







近年来,文本的数量呈指数增长,为了能在许多应用中准确地对文本进行分类,需要对机器学习方法有更深入的了解。许多机器学习方法在自然语言处理方面都取得了突破性的结果。这些学习算法的成功取决于其拟合数据中存在的非线性关系的能力。然而,寻找一种普适、通用的文本分类技术对研究人员来说仍然是一个巨大的挑战。
在文本分类专栏系列博客中,我将系统的介绍如何搭建一个完整的文本分类系统,包括数据预处理、主要方法的原理介绍和实现细节、实验结果与分析、网页Demo的构建以及项目文件的组织方式。
目录
1. 问题定义
在过去的几十年中,文本分类问题在许多实际应用中得到了广泛的研究和解决。 文本分类技术在信息检索、信息过滤、推荐系统、情感分析以及推荐系统等多个领域都有广泛的应用。文本分类任务是指根据已经定义好的类别标签对现有的一段文本进行标注的任务。一般来说,文本数据集包含一系列长短不一的文本片段,如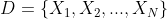 ,其中
,其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









