








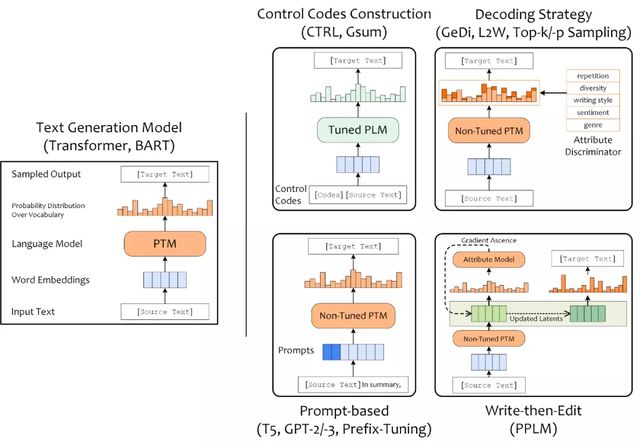
可控文本生成技术大图
一 文本生成技术
文本生成(Text Generation)是自然语言处理(Natural Language Processing,NLP)领域的一项重要且具有挑战的任务。顾名思义,文本生成任务的目的是生成近似于自然语言的文本序列,但仍可以根据输入数据进行分类。比如输入结构化数据的 Data-to-text Generation,输入图片的 Image Caption,输入视频的 Video Summarization,输入音频的 Speech Recognition 等。本文我们聚焦于输入文本生成文本的 Text-to-Text 任务,具体地包括神经机器翻译、智能问答、生成式文本摘要等。
随着深度学习的发展,众多新兴的技术已被文本生成任务所采用。比如,为了解决文本生成中的长期依赖、超纲词(Out-of-Vocabulary,OOV)问题,注意力机制(Attention Mechanism),拷贝机制(Copy Mechanism)等应运而出;网络结构上使用了循环神经网络(Recurrent Neural Networks),卷积神经网络(Convolutional Neural Networks),图神经网络(Graph Neural Networks),Transformer 等。为了顺应“预训练-精调”范式的兴起,在海量语料上自监督地训练出的大体量预训练语言模型(Pre-trained Language Model;PLM),也被广泛应用在文本生成任务中。
为了展示上述结构、模型、机制在文本生成任务上的应用,本章第一小节会简要梳理主流文本生成模型的结构,在第二小节会对于文本生成的评价指标的方案进行归纳。
1 文本生成模型的结构
文本生成模型的结构常来自于人类撰写文本的启发。此处按照模型结构的特征,将主流文本生成模型分为如下几种:
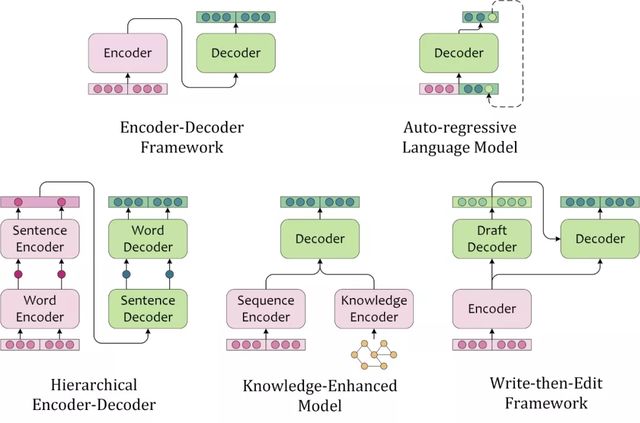
图1:各种文本生成模型结构图示
Encoder-Decoder Framework
“编码器-解码器框架”首先使用 encoder 编码文本,再使用 decoder 基于原文编码和部分解码输出,自回归地解码(Autoregressively Decoding)出文本。这类似于,人类首先理解素材(源文本、图片、视频等),然后基于对原文的理解和已写出的内容,逐字地撰写出文本。也是目前序列到序列任务中应用最广泛的框架结构。
Auto-regressive Language Model
标准的 left-to-right 的单向语言模型,也可以根据前文序列逐字地解码出文本序列,这种依赖于前文语境来建模未来状态的解码过程,叫做自回归解码(Auto-regressive Decoding)。不同于编码器-解码器框架”使用 encoder 编码源文本,用 decoder 编码已预测的部分序列,AR LM 用同一个模型编码源文本和已解码的部分序列。
Hierarchical Encoder-Decoder
对于文本素材,人类会先理解单个句子,再理解整篇文本。在撰写文本的过程中,也需要先构思句子的大概方向,再逐字地撰写出内容。这类模型往往需要一个层次编码器对源文本进行 intra-sentence 和 inter-sentence 的编码,对应地进行层次 sentence-level 和 token-level 的解码。在 RNN 时代,层次模型分别建模来局部和全局有不同粒度的信息,往往能够带来性能提升,而 Transformer 和预训练语言模型的时代,全连接的 Self-Attention 弱化了这种优势。
Knowledge-Enriched Model
知识增强的文本生成模型,引入了外部知识,因此除了针对源文本的文本编码器外,往往还需要针对外部知识的知识编码器。知识编码器的选择可以依据外部知识的数据结构,引入知识图谱、图片、文本作为外部知识时可以对应地选用图神经网络、卷积神经网络、预训练语言模型等。融合源文本编码与知识编码时,也可以考虑注意力机制,指针生成器网络(Pointer-Generator-Network),记忆网络(Memory Networks)等。
Write-then-Edit Framework
考虑到人工撰写稿件尚不能一次成文,那么文本生成可能同样需要有“修订”的过程。人工修订稿件时,需要基于原始素材和草稿撰写终稿,模型也需要根据源文本和解码出的草稿重新进行编解码。这种考虑了原文和草稿的模型能够产生更加合理的文本内容。当然也会增加计算需求,同时生成效率也会打折扣。
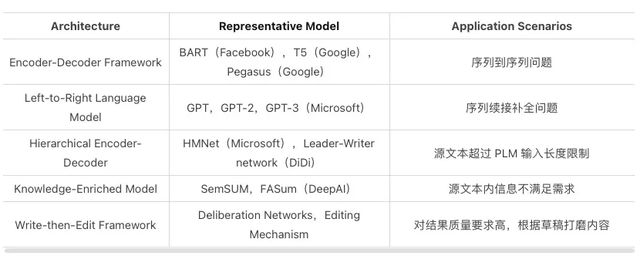
表1:各种文本生成模型结构及其代表性模型
2 文本生成的评价指标
针对文本生成的评价指标,已有多年研究。根据不同的维度,可以对现有评价指标有着不同的分类。比如,部分评价指标仅考虑所生成的文本,来衡量其自身的流畅度、重复性、多样性等;另一部分指标还考虑到了源文本或目标文本,来考察所生成的文本与它们之间的相关性、忠实度、蕴含关系等。
此处,我们从执行评价的主体类型进行分类,来梳理当前常用的文本生成的评价指标:
Human-centric evaluation metrics
文本生成的目标是获得人类能够理解的自然语言。因此,邀请专家或受训练的标注者来对生成内容进行评价,或者比较多个模型的输出文本,是最直观的评价方式。人工评价在机器难以判别的角度也能发挥作用,比如:衡量生成文本句间的连贯性(Coherence),衡量生成文本近似于自然语言程度的通顺度(Fluency),衡量生成文本中的内容是否忠实于原文的事实正确度(Factuality),以及风格、格式、语调、冗余等。此外,为了衡量人工打标的可靠性,可以让多个标注者对进行同一样本打标,并使用 IAA(Inter-Annotator Agreement)来对人工评价结果进行评估。常用的是 Fleiss' ,以及 Krippendorff's 。
Unsupervised automatic metrics
基于规则统计的无监督自动指标,能够适应大体量测试集上的文本评价。最常见的就是 ROUGE-N(Recall-Oriented Understudy for Gisting Evaluation)和 BLEU-N(BiLingual Evaluation Understudy),这两个指标考虑了 N-gram overlapping 的召回率和精确率,能够衡量文本的通顺度及与源文本的字面一致性。通常,为了衡量文本用词的多样性,Distinct-N 计算仅出现过一次的 N-gram 占生成文本中总 N-gram 个数的百分比。
Machine-learned automatic metrics
为了衡量输出文本在语义上的属性,常需要用训练好的判别模型。比如,为了建模目标序列与预测序列之间的相似度,可以使用 BERTScore 先利用 BERT 给出两个文本序列的语境化向量表征,再进行相似度矩阵的计算;GeDi 中使用 RoBERTa 训练出一个 Toxicity Classifier 来判别模型生成的文本是否包含恶意中伤的内容;自然语言推理任务中的文本蕴含(Textual Entailment)模型也可以用于衡量生成的摘要与原文之间在内容上的忠实程度。
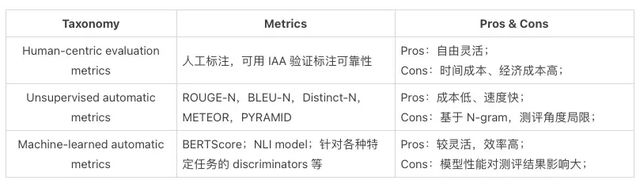
表2:各种测评指标的性能优劣势
从上表我们可以看出,人工评价指标虽然灵活,不适合用于对海量样本评价。而无监督的自动评价指标,虽然能低成本地解决评测问题,但能够完成评价的角度甚少。“用模型来衡量模型”则是效率和灵活性之间的 trade-off。
但前提要保证判别模型本身的性能,才能保证测评结果的可靠性。Amazon 的工作证明开箱即用的 NLI 模型并不能保证内容忠实度评测的良好效果,由此看来,该类型的评价指标仍需要向 task-specific 和 data-specific 的方向上深挖,来弥合训练域与应用域之间的鸿沟。
二 可控文本生成
可控文本生成的目标,是控制给定模型基于源文本产生特定属性的文本。特定属性包括文本的风格、主题、情感、格式、语法、长度等。根据源文本生成目标序列的文本生成任务,可以建模为P(Target|Sourse);而考虑了控制信号的可控文本生成任务,则可以建模为P(Target|Sourse,ControlSignal)。
目前可控文本生成已有大量的相关研究,比较有趣的研究有,SongNet(Tencent)控制输出诗词歌赋的字数、平仄和押韵;StylePTB(CMU)按照控制信号改变句子的语法结构、单词形式、语义等;CTRL(Salesforce)在预训练阶段加入了 control codes 与 prompts 作为控制信号,影响文本的领域、主题、实体和风格。可控文本生成模型等方案也多种多样,此处按照进行可控的着手点和切入角度,将可控文本生成方案分为:构造 Control Codes、设计 Pro
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









