DialoGPT预测,就认为这句回复属于另一个话题,在这里添加一个分隔。
在上一步得到了每个utterance的loss
l
o
s
s
i
loss_i
lossi,选择loss最大的前
r
T
S
r_{TS}
rTS比例的utterances作为话题分割的断点,在每个选择的句子之前添加一个特殊标志
[
T
S
]
[TS]
[TS],最后得到标记后的对话为
D
T
S
=
[
p
1
,
[
T
S
]
,
u
1
,
1
,
…
,
EOS
1
,
…
,
p
∣
D
∣
,
…
,
EOS
∣
D
∣
]
D_{TS}=\left[p_{1},[\mathrm{TS}], u_{1,1}, \ldots, \operatorname{EOS}_{1}, \ldots, p_{|\mathcal{D}|}, \ldots, \text { EOS }_{|\mathcal{D}|}\right]
DTS=[p1,[TS],u1,1,…,EOS1,…,p∣D∣,…, EOS ∣D∣]
Summarizer
使用BART模型和pointer-generator模型生成最终的摘要,在此不做太多介绍。

















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









